Intel® FPGA SDK for OpenCL™ Pro Edition: Best Practices Guide
ID
683521
Date
12/19/2022
Public
Product Discontinuance Notification
1. Introduction to Intel® FPGA SDK for OpenCL™ Pro Edition Best Practices Guide
2. Reviewing Your Kernel's report.html File
3. OpenCL Kernel Design Concepts
4. OpenCL Kernel Design Best Practices
5. Profiling Your Kernel to Identify Performance Bottlenecks
6. Strategies for Improving Single Work-Item Kernel Performance
7. Strategies for Improving NDRange Kernel Data Processing Efficiency
8. Strategies for Improving Memory Access Efficiency
9. Strategies for Optimizing FPGA Area Usage
10. Strategies for Optimizing Intel® Stratix® 10 OpenCL Designs
11. Strategies for Improving Performance in Your Host Application
12. Intel® FPGA SDK for OpenCL™ Pro Edition Best Practices Guide Archives
A. Document Revision History for the Intel® FPGA SDK for OpenCL™ Pro Edition Best Practices Guide
2.1. High-Level Design Report Layout
2.2. Reviewing the Summary Report
2.3. Viewing Throughput Bottlenecks in the Design
2.4. Using Views
2.5. Analyzing Throughput
2.6. Reviewing Area Information
2.7. Optimizing an OpenCL Design Example Based on Information in the HTML Report
2.8. Accessing HLD FPGA Reports in JSON Format
4.1. Transferring Data Via Intel® FPGA SDK for OpenCL™ Channels or OpenCL Pipes
4.2. Unrolling Loops
4.3. Optimizing Floating-Point Operations
4.4. Allocating Aligned Memory
4.5. Aligning a Struct with or without Padding
4.6. Maintaining Similar Structures for Vector Type Elements
4.7. Avoiding Pointer Aliasing
4.8. Avoid Expensive Functions
4.9. Avoiding Work-Item ID-Dependent Backward Branching
5.1. Best Practices for Profiling Your Kernel
5.2. Instrumenting the Kernel Pipeline with Performance Counters (-profile)
5.3. Obtaining Profiling Data During Runtime
5.4. Reducing Area Resource Use While Profiling
5.5. Temporal Performance Collection
5.6. Performance Data Types
5.7. Interpreting the Profiling Information
5.8. Profiler Analyses of Example OpenCL Design Scenarios
5.9. Intel® FPGA Dynamic Profiler for OpenCL™ Limitations
8.1. General Guidelines on Optimizing Memory Accesses
8.2. Optimize Global Memory Accesses
8.3. Performing Kernel Computations Using Constant, Local or Private Memory
8.4. Improving Kernel Performance by Banking the Local Memory
8.5. Optimizing Accesses to Local Memory by Controlling the Memory Replication Factor
8.6. Minimizing the Memory Dependencies for Loop Pipelining
8.7. Static Memory Coalescing
6.1.1. Removing Loop-Carried Dependency
Based on the feedback from the optimization report, you can remove a loop-carried dependency by implementing a simpler memory access pattern.
Consider the following kernel:
1 #define N 128
2
3 __kernel void unoptimized (__global int * restrict A,
4 __global int * restrict B,
5 __global int* restrict result)
6 {
7 int sum = 0;
8
9 for (unsigned i = 0; i < N; i++) {
10 for (unsigned j = 0; j < N; j++) {
11 sum += A[i*N+j];
12 }
13 sum += B[i];
14 }
15
16 * result = sum;
17 }The optimization report for kernel unoptimized resembles the following: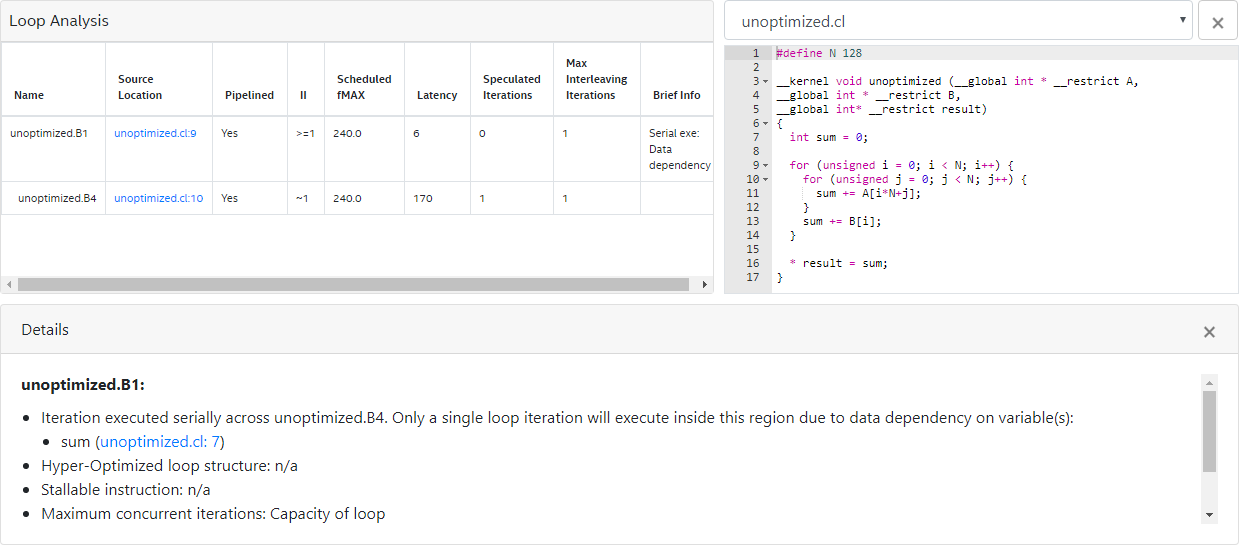
- The first row of the report indicates that the Intel® FPGA SDK for OpenCL™ Offline Compiler successfully infers pipelined execution for the outer loop, and a new loop iteration launches every other cycle.
- The message due to Pipeline structure indicates that the offline compiler creates a pipeline structure that causes an outer loop iteration to launch every two cycles. The behavior is not a result of how you structure your kernel code.
Note: For recommendations on how to structure your single work-item kernel, refer to the Good Design Practices for Single Work-Item Kernel section.
- The remaining messages in the first row of report indicate that the loop executes a single iteration at a time across the subloop because of data dependency on the variable sum. This data dependency exists because each outer loop iteration requires the value of sum from the previous iteration to return before the inner loop can start executing.
- The second row of the report notifies you that the inner loop executes in a pipelined fashion with no performance-limiting loop-carried dependencies.
To optimize the performance of this kernel, remove the data dependency on variable sum so that the outer loop iterations do not execute serially across the subloop. Perform the following tasks to decouple the computations involving sum in the two loops:
- Define a local variable (for example, sum2) for use in the inner loop only.
- Use the local variable from Step 1 to store the cumulative values of A[i*N + j] as the inner loop iterates.
- In the outer loop, store the variable sum to store the cumulative values of B[i] and the value stored in the local variable.
Below is the restructured kernel optimized:
1 #define N 128
2
3 __kernel void optimized (__global int * restrict A,
4 __global int * restrict B,
5 __global int * restrict result)
6 {
7 int sum = 0;
8
9 for (unsigned i = 0; i < N; i++) {
10 // Step 1: Definition
11 int sum2 = 0;
12
13 // Step 2: Accumulation of array A values for one outer loop iteration
14 for (unsigned j = 0; j < N; j++) {
15 sum2 += A[i*N+j];
16 }
17
18 // Step 3: Addition of array B value for an outer loop iteration
19 sum += sum2;
20 sum += B[i];
21 }
22
23 * result = sum;
24 }An optimization report similar to the one below indicates the successful removal of the loop-carried dependency on the variable sum: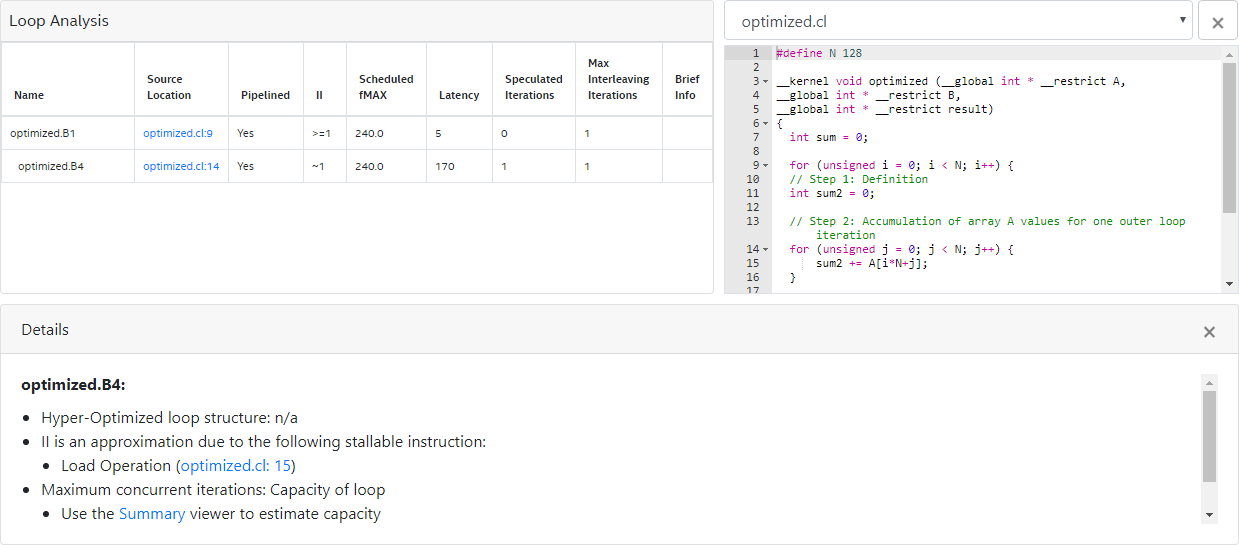
You have addressed all the loop-carried dependence issues successfully when you see only the following messages in the optimization report:
- Pipelined execution inferred for innermost loops.
- Pipelined execution inferred. Successive iterations launched every 2 cycles due to: Pipeline structure for all other loops.
Related Information