A newer version of this document is available. Customers should click here to go to the newest version.
Issue: Data Parallel Construct Inefficiency
The SYCL language allows to use data parallel constructs within each command group. This feature of rule-check analysis tries to capture the efficiency of a data parallel construct. The inefficiencies in the data parallel construct are broken down into two parts:
- Startup costs for kicking off the data parallel algorithm on the worker threads.
- Imbalance costs encountered during the execution of the algorithm.
The combination of these parts affects the overall efficiency of the data parallel algorithm. The data and screenshots shown in this section are from the Nbody sample that is available with Intel® oneAPI Toolkits.
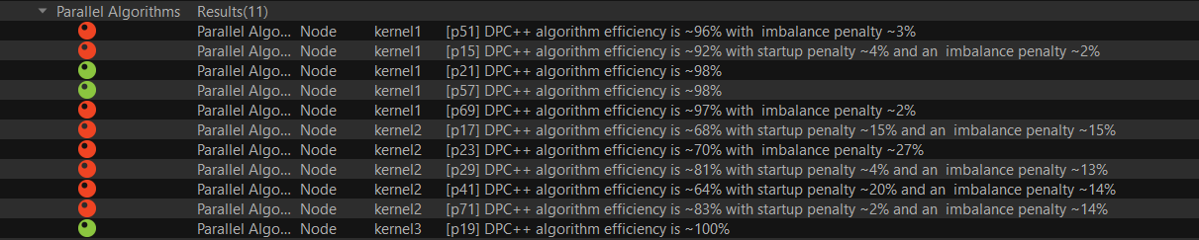
Startup Penalty
The startup costs are primarily related to the worker threads participating in the parallel algorithm starting up slowly. If your application exhibits a lot of inefficiencies due to startup costs, the Linux* kernel maybe biased towards power. You can use the following command to ensure that it is set to performance:
echo performance > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
You will need sudo privileges to run this command and this setting is reset after system reboot.
Imbalance Penalty
Imbalance penalties are usually due to static partitioning of a data parallel workload that have varying costs per iteration of the loop or when the granularity of the block size is too large when dynamic partitioning is used. Many times, addressing the startup penalties will improve the amount of imbalance in the algorithm, but if they are retained, the following options maybe tried to improve performance:
- If the algorithm usesrange, the runtime is automatically picking the block size and may be causing the imbalance. You can override this by using nd_range and specifying a block size that would eliminate the imbalance.
- If nd_range is used, this issue may be caused by using a block_size that is larger than optimal. Reducing the block size may improve performance or using range and letting the runtime decide may also be an option.