A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-A1CD8D57-3C47-4360-9683-67A9F56D3549
Visible to Intel only — GUID: GUID-A1CD8D57-3C47-4360-9683-67A9F56D3549
Anomaly Detection Analysis (preview)
Use Anomaly Detection to identify performance anomalies in frequently recurring intervals of code like loop iterations. Perform fine-grained analysis at the microsecond and nanosecond level.
Application performance can occasionally be hampered by the presence of performance anomalies. A performance anomaly is any short-lived, sporadic issue that causes unrecoverable consequences. These issues may not be statistically discernible but they create a poor user experience and can be very expensive to fix. When the performance of your application requires varying amounts of work for instances of the same task or when it displays variations in a single/few iterations of a loop, these are symptoms of anomalous behavior in your application.
Use Anomaly Detection analysis to identify performance anomalies in your application that are otherwise difficult to isolate. This analysis type uses Intel® Processor Trace (Intel® PT) technology to perform trace data collection and fine-grained time and event measurement. Intel® PT is an extension of Intel® Architecture that captures information about software execution using dedicated hardware. The hardware causes only minimal performance perturbation to the software being traced.
This is a PREVIEW FEATURE. A preview feature may or may not appear in a future production release. It is available for your use in the hopes that you will provide feedback on its usefulness and help determine its future. Data collected with a preview feature is not guaranteed to be backward compatible with future releases.
The control flow trace feature in Intel® PT generates a variety of packets that, when combined with the binaries of a program by a post-processing tool, can be used to produce an exact execution trace. The packets record flow information such as instruction pointers (IP), indirect branch targets, and directions of conditional branches within contiguous code regions (basic blocks). For descriptions of key concepts in Intel® PT, see Chapter 35 of the Intel Software Developer's Manual (Volume 3C):System Programming Guide.
To detect software performance anomalies using VTune Profiler, you use the Instrumentation and Tracing Technology (ITT) API to designate specific code regions of interest and then run Anomaly Detection analysis.
Common Performance Anomalies
These are typical examples of performance anomalies in a software application.
- Financial transactions that take an unusually long time to process.
- Glitches in the UI of a video game like slow or skipped video frames.
- Packet losses in large applications that have SPDK/DPDK loops.
- High frequency applications where processing speed is critical and some iterations run slower than others.
Run Anomaly Detection in one of these situations where observed application behavior deviates from expected behavior in some iterations.
Causes for Performance Anomaly
Change in control flow: Different instances of the same task require different amounts of work.
Uncommon observations: Expensive handling of errors or memory/storage reallocation.
Context switches: Synchronization or preemption.
Unexpected kernel activity: Interrupts or page faults.
Micro-architectural issues: Cache misses or incorrect branch predictions.
Frequency drops: Low CPU utilization, cooling issues, or the inclusion of Intel® Advanced Vector Extensions (Intel® AVX) instructions in the code.
The Anomaly Detection Analysis Workflow
When you observe anomalies in your application performance, use Anomaly Detection for a detailed investigation.
- Prepare your application for analysis.
- Define parameters that break your code into smaller regions of interest. Decide how long you want to simulate each region.
- Run Anomaly Detection.
- Review anomalies in detail:
- Load trace data for the processor for each anomaly in the Bottom-up view to examine code regions of interest.
- Open trace data to see frequency information for a specific region.
- Examine source and assembly views to see the number of loop iterations.
Configure and Run Analysis
Prepare your Application
Large applications can generate huge volumes of data through a profiling run. This in turn can cause significant delay in processing results. You may only want to focus on anomalies in a particular operation in your code. Mark this section by defining it as a Code Region of Interest. Use the ITT API for this purpose.
Register the name of the code region you plan to profile:
__itt_pt_region region = __itt_pt_region_create("region");Mark the target loop in your application with this name:
for(…;…;…) { __itt_mark_pt_region_begin(region); <code processing your task> __itt_mark_pt_region_end(region); }
Run the Analysis
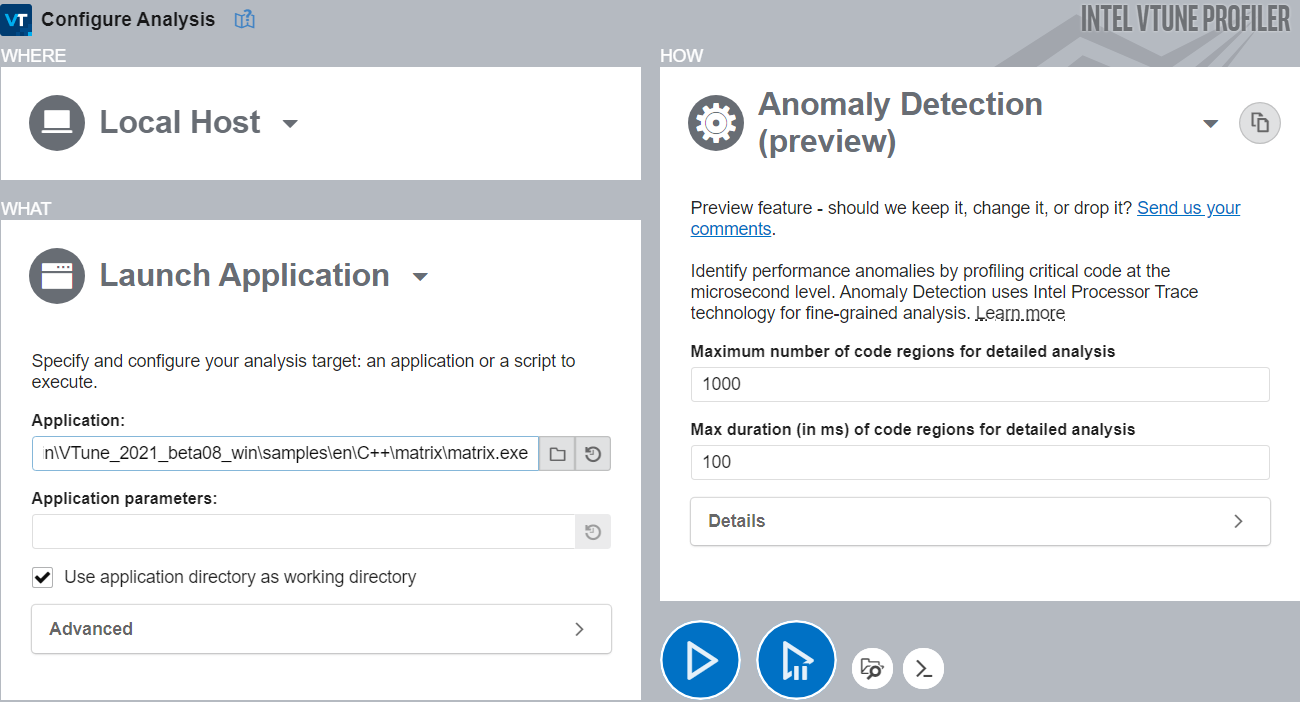
On the Welcome screen, click Configure Analysis.
In the Analysis Tree, select the Anomaly Detection analysis type in the Algorithm group.
In the WHAT pane, specify your application and any relevant application parameters.
In the HOW pane, specify parameters for the analysis.
Parameter
Description
Range
Recommended Value
Maximum number of code regions for detailed analysis Specify number of code regions for your application.
10-5000
For faster loading of details, pick a value not more than1000.
Maximum duration of analysis per code region Specify the duration of analysis time (ms) to be spent on each code region.
0.001-1000
Any value under 1000 ms.
Click the
 Start button to run the analysis.
Start button to run the analysis.
To run Anomaly Detection from the command line, use the  Command Line button at the bottom.
Command Line button at the bottom.
View Data
Once the analysis is complete, VTune Profiler displays results in the Summary window.
Elapsed Time indicates the total time spent on all code regions of interest.
Code Region of Interest Duration Histogram plots the number of instances of performance-critical tasks against specified duration (or latency). See specific code regions in the Fast and Slow regions to understand why the duration changed.
Collection and Platform Info displays relevant details about the system, data about the collection platform, and the resulting set size.
The above procedure is useful when you process analysis results on the same system where you collected data. If you want to transfer the collected data onto a different system before you view it, run the archive command after data collection to copy essential binaries to the results folder. You must complete this step before transferring results to the new system to load collection details without problems.
To run the archive command:
Collect results as described above.
At the command line, type:
vtune.exe --archive -r r001ad
where r001ad is an example of an analysis result.
To view collected data on a different system, you must copy all binaries including system and compiler runtime binaries that are linked to your main binary and were accessed during the collection. The archive command is useful for this purpose since it is not easy to copy these binaries manually.
Next Steps
See the Anomaly Detection view for information on interpreting collected data in these ways:
Load trace details for each analysis in the Bottom-up window.
Look for unexpected kernel activity. See if applications entered certain kernels that should not have been activated during the analysis.
Use the source and assembly views to compare code regions of interest in fast and slow regions of the histogram.