Intel® FPGA SDK for OpenCL™ Standard Edition: Best Practices Guide
ID
683176
Date
9/24/2018
Public
1. Introduction to Standard Edition Best Practices Guide
2. Reviewing Your Kernel's report.html File
3. OpenCL Kernel Design Best Practices
4. Profiling Your Kernel to Identify Performance Bottlenecks
5. Strategies for Improving Single Work-Item Kernel Performance
6. Strategies for Improving NDRange Kernel Data Processing Efficiency
7. Strategies for Improving Memory Access Efficiency
8. Strategies for Optimizing FPGA Area Usage
A. Additional Information
2.1. High Level Design Report Layout
2.2. Reviewing the Report Summary
2.3. Reviewing Loop Information
2.4. Reviewing Area Information
2.5. Verifying Information on Memory Replication and Stalls
2.6. Optimizing an OpenCL Design Example Based on Information in the HTML Report
2.7. HTML Report: Area Report Messages
2.8. HTML Report: Kernel Design Concepts
3.1. Transferring Data Via Channels or OpenCL Pipes
3.2. Unrolling Loops
3.3. Optimizing Floating-Point Operations
3.4. Allocating Aligned Memory
3.5. Aligning a Struct with or without Padding
3.6. Maintaining Similar Structures for Vector Type Elements
3.7. Avoiding Pointer Aliasing
3.8. Avoid Expensive Functions
3.9. Avoiding Work-Item ID-Dependent Backward Branching
4.3.4.1. High Stall Percentage
4.3.4.2. Low Occupancy Percentage
4.3.4.3. Low Bandwidth Efficiency
4.3.4.4. High Stall and High Occupancy Percentages
4.3.4.5. No Stalls, Low Occupancy Percentage, and Low Bandwidth Efficiency
4.3.4.6. No Stalls, High Occupancy Percentage, and Low Bandwidth Efficiency
4.3.4.7. Stalling Channels
4.3.4.8. High Stall and Low Occupancy Percentages
7.1. General Guidelines on Optimizing Memory Accesses
7.2. Optimize Global Memory Accesses
7.3. Performing Kernel Computations Using Constant, Local or Private Memory
7.4. Improving Kernel Performance by Banking the Local Memory
7.5. Optimizing Accesses to Local Memory by Controlling the Memory Replication Factor
7.6. Minimizing the Memory Dependencies for Loop Pipelining
2.4.2. Area Analysis of System
The area analysis of system report shows an area breakdown of your OpenCL system that is the closest approximation to the hardware that is implemented in the FPGA.
OpenCL kernel example that includes four loops:
1 // ND-Range kernel with unrolled loops
2 __attribute((reqd_work_group_size(1024,1,1)))
3 kernel void t (global int * out, int N) {
4 int i = get_global_id(0);
5 int j = 1;
6 for (int k = 0; k < 4; k++) {
7 #pragma unroll
8 for (int n = 0; n < 4; n++) {
9 j += out[k+n];
10 }
11 }
12 out[i] = j;
13
14 int m = 0;
15 #pragma unroll 1
16 for (int k = 0; k < N; k++) {
17 m += out[k/3];
18 }
19 #pragma unroll
20 for (int k = 0; k < 6; k++) {
21 m += out[k];
22 }
23 #pragma unroll 2
24 for (int k = 0; k < 6; k++) {
25 m += out[k];
26 }
27 out[2] = m;
28 }
Figure 25. System View of an Example Area Report
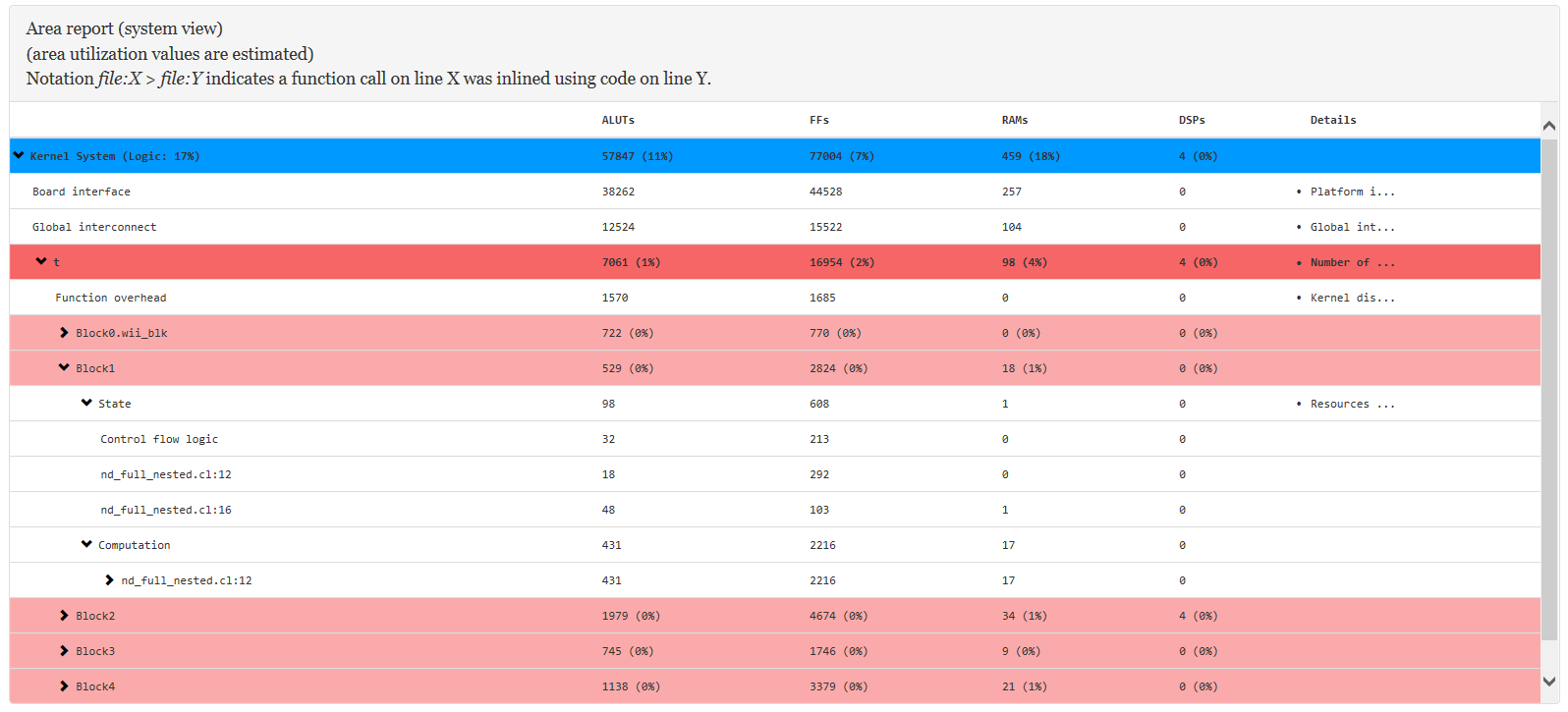
In the system view, the kernel is divided into logic blocks. To view the area usage information for the code lines associated with a block, simply expand the report entry for that block. In this example, area information for the code line out[i] = j (line 12) is available under Block1. The estimated area usage for line 12 in the system view is the same as the estimation in the source view.