Intel® oneAPI Data Analytics Library Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
Decision Tree
Decision trees partition the feature space into a set of hypercubes, and then fit a simple model in each hypercube. The simple model can be a prediction model, which ignores all predictors and predicts the majority (most frequent) class (or the mean of a dependent variable for regression), also known as 0-R or constant classifier.
Decision tree induction forms a tree-like graph structure as shown in the figure below, where:
Each internal (non-leaf) node denotes a test on features
Each branch descending from node corresponds to an outcome of the test
Each external node (leaf) denotes the mentioned simple model
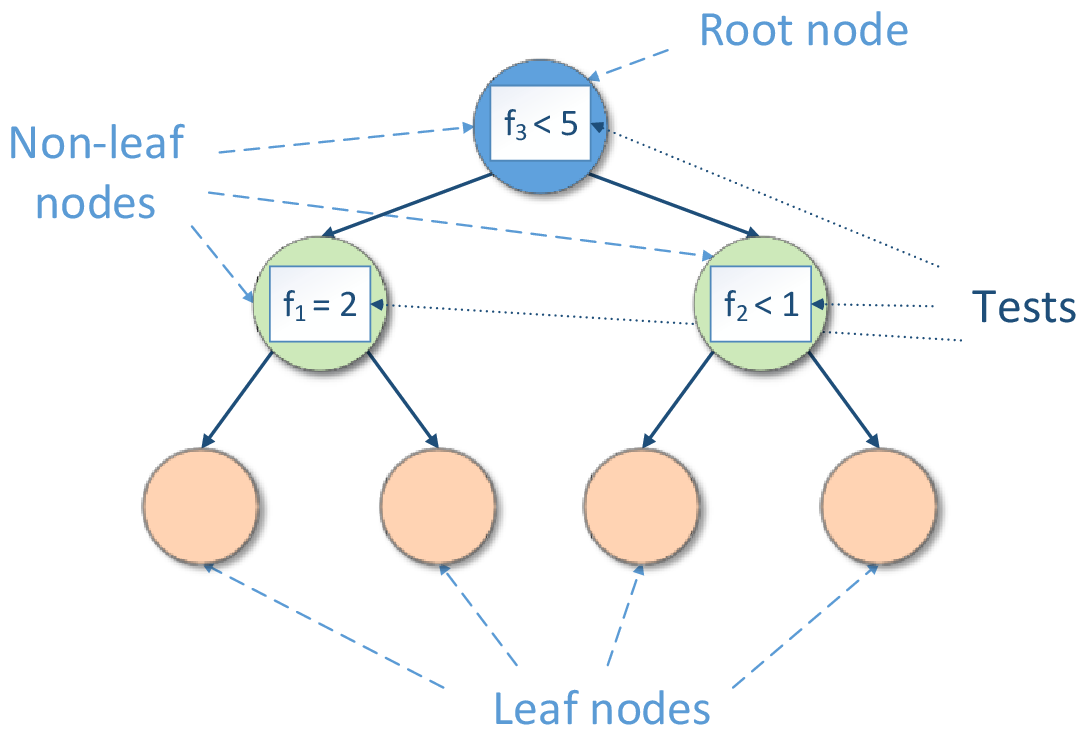
The test is a rule for partitioning of the feature space. The test depends on feature values. Each outcome of the test represents an appropriate hypercube associated with both the test and one of descending branches. If the test is a Boolean expression (for example,  or
or  , where f is a feature and c is a constant fitted during decision tree induction), the inducted decision tree is a binary tree, so its each non-leaf node has exactly two branches (‘true’ and ‘false’) according to the result of the Boolean expression.
, where f is a feature and c is a constant fitted during decision tree induction), the inducted decision tree is a binary tree, so its each non-leaf node has exactly two branches (‘true’ and ‘false’) according to the result of the Boolean expression.
Prediction is performed by starting at the root node of the tree, testing features by the test specified by this node, then moving down the tree branch corresponding to the outcome of the test for the given example. This process is then repeated for the subtree rooted at the new node. The final result is the prediction of the simple model at the leaf node.
Decision trees are often used in popular ensembles (e.g. boosting, bagging or decision forest).
Details
Given n feature vectors  of size p and the vector of responses
of size p and the vector of responses 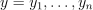 , the problem is to build a decision tree.
, the problem is to build a decision tree.
Split Criteria
The library provides the decision tree classification algorithm based on split criteria Gini index [Breiman84] and Information gain [Quinlan86], [Mitchell97]. See details in Classification Decision Tree.
The library also provides the decision tree regression algorithm based on the mean-squared error (MSE) [Breiman84]. See details in Regression Decision Tree.
Types of Tests
The library inducts decision trees with the following types of tests:
For continuous features, the test has a form of
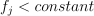 , where
, where  is a feature,
is a feature, 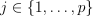 .
.While enumerating all possible tests for each continuous feature, the constant can be any threshold as midway between sequential values for sorted unique values of given feature
that reach the node.For categorical features, the test has a form of
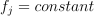 , where is a feature, .
, where is a feature, .While enumerating all possible tests for each categorical feature, the constant can be any value of given feature
that reach the node.For ordinal features, the test has a form of
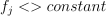 where is a feature, .
where is a feature, .While enumerating all possible tests for each ordinal feature, the constant can be any unique value except for the first one (in the ascending order) of given feature
that reach the node
Post-pruning
Optionally, the decision tree can be post-pruned using given m feature vectors  of size p, a vector of class labels
of size p, a vector of class labels 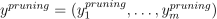 for classification or a vector of responses for regression. For more details about pruning, see [Quinlan87].
for classification or a vector of responses for regression. For more details about pruning, see [Quinlan87].
Pruned dataset can be some fraction of original training dataset (e.g. randomly chosen 30% of observations), but in this case those observations must be excluded from the training dataset.
Training Stage
The library uses the following algorithmic framework for the training stage.
The decision tree grows recursively from the root node, which corresponds to the entire training dataset. This process takes into account pre-pruning parameters: maximum tree depth and minimum number of observations in the leaf node . For each feature, each possible test is examined to be the best one according to the given split criterion. The best test is used to perform partition of the feature space into a set of hypercubes, and each hypercube represents appropriate part of the training dataset to accomplish the construction of each node at the next level in the decision tree.
After the decision tree is built, it can optionally be pruned by Reduced Error Pruning (REP) [Quinlan87] to avoid overfitting. REP assumes that there is a separate pruning dataset, each observation in which is used to get prediction by the original (unpruned) tree. For every non-leaf subtree, the change in mispredictions is examined over the pruning dataset that would occur if this subtree was replaced by the best possible leaf:
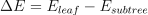
where
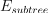 is the number of errors (for classification) and the mean-squared error (MSE) (for regression) for a given subtree
is the number of errors (for classification) and the mean-squared error (MSE) (for regression) for a given subtree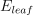 is the number of errors (for classification) and the MSE (for regression) for the best possible leaf, which replaces the given subtree.
is the number of errors (for classification) and the MSE (for regression) for the best possible leaf, which replaces the given subtree.
If the new tree gives an equal or fewer mispredictions (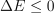 ) and the subtree contains no subtree with the same property, the subtree is replaced by the leaf. The process continues until any further replacements increase mispredictions over the pruning dataset. The final tree is the most accurate subtree of the original tree with respect to the pruning dataset and is the smallest tree with that accuracy.
) and the subtree contains no subtree with the same property, the subtree is replaced by the leaf. The process continues until any further replacements increase mispredictions over the pruning dataset. The final tree is the most accurate subtree of the original tree with respect to the pruning dataset and is the smallest tree with that accuracy.
The training procedure contains the following steps:
Grow the decision tree (subtree):
If all observations contain the same class label (for classification) or same value of dependent variable (for regression), or pre-pruning parameters disallow further decision tree growing, construct a leaf node.
Otherwise
For each feature, sort given feature values and evaluate an appropriate split criterion for every possible test (see Split Criteria and Types of Tests for details).
Construct a node with a test corresponding to the best split criterion value.
Partition observations according to outcomes of the found test and recursively grow a decision subtree for each partition.
Post-prune the decision tree (see Post-pruning for details).
Prediction Stage
The library uses the following algorithmic framework for the prediction stage.
Given the decision tree and vectors 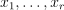 , the problem is to calculate the responses for those vectors.
, the problem is to calculate the responses for those vectors.
To solve the problem for each given vector 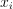 , the algorithm examines by tests in split nodes to find the leaf node, which contains the prediction response.
, the algorithm examines by tests in split nodes to find the leaf node, which contains the prediction response.