Intel® oneAPI Data Analytics Library Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
K-Means initialization
The K-Means initialization algorithm receives n feature vectors as input and chooses k initial centroids. After initialization, K-Means algorithm uses the initialization result to partition input data into k clusters.
Operation |
Computational methods |
Programming Interface |
|||||
Mathematical formulation
Computing
Given the training set 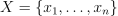 of p-dimensional feature vectors and a positive integer k, the problem is to find a set
of p-dimensional feature vectors and a positive integer k, the problem is to find a set 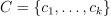 of p-dimensional initial centroids.
of p-dimensional initial centroids.
Computing method: dense
The method chooses first k feature vectors from the training set X.
Computing method: random_dense
The method chooses random k feature vectors from the training set X.
Computing method: plus_plus_dense (only on CPU)
The method is designed as follows: the first centroid 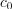 is selected randomly and
is selected randomly and  . Then the following step is repeated until C reaches the necessary size.
. Then the following step is repeated until C reaches the necessary size.
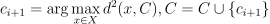
Computing method: parallel_plus_dense (only on CPU)
The method is the same as K-Means++, but the data is divided into equal parts and the algorithm runs on each of them.
Programming Interface
Refer to API Reference: K-Means initialization.
Usage Example
Computing
table run_compute(const table& data) {
const auto kmeans_desc = kmeans_init::descriptor<float,
kmeans_init::method::dense>{}
.set_cluster_count(10)
const auto result = compute(kmeans_desc, data);
print_table("centroids", result.get_centroids());
return result.get_centroids();
}Examples
oneAPI DPC++
Batch Processing:
oneAPI C++
Batch Processing: