Intel® oneAPI Data Analytics Library Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
Support Vector Machine Classifier and Regression (SVM)
Support Vector Machine (SVM) classification and regression are among popular algorithms. It belongs to a family of generalized linear classification problems.
Operation |
Computational methods |
Programming Interface |
|||
Mathematical formulation
Training
Given n feature vectors 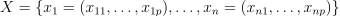 of size p, their non-negative observation weights
of size p, their non-negative observation weights 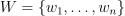 , and n responses
, and n responses 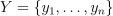 ,
,
Classification
 , where M is the number of classes
, where M is the number of classes
Regression
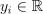
Nu-classification
- , where M is the number of classes
Nu-regression
the problem is to build a Support Vector Machine (SVM) classification, regression, nu-classification, or nu-regression model.
The SVM model is trained using the Sequential minimal optimization (SMO) method [Boser92] for reduced to the solution of the quadratic optimization problem
Classification
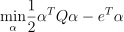
with 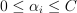 ,
, 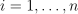 ,
, 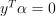 , where e is the vector of ones, C is the upper bound of the coordinates of the vector
, where e is the vector of ones, C is the upper bound of the coordinates of the vector  , Q is a symmetric matrix of size
, Q is a symmetric matrix of size 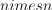 with
with 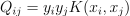 , and
, and  is a kernel function.
is a kernel function.
Regression
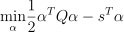
with , 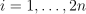 ,
, 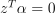 , where C is the upper bound of the coordinates of the vector , Q is a symmetric matrix of size
, where C is the upper bound of the coordinates of the vector , Q is a symmetric matrix of size 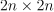 with , and is a kernel function. Vectors s and z for the regression problem are formulated according to the following rule:
with , and is a kernel function. Vectors s and z for the regression problem are formulated according to the following rule:
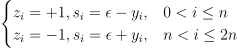
Where  is the error tolerance parameter.
is the error tolerance parameter.
Nu-classification
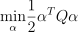
with 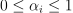 , ,
, , 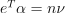 ,
, 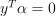 , where e is the vector of ones,
, where e is the vector of ones,  is an upper bound on the fraction of training errors and a lower bound of the fraction of the support vector, Q is a symmetric matrix of size with , and is a kernel function.
is an upper bound on the fraction of training errors and a lower bound of the fraction of the support vector, Q is a symmetric matrix of size with , and is a kernel function.
Nu-regression
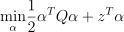
with 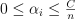 , ,
, , 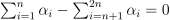 ,
, 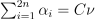 , where C is the upper bound of the coordinates of the vector , is an upper bound on the fraction of training errors and a lower bound of the fraction of the support vector, Q is a symmetric matrix of size with , and is a kernel function. Vector z for the regression problem are formulated according to the following rule:
, where C is the upper bound of the coordinates of the vector , is an upper bound on the fraction of training errors and a lower bound of the fraction of the support vector, Q is a symmetric matrix of size with , and is a kernel function. Vector z for the regression problem are formulated according to the following rule:
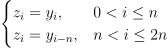
Working subset of α updated on each iteration of the algorithm is based on the Working Set Selection (WSS) 3 scheme [Fan05]. The scheme can be optimized using one of these techniques or both:
Cache: the implementation can allocate a predefined amount of memory to store intermediate results of the kernel computation.
Shrinking: the implementation can try to decrease the amount of kernel related computations (see [Joachims99]).
The solution of the problem defines the separating hyperplane and corresponding decision function  , where only those
, where only those 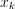 that correspond to non-zero
that correspond to non-zero  appear in the sum, and b is a bias. Each non-zero is called a dual coefficient and the corresponding is called a support vector.
appear in the sum, and b is a bias. Each non-zero is called a dual coefficient and the corresponding is called a support vector.
Training method: smo
In smo training method, all vectors from the training dataset are used for each iteration.
Training method: thunder
In thunder training method, the algorithm iteratively solves the convex optimization problem with the linear constraints by selecting the fixed set of active constrains (working set) and applying Sequential Minimal Optimization (SMO) solver to the selected subproblem. The description of this method is given in Algorithm [Wen2018].
Inference methods: smo and thunder
smo and thunder inference methods perform prediction in the same way:
Given the SVM classification or regression model and r feature vectors 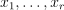 , the problem is to calculate the signed value of the decision function
, the problem is to calculate the signed value of the decision function 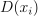 ,
, 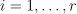 . The sign of the value defines the class of the feature vector, and the absolute value of the function is a multiple of the distance between the feature vector and the separating hyperplane.
. The sign of the value defines the class of the feature vector, and the absolute value of the function is a multiple of the distance between the feature vector and the separating hyperplane.
Programming Interface
Refer to API Reference: Support Vector Machine Classifier and Regression.
Examples
oneAPI DPC++
Batch Processing:
oneAPI C++
Batch Processing: