Intel® oneAPI Data Analytics Library Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
K-Means
The K-Means algorithm solves clustering problem by partitioning n feature vectors into k clusters minimizing some criterion. Each cluster is characterized by a representative point, called a centroid.
Operation |
Computational methods |
Programming Interface |
||
Mathematical formulation
Refer to Developer Guide: K-Means.
Programming Interface
All types and functions in this section are declared in the oneapi::dal::kmeans namespace and be available via inclusion of the oneapi/dal/algo/kmeans.hpp header file.
Descriptor
template<typenameFloat=float,typenameMethod=method::by_default,typenameTask=task::by_default>classdescriptor
- Template Parameters
-
Float – The floating-point type that the algorithm uses for intermediate computations. Can be float or double.
Method – Tag-type that specifies an implementation of algorithm. Can be method::lloyd_dense.
Task – Tag-type that specifies the type of the problem to solve. Can be task::clustering.
Constructors
descriptor(std::int64_tcluster_count=2)
Creates a new instance of the class with the given cluster_count.
Properties
result_option_idresult_options
Choose which results should be computed and returned.
- Getter & Setter
-
result_option_id get_result_options() const
auto & set_result_options(const result_option_id &value)
std::int64_tmax_iteration_count
The maximum number of iterations T. Default value: 100.
- Getter & Setter
-
std::int64_t get_max_iteration_count() const
auto & set_max_iteration_count(std::int64_t value)
- Invariants
-
max_iteration_count >= 0
std::int64_tcluster_count
The number of clusters k. Default value: 2.
- Getter & Setter
-
std::int64_t get_cluster_count() const
auto & set_cluster_count(std::int64_t value)
- Invariants
-
cluster_count > 0
doubleaccuracy_threshold
The threshold  for the stop condition. Default value: 0.0.
for the stop condition. Default value: 0.0.
- Getter & Setter
-
double get_accuracy_threshold() const
auto & set_accuracy_threshold(double value)
- Invariants
-
accuracy_threshold >= 0.0
Method tags
structlloyd_dense
Tag-type that denotes Lloyd’s computational method.
structlloyd_csr
Tag-type that denotes Lloyd’s computational method for sparse data.
usingby_default=lloyd_dense
Alias tag-type for Lloyd’s computational method.
Task tags
structclustering
Tag-type that parameterizes entities used for solving clustering problem.
usingby_default=clustering
Alias tag-type for the clustering task.
Model
template<typenameTask=task::by_default>classmodel
- Template Parameters
-
Task – Tag-type that specifies type of the problem to solve. Can be task::clustering.
Constructors
model()
Creates a new instance of the class with the default property values.
Public Methods
std::int64_tget_cluster_count()const
Number of clusters k in the trained model.
Properties
consttable¢roids
A 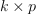 table with the cluster centroids. Each row of the table stores one centroid. Default value: table{}.
table with the cluster centroids. Each row of the table stores one centroid. Default value: table{}.
- Getter & Setter
-
const table & get_centroids() const
auto & set_centroids(const table &value)
Training train(...)
Input
template<typenameTask=task::by_default>classtrain_input
- Template Parameters
-
Task – Tag-type that specifies type of the problem to solve. Can be task::clustering.
Constructors
train_input(consttable&data)
train_input(consttable&data, consttable&initial_centroids)
Creates a new instance of the class with the given data and initial_centroids.
Properties
consttable&data
An 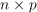 table with the data to be clustered, where each row stores one feature vector.
table with the data to be clustered, where each row stores one feature vector.
- Getter & Setter
-
const table & get_data() const
auto & set_data(const table &data)
consttable&initial_centroids
A table with the initial centroids, where each row stores one centroid.
- Getter & Setter
-
const table & get_initial_centroids() const
auto & set_initial_centroids(const table &data)
Result
template<typenameTask=task::by_default>classtrain_result
- Template Parameters
-
Task – Tag-type that specifies type of the problem to solve. Can be task::clustering.
Constructors
train_result()
Creates a new instance of the class with the default property values.
Properties
doubleobjective_function_value
The value of the objective function 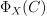 , where
, where 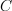 is model.centroids.
is model.centroids.
- Getter & Setter
-
double get_objective_function_value() const
auto & set_objective_function_value(double value)
- Invariants
-
objective_function_value >= 0.0
consttable&responses
An 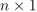 table with the responses
table with the responses 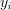 assigned to the samples
assigned to the samples 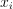 in the input data,
in the input data, 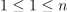 . Default value: table{}.
. Default value: table{}.
- Getter & Setter
-
const table & get_responses() const
auto & set_responses(const table &value)
std::int64_titeration_count
The number of iterations performed by the algorithm. Default value: 0.
- Getter & Setter
-
std::int64_t get_iteration_count() const
auto & set_iteration_count(std::int64_t value)
- Invariants
-
iteration_count >= 0
constmodel<Task>&model
The trained K-means model. Default value: model<Task>{}.
- Getter & Setter
-
const model< Task > & get_model() const
auto & set_model(const model< Task > &value)
consttable&labels
An table with the labels assigned to the samples in the input data, . Default value: table{}.
- Getter & Setter
-
const table & get_labels() const
auto & set_labels(const table &value)
Operation
template<typenameDescriptor>kmeans::train_resulttrain(constDescriptor&desc, constkmeans::train_input&input)
- Parameters
-
desc – K-Means algorithm descriptor kmeans::descriptor
input – Input data for the training operation
- Preconditions
-
input.data.has_data == true
input.initial_centroids.row_count == desc.cluster_count
input.initial_centroids.column_count == input.data.column_count
- Postconditions
-
result.labels.row_count == input.data.row_count
result.labels.column_count == 1
result.labels[i] >= 0
result.labels[i] < desc.cluster_count
result.iteration_count <= desc.max_iteration_count
result.model.centroids.row_count == desc.cluster_count
result.model.centroids.column_count == input.data.column_count
Inference infer(...)
Input
template<typenameTask=task::by_default>classinfer_input
- Template Parameters
-
Task – Tag-type that specifies type of the problem to solve. Can be task::clustering.
Constructors
infer_input(constmodel<Task>&trained_model, consttable&data)
Creates a new instance of the class with the given model and data.
Properties
constmodel<Task>&model
An table with the data to be assigned to the clusters, where each row stores one feature vector. Default value: model<Task>{}.
- Getter & Setter
-
const model< Task > & get_model() const
auto & set_model(const model< Task > &value)
consttable&data
The trained K-Means model. Default value: table{}.
- Getter & Setter
-
const table & get_data() const
auto & set_data(const table &value)
Result
template<typenameTask=task::by_default>classinfer_result
- Template Parameters
-
Task – Tag-type that specifies type of the problem to solve. Can be task::clustering.
Constructors
infer_result()
Creates a new instance of the class with the default property values.
Properties
consttable&labels
An table with assignments labels to feature vectors in the input data. Default value: table{}.
- Getter & Setter
-
const table & get_labels() const
auto & set_labels(const table &value)
doubleobjective_function_value
The value of the objective function , where is defined by the corresponding infer_input::model::centroids. Default value: 0.0.
- Getter & Setter
-
double get_objective_function_value() const
auto & set_objective_function_value(double value)
- Invariants
-
objective_function_value >= 0.0
constresult_option_id&result_options
Result options that indicates availability of the properties. Default value: default_result_options<Task>.
- Getter & Setter
-
const result_option_id & get_result_options() const
auto & set_result_options(const result_option_id &value)
consttable&responses
An table with assignments responses to feature vectors in the input data. Default value: table{}.
- Getter & Setter
-
const table & get_responses() const
auto & set_responses(const table &value)
Operation
template<typenameDescriptor>kmeans::infer_resultinfer(constDescriptor&desc, constkmeans::infer_input&input)
- Parameters
-
desc – K-Means algorithm descriptor kmeans::descriptor
input – Input data for the inference operation
- Preconditions
-
input.data.has_data == true
input.model.centroids.has_data == true
input.model.centroids.row_count == desc.cluster_count
input.model.centroids.column_count == input.data.column_count
- Postconditions
-
result.labels.row_count == input.data.row_count
result.labels.column_count == 1
result.labels[i] >= 0
result.labels[i] < desc.cluster_count
Usage Example
Training
kmeans::model<> run_training(const table& data,
const table& initial_centroids) {
const auto kmeans_desc = kmeans::descriptor<float>{}
.set_cluster_count(10)
.set_max_iteration_count(50)
.set_accuracy_threshold(1e-4);
const auto result = train(kmeans_desc, data, initial_centroids);
print_table("labels", result.get_labels());
print_table("centroids", result.get_model().get_centroids());
print_value("objective", result.get_objective_function_value());
return result.get_model();
}Inference
table run_inference(const kmeans::model<>& model,
const table& new_data) {
const auto kmeans_desc = kmeans::descriptor<float>{}
.set_cluster_count(model.get_cluster_count());
const auto result = infer(kmeans_desc, model, new_data);
print_table("labels", result.get_labels());
}Examples
oneAPI DPC++
Batch Processing:
oneAPI C++
Batch Processing: