Intel® Quartus® Prime Pro Edition User Guide: Design Optimization
ID
683641
Date
12/04/2023
Public
A newer version of this document is available. Customers should click here to go to the newest version.
Answers to Top FAQs
1. Design Optimization Overview
2. Optimizing the Design Netlist
3. Netlist Optimizations and Physical Synthesis
4. Area Optimization
5. Timing Closure and Optimization
6. Analyzing and Optimizing the Design Floorplan
7. Using the ECO Compilation Flow
8. Intel® Quartus® Prime Pro Edition Design Optimization User Guide Archives
A. Intel® Quartus® Prime Pro Edition User Guides
2.1. When to Use the Netlist Viewers: Analyzing Design Problems
2.2. Intel® Quartus® Prime Design Flow with the Netlist Viewers
2.3. RTL Viewer Overview
2.4. Technology Map Viewer Overview
2.5. Netlist Viewer User Interface
2.6. Schematic View
2.7. Cross-Probing to a Source Design File and Other Intel® Quartus® Prime Windows
2.8. Cross-Probing to the Netlist Viewers from Other Intel® Quartus® Prime Windows
2.9. Viewing a Timing Path
2.10. Optimizing the Design Netlist Revision History
2.6.1. Display Schematics in Multiple Tabbed View
2.6.2. Schematic Symbols
2.6.3. Select Items in the Schematic View
2.6.4. Shortcut Menu Commands in the Schematic View
2.6.5. Filtering in the Schematic View
2.6.6. View Contents of Nodes in the Schematic View
2.6.7. Moving Nodes in the Schematic View
2.6.8. View LUT Representations in the Technology Map Viewer
2.6.9. Zoom Controls
2.6.10. Navigating with the Bird's Eye View
2.6.11. Partition the Schematic into Pages
2.6.12. Follow Nets Across Schematic Pages
4.2.3.1. Guideline: Optimize Source Code
4.2.3.2. Guideline: Optimize Synthesis for Area, Not Speed
4.2.3.3. Guideline: Restructure Multiplexers
4.2.3.4. Guideline: Perform WYSIWYG Primitive Resynthesis with Balanced or Area Setting
4.2.3.5. Guideline: Use Register Packing
4.2.3.6. Guideline: Remove Fitter Constraints
4.2.3.7. Guideline: Flatten the Hierarchy During Synthesis
4.2.3.8. Guideline: Re-target Memory Blocks
4.2.3.9. Guideline: Use Physical Synthesis Options to Reduce Area
4.2.3.10. Guideline: Retarget or Balance DSP Blocks
4.2.3.11. Guideline: Use a Larger Device
4.2.3.12. Guideline: Reduce Global Signal Congestion
4.2.3.13. Guideline: Report Pipelining Information
4.2.4.1. Guideline: Set Auto Packed Registers to Sparse or Sparse Auto
4.2.4.2. Guideline: Set Fitter Aggressive Routability Optimizations to Always
4.2.4.3. Guideline: Increase Router Effort Multiplier
4.2.4.4. Guideline: Remove Fitter Constraints
4.2.4.5. Guideline: Optimize Synthesis for Routability
4.2.4.6. Guideline: Optimize Source Code
4.2.4.7. Guideline: Use a Larger Device
5.1. Optimize Multi Corner Timing
5.2. Optimize Critical Paths
5.3. Optimize Critical Chains
5.4. Design Evaluation for Timing Closure
5.5. Timing Optimization
5.6. Periphery to Core Register Placement and Routing Optimization
5.7. Scripting Support
5.8. Timing Closure and Optimization Revision History
5.5.1. Correct Design Assistant Rule Violations
5.5.2. Implement Fast Forward Timing Closure Recommendations
5.5.3. Review Timing Path Details
5.5.4. Try Optional Fitter Settings
5.5.5. Back-Annotating Optimized Assignments
5.5.6. Optimize Settings with Design Space Explorer II
5.5.7. Aggregating and Comparing Compilation Results with Exploration Dashboard
5.5.8. I/O Timing Optimization Techniques
5.5.9. Register-to-Register Timing Optimization Techniques
5.5.10. Metastability Analysis and Optimization Techniques
5.5.3.1. Report Timing
5.5.3.2. Report Logic Depth
5.5.3.3. Report Neighbor Paths
5.5.3.4. Report Register Spread
5.5.3.5. Report Route Net of Interest
5.5.3.6. Report Retiming Restrictions
5.5.3.7. Report Pipelining Information
5.5.3.8. Report CDC Viewer
5.5.3.9. Timing Closure Recommendations
5.5.3.10. Global Network Buffers
5.5.3.11. Resets and Global Networks
5.5.3.12. Suspicious Setup
5.5.3.13. Auto Shift Register Replacement
5.5.3.14. Clocking Architecture
5.5.8.1. I/O Timing Constraints
5.5.8.2. Optimize IOC Register Placement for Timing Logic Option
5.5.8.3. Fast Input, Output, and Output Enable Registers
5.5.8.4. Programmable Delays
5.5.8.5. Use PLLs to Shift Clock Edges
5.5.8.6. Use Fast Regional Clock Networks and Regional Clocks Networks
5.5.8.7. Spine Clock Limitations
5.5.9.1. Optimize Source Code
5.5.9.2. Improving Register-to-Register Timing
5.5.9.3. Physical Synthesis Optimizations
5.5.9.4. Set Power Optimization During Synthesis to Normal Compilation
5.5.9.5. Optimize Synthesis for Performance, Not Area
5.5.9.6. Flatten the Hierarchy During Synthesis
5.5.9.7. Set the Synthesis Effort to High
5.5.9.8. Change Adder Tree Styles
5.5.9.9. Duplicate Registers for Fan-Out Control
5.5.9.10. Prevent Shift Register Inference
5.5.9.11. Use Other Synthesis Options Available in Your Synthesis Tool
5.5.9.12. Fitter Seed
5.5.9.13. Set Maximum Router Timing Optimization Level
5.5.9.14. Register-to-Register Timing Analysis
5.5.9.14.1. Tips for Analyzing Failing Paths
5.5.9.14.2. Tips for Analyzing Failing Clock Paths that Cross Clock Domains
5.5.9.14.3. Tips for Critical Path Analysis
5.5.9.14.4. Tips for Creating a .tcl Script to Monitor Critical Paths Across Compiles
5.5.9.14.5. Global Routing Resources
5.5.9.14.6. Register RAMS and DSPs
6.1. Location Assignment Optimization Guidelines
6.2. Design Floorplan Analysis in Chip Planner
6.3. Defining Logic Lock Placement Constraints
6.4. Defining Virtual Pins
6.5. Using Logic Lock Regions in Combination with Design Partitions
6.6. Creating Clock Region Assignments in Chip Planner
6.7. Scripting Support
6.8. Analyzing and Optimizing the Design Floorplan Revision History
6.2.1. Starting the Chip Planner
6.2.2. Chip Planner GUI
6.2.3. Viewing Design Elements in Chip Planner
6.2.4. Finding Design Elements in the Chip Planner
6.2.5. Exploring Paths in the Chip Planner
6.2.6. Viewing Assignments in the Chip Planner
6.2.7. Viewing High-Speed and Low-Power Tiles in the Chip Planner
6.2.8. Viewing Design Partition Placement
6.2.3.1. Viewing Architecture-Specific Design Information in Chip Planner
6.2.3.2. Viewing Available Clock Networks in Chip Planner
6.2.3.3. Viewing Clock Sector Utilization in Chip Planner
6.2.3.4. Viewing Routing Congestion in Chip Planner
6.2.3.5. Viewing I/O Banks in Chip Planner
6.2.3.6. Viewing High-Speed Serial Interfaces (HSSI) in Chip Planner
6.2.3.7. Viewing Source and Destination Nodes in Chip Planner
6.2.3.8. Viewing Fan-In and Fan-Out in Chip Planner
6.2.3.9. Viewing Immediate Fan-In and Fan-Out in Chip Planner
6.2.3.10. Viewing the Selected Contents in Chip Planner
6.2.3.11. Viewing the Location and Utilization of Device Resources in Chip Planner
6.2.3.12. Viewing Module Placement by Cross-Probing to Chip Planner
6.3.1. The Logic Lock Regions Window
6.3.2. Defining Logic Lock Regions
6.3.3. Customizing the Shape of Logic Lock Regions
6.3.4. Assigning Device Pins to Logic Lock Regions
6.3.5. Viewing Connections Between Logic Lock Regions in Chip Planner
6.3.6. Example: Placement Best Practices for Intel® Arria® 10 FPGAs
6.3.7. Migrating Assignments between Intel® Quartus® Prime Standard Edition and Intel® Quartus® Prime Pro Edition
7.4.1. ECO Command Quick Reference
7.4.2. make_connection
7.4.3. remove_connection
7.4.4. modify_lutmask
7.4.5. adjust_pll_refclk
7.4.6. modify_io_slew_rate
7.4.7. modify_io_current_strength
7.4.8. modify_io_delay_chain
7.4.9. create_new_node
7.4.10. remove_node
7.4.11. place_node
7.4.12. unplace_node
7.4.13. create_wirelut
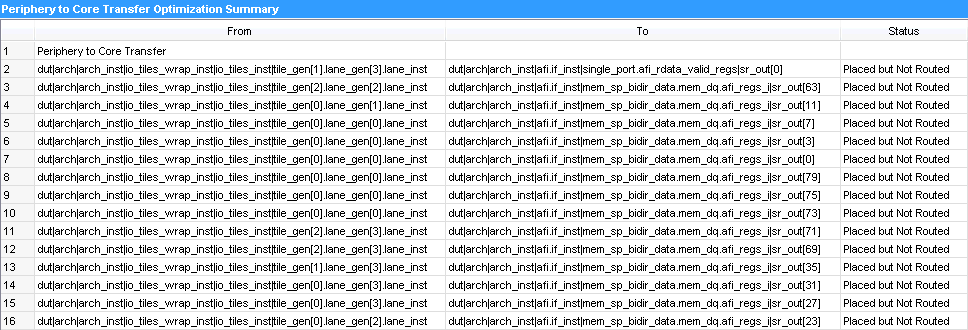
5.6.3. Viewing Periphery to Core Optimizations in the Fitter Report
The Intel® Quartus® Prime software generates a periphery to core placement and routing optimization summary in the Fitter (Place & Route) report after compilation.
- Compile your Intel® Quartus® Prime project.
- In the Tasks pane, select Compilation.
- Under Fitter (Place & Route), double-click View Report.
- In the Fitter folder, expand the Place Stage folder.
- Double-click Periphery to Core Transfer Optimization Summary.
Table 34. Fitter Report - Periphery to Core Transfer Optimization (P2C) Summary From Path To Path Status Node 1 Node 2 Placed and Routed—Core register is locked. Periphery to core/core to periphery routing is committed. Node 3 Node 4 Placed but not Routed—Core register is locked. Routing is not committed. This occurs when P2C is not able to optimize all targeted paths within a single group, for example, the same delay/wire requirement, or the same control signals. Partial P2C routing commitments may cause unresolvable routing congestion. Node 5 Node 6 Not Optimized—This occurs when P2C is set to Auto and the path is not optimized due to one of the following issues: - The delay requirement is impossible to achieve.
- The minimum delay requirement (for hold timing) is too large. The P2C algorithm cannot efficiently handle cases when many wires need to be added to meet hold timing.
- P2C encountered unresolvable routing congestion for this particular path.