Intel® FPGA SDK for OpenCL™ Standard Edition: Best Practices Guide
2.8.3. Local Memory
Local memory is a complex system. Unlike typical GPU architecture where there are different levels of caches, FPGA implements local memory in dedicated memory blocks inside the FPGA.
Local Memory Characteristics
- Ports—Each bank of local memory has one write port and one read port that your design can access simultaneously.
- Double pumping—The double-pumping feature allows each local memory bank to support up to three read ports. Refer to the Double Pumping section for more information.
Local memory is a complex system. Unlike typical GPU architecture where there are different levels of caches, FPGA implements local memory in dedicated memory blocks inside the FPGA.
In your kernel code, declare local memory as a variable with type local:
local int lmem[1024];The customizes the local memory properties such as width, depth, banks, replication, and interconnect. The offline compiler analyzes the access pattern based on your code and then optimizes the local memory to minimize access contention.
The diagrams below illustrate these basic local memory properties: size, width, depth, banks, and replication.
In the HTML report, the overall state of the local memory is reported as optimal, good but replicated, and potentially inefficient.
The key to designing a highly efficient kernel is to have memory accesses that never stall. In this case, all possible concurrent memory access sites in the data path are guaranteed to access memory without contention.
In a complex kernel, the offline compiler might not have enough information to infer whether a memory access has any conflict. As a result, the offline compiler infers a local memory load-store unit (LSU) to arbitrate the memory access. However, inferring an LSU might cause inefficiencies. Refer to Local Memory LSU for more information.
The offline compiler does not always implement local memory with the exact size that you specified. Since FPGA RAM blocks have specific dimensions, the offline compiler implements a local memory size that rounds up to the next supported RAM block dimension. Refer to device-specific information for more details on RAM blocks.
Local Memory Banks
Local memory banking only works on the lowest dimension by default. Having multiple banks allows simultaneous writes to take place. The figure below illustrates the implementation of the following local variable declaration:
local int lmem[1024][4];Each local memory access in a loop has a separate address. In the following code example, the offline compiler can infer lmem to create four separate banks. The loop allows four simultaneous accesses to lmem[][], which achieves the optimal configuration.
kernel void bank_arb_consecutive_multidim (global int* restrict in,
global int* restrict out) {
local int lmem[1024][BANK_SIZE];
int gi = get_global_id(0);
int gs = get_global_size(0);
int li = get_local_id(0);
int ls = get_local_size(0);
int res = in[gi];
#pragma unroll
for (int i = 0; i < BANK_SIZE; i++) {
lmem[((li+i) & 0x7f)][i] = res + i;
res >> 1;
}
int rdata = 0;
barrier(CLK_GLOBAL_MEM_FENCE);
#pragma unroll
for (int i = 0; i < BANK_SIZE; i++) {
rdata ^= lmem[((li+i) & 0x7f)][i];
}
out[gi] = rdata;
return;
}local int a[4][128] __attribute__((bank_bits(8,7),bankwidth(4)));#define BANK_SIZE 4
kernel void bank_arb_consecutive_multidim_origin (global int* restrict in,
global int* restrict out) {
local int a[BANK_SIZE][128] __attribute__((bank_bits(8,7),bankwidth(4)));
int gi = get_global_id(0);
int li = get_local_id(0);
int res = in[gi];
#pragma unroll
for (int i = 0; i < BANK_SIZE; i++) {
a[i][((li+i) & 0x7f)] = res + i;
res >> 1;
}
int rdata = 0;
barrier(CLK_GLOBAL_MEM_FENCE);
#pragma unroll
for (int i = 0; i < BANK_SIZE; i++) {
rdata ^= a[i][((li+i) & 0x7f)];
}
out[gi] = rdata;
return;
}The view of the resulting memory is the same as the initial view from the first example. However, if you specify the wrong bits to bank on, the memory arbitration logic changes.
local int a[4][128] __attribute__((bank_bits(4,3),bankwidth(4)));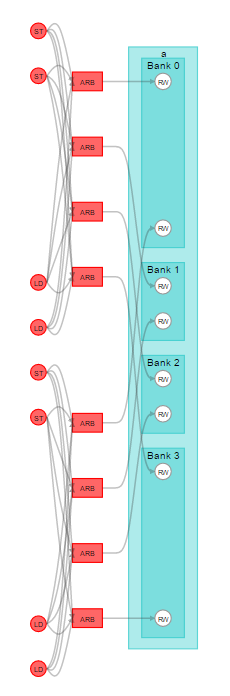
If the compiler cannot infer the local memory accesses to separate addresses, it uses a local memory interconnect to arbitrate the accesses, which degrades performance.
Local Memory Replication
Local memory replication allows for simultaneous read operations to occur. The offline compiler optimizes your design for efficient local memory access in order to maximize overall performance. Although memory replication leads to inefficient hardware in some cases, memory replication does not always increase RAM usage.
When the offline compiler recognizes that more than two work groups are reading from local memory simultaneously, it replicates the local memory. If local memory replication increases your design area significantly, consider reducing the number of barriers in the kernel or increasing the max_work_group_size value to help reduce the replication factor.
Double Pumping
By default, each local memory bank has one read port and one write port. The double pumping feature allows each local memory bank to support up to three read ports.
The underlying mechanism that enables double pumping is in the M20K hardware. During the first clock cycle, the M20K block is double clocked. Then, during the second clock cycle, the ports are multiplexed to create two more read ports.
By enabling the double pumping feature, the offline compiler trades off area versus maximum frequency. The offline compiler uses heuristic algorithms to determine the optimal memory configurations.
Advantages of double pumping:
- Increases from one read port to three read ports
- Saves RAM usage
Disadvantages of double pumping:
- Implements additional logic
- Might reduce maximum frequency
The following code example illustrates the implementation of local memory with eight read ports and one write port. The offline compiler enables double pumping and replicates the local memory three times to implement a memory configuration that can support up to nine read ports.
#define NUM_WRITES 1
#define NUM_READS 8
#define NUM_BARRIERS 1
local int lmem[1024];
int li = get_local_id(0);
int res = in[gi];
#pragma unroll
for (int i = 0; i < NUM_WRITES; i++) {
lmem[li - i] = res;
res >>= 1;
}
// successive barriers are not optimized away
#pragma unroll
for (int i = 0; i < NUM_BARRIERS; i++) {
barrier(CLK_GLOBAL_MEM_FENCE);
}
res = 0;
#pragma unroll
for (int i = 0; i < NUM_READS; i++) {
res ^= lmem[li - i];
}