Developer Guide
FPGA Optimization Guide for Intel® oneAPI Toolkits
A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-CF77246E-6DD4-49A2-82C2-30AD65B2F340
Visible to Intel only — GUID: GUID-CF77246E-6DD4-49A2-82C2-30AD65B2F340
Local and Private Memory Accesses Optimization
To optimize local memory access efficiency, consider the following guidelines:
- Implementing certain optimization techniques, such as loop unrolling, might lead to more concurrent memory accesses.
- Increasing the number of memory accesses can complicate memory systems and degrade performance.
- If you have function scope local data (defined in the body of a parallel_for_work_group lambda or by using group_local_memory_for_overwrite), the Intel® oneAPI DPC++/C++ Compiler statically sizes the local data that you define within a function body at compilation time.
- For accessors in the local space, the host assigns their memory sizes dynamically at runtime. However, the compiler must set these physical memory sizes at compilation time. By default, that size is 16 kB.
- The host can request a smaller data size than has been physically allocated at compilation time, but never a larger size.
- When accessing local memory, use the simplest address calculations possible and avoid pointer math operations that are not mandatory.
- Intel® recommends this coding style to reduce FPGA resource utilization and increase local memory efficiency by allowing the Intel® oneAPI DPC++/C++ Compiler to make better inferences about access patterns through static code analysis. For information about the benefits of static coalescing, refer to Static Memory Coalescing. Complex address calculations and pointer math operations can prevent the Intel® oneAPI DPC++/C++ Compiler from identifying the memory system accessed by a given load or store, leading to increased area use and decreased runtime performance.
- Avoid storing pointers to memory whenever possible. Stored pointers often prevent static compiler analysis from determining the data sets accessed, when pointers are subsequently retrieved from memory. Storing pointers to memory usually leads to suboptimal area and performance results.
- Create local array elements that are a power of two bytes to allow the Intel® oneAPI DPC++/C++ Compiler to provide an efficient memory configuration.
- Whenever possible, the Intel® oneAPI DPC++/C++ Compiler automatically pads the elements of the local memory to be a power of two to provide a more efficient memory configuration. For example, if you have a struct containing three chars, the Intel® oneAPI DPC++/C++ Compiler pads it to four bytes, instead of creating a narrower and deeper memory with multiple accesses (that is, a 1-byte wide memory configuration). However, there are cases where the Intel® oneAPI DPC++/C++ Compiler might not pad the memory, such as when the kernel accesses local memory indirectly through pointer arithmetic.
- To determine if the Intel® oneAPI DPC++/C++ Compiler has padded the local memory, review the memory dimensions in the Memory Viewer. If the Intel® oneAPI DPC++/C++ Compiler fails to pad the local memory, it prints a warning message in the Area Analysis of System report.
Local Memory Banks
Specifying the numbanks(N) and bankwidth(M) memory attributes allow you to configure the local memory banks for parallel memory accesses. The banking geometry described by these attributes determines which elements of the local memory system your kernel can access in parallel.
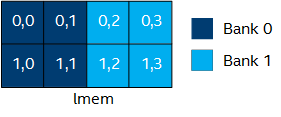
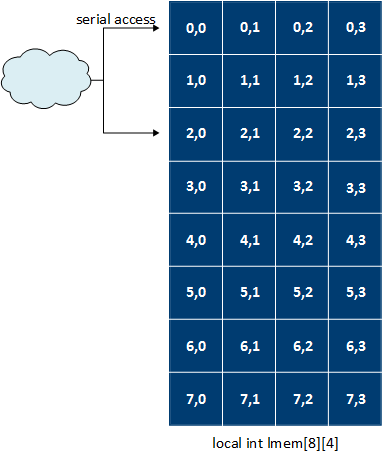
The following code example depicts an 8 x 4 local memory system that is implemented in a single bank. As a result, no two elements in the system can be accessed in parallel.
[[intel::fpga_memory]] int lmem[8][4]; #pragma unroll for(int i = 0; i<4; i+=2) { lmem[i][x] = ...; }
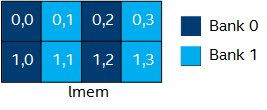
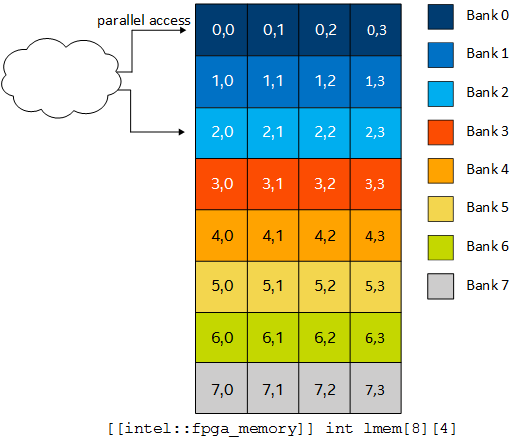
To improve performance, you can add numbanks(N) and bankwidth(M) in your code to define the number of memory banks and the bank widths in bytes. The following code implements eight memory banks, each 16-bytes wide. This memory bank configuration enables parallel memory accesses to the 8 x 4 array.
[[intel::numbanks(8), intel::bankwidth(16)]] int lmem[8][4]; #pragma unroll for (int i = 0; i < 4; i+=2) { lmem[i][x & 0x3] = ...; }
To enable parallel access, you must mask the dynamic access on the lower array index. Masking the dynamic access on the lower array index informs the Intel® oneAPI DPC++/C++ Compiler that x does not exceed the lower index bounds.
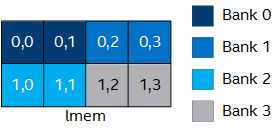
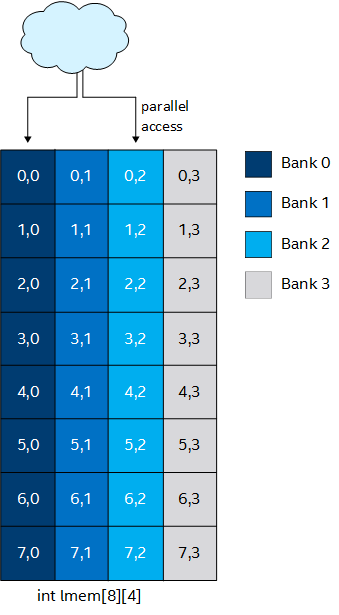
By specifying different values for the numbanks(N) and bankwidth(M) attributes, you can change the parallel access pattern. The following code implements four memory banks, each being four bytes wide:
This memory bank configuration enables parallel memory accesses to the 8 x 4 array.
[[intel::numbanks(4), intel::bankwidth(4)]] int lmem[8][4]; #pragma unroll for (int i = 0; i < 4; i+=2) { lmem[x][i] = ...; }
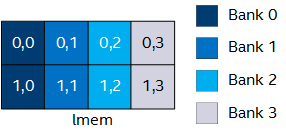
Optimize the Geometric Configuration of Local Memory Banks Based on Array Index
By default, the Intel® oneAPI DPC++/C++ Compiler attempts to improve performance by automatically banking a local memory system. The compiler includes advanced features that allow you to customize the banking geometry of your local memory system. To configure the geometry of local memory banks, include numbanks(N) and bankwidth(M) kernel attributes in your SYCL* kernel.
The table provides code examples illustrating how the bank geometry changes based on the values you assign to numbanks and bankwidth. The first and last rows of this table illustrate how to bank memory on the upper and lower indexes of a 2D array, respectively.
Code Example |
Bank Geometry |
|---|---|
|
|
|
|
|
|
|
|
|
|