Intel® FPGA SDK for OpenCL™ Standard Edition: Best Practices Guide
ID
683176
Date
9/24/2018
Public
1. Introduction to Standard Edition Best Practices Guide
2. Reviewing Your Kernel's report.html File
3. OpenCL Kernel Design Best Practices
4. Profiling Your Kernel to Identify Performance Bottlenecks
5. Strategies for Improving Single Work-Item Kernel Performance
6. Strategies for Improving NDRange Kernel Data Processing Efficiency
7. Strategies for Improving Memory Access Efficiency
8. Strategies for Optimizing FPGA Area Usage
A. Additional Information
2.1. High Level Design Report Layout
2.2. Reviewing the Report Summary
2.3. Reviewing Loop Information
2.4. Reviewing Area Information
2.5. Verifying Information on Memory Replication and Stalls
2.6. Optimizing an OpenCL Design Example Based on Information in the HTML Report
2.7. HTML Report: Area Report Messages
2.8. HTML Report: Kernel Design Concepts
3.1. Transferring Data Via Channels or OpenCL Pipes
3.2. Unrolling Loops
3.3. Optimizing Floating-Point Operations
3.4. Allocating Aligned Memory
3.5. Aligning a Struct with or without Padding
3.6. Maintaining Similar Structures for Vector Type Elements
3.7. Avoiding Pointer Aliasing
3.8. Avoid Expensive Functions
3.9. Avoiding Work-Item ID-Dependent Backward Branching
4.3.4.1. High Stall Percentage
4.3.4.2. Low Occupancy Percentage
4.3.4.3. Low Bandwidth Efficiency
4.3.4.4. High Stall and High Occupancy Percentages
4.3.4.5. No Stalls, Low Occupancy Percentage, and Low Bandwidth Efficiency
4.3.4.6. No Stalls, High Occupancy Percentage, and Low Bandwidth Efficiency
4.3.4.7. Stalling Channels
4.3.4.8. High Stall and Low Occupancy Percentages
7.1. General Guidelines on Optimizing Memory Accesses
7.2. Optimize Global Memory Accesses
7.3. Performing Kernel Computations Using Constant, Local or Private Memory
7.4. Improving Kernel Performance by Banking the Local Memory
7.5. Optimizing Accesses to Local Memory by Controlling the Memory Replication Factor
7.6. Minimizing the Memory Dependencies for Loop Pipelining
4.2.1. Source Code Tab
The Source Code tab in the GUI contains source code information and detailed statistics about memory and channel accesses.
Figure 63. The Source Code tab in the GUI
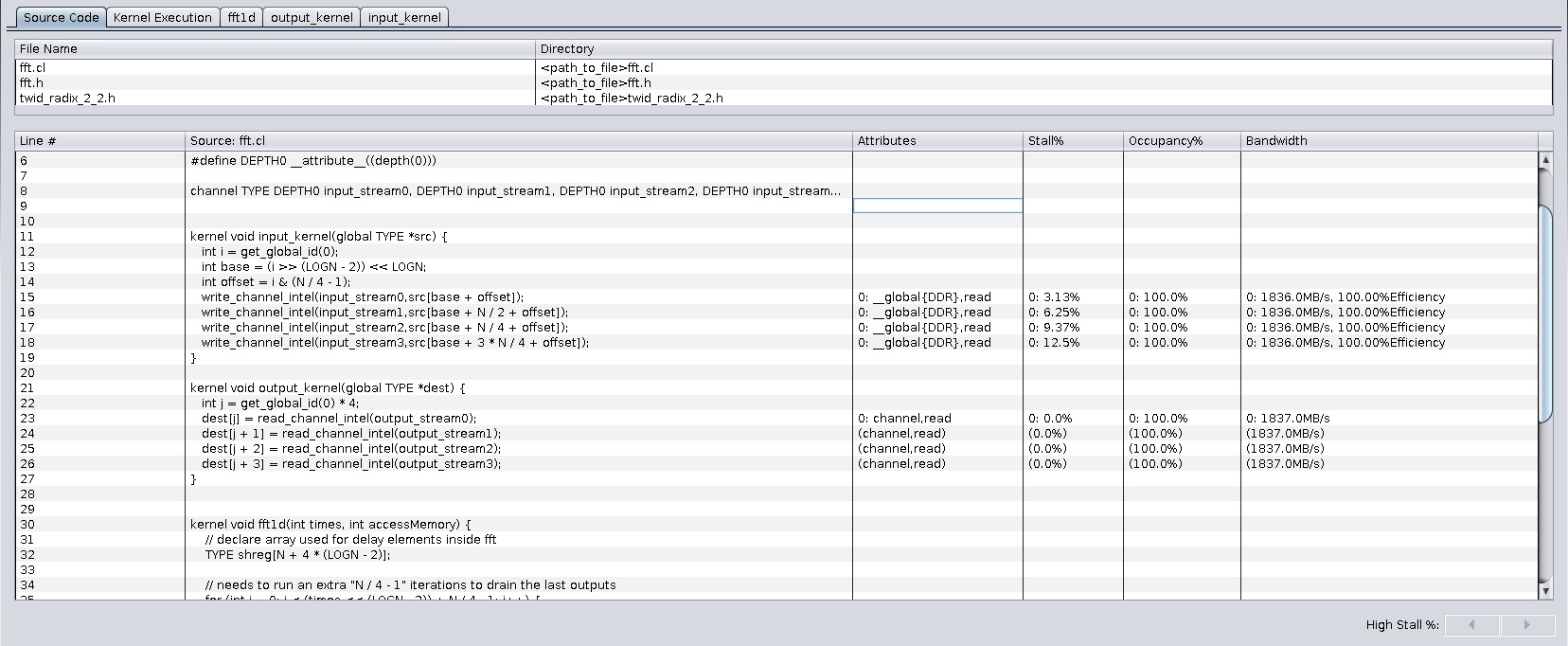
The Source Code tab provides detailed information on specific lines of kernel code.
| Column | Description | Access Type |
|---|---|---|
| Attributes | Memory or channel attributes information such as memory type (local or global), corresponding memory system (DDR or quad data rate (QDR)), and read or write access. | All memory and channel accesses |
| Stall% | Percentage of time the memory or channel access is causing pipeline stalls. It is a measure of the ability of the memory or channel access to fulfill an access request. | All memory and channel accesses |
| Occupancy% | Percentage of the overall profiled time frame when a valid work-item executes the memory or channel instruction. | All memory and channel accesses |
| Bandwidth | Average memory bandwidth that the memory access uses and its overall efficiency. For each global memory access, FPGA resources are assigned to acquire data from the global memory system. However, the amount of data a kernel program uses might be less than the acquired data. The overall efficiency is the percentage of total bytes, acquired from the global memory system, that the kernel program uses. |
Global memory accesses |
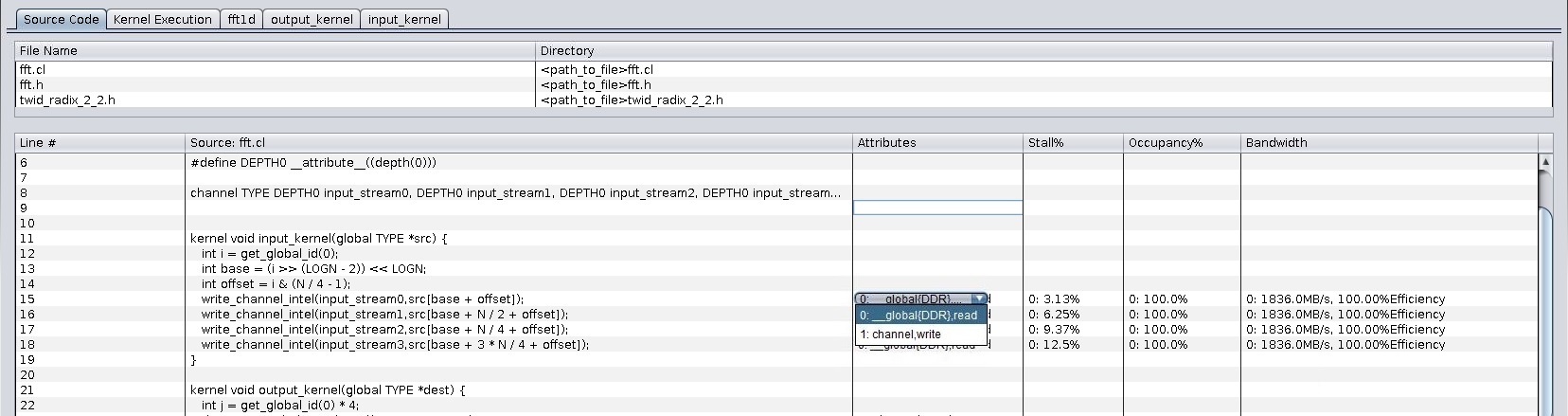
If a line of source code instructs more than one memory or channel operations, the profile statistics appear in a drop-down list box and you may select to view the relevant information.
Figure 64. Source Code Tab: Drop-Down List for Multiple Memory or Channel Operations