To achieve high performance and efficient developer productivity across CPU, GPU, FPGA, and other architectures, developers need a unified programming model that enables them to select the optimal hardware for the task at hand. They need a high-level, open standard, heterogeneous programming language that’s both built on standards and extensible. It must boost developer productivity while providing consistent performance across architectures. SYCL*, a C++-based Khronos Group standard, addresses these challenges by extending C++ capabilities to support multiarchitecture and disjoint memory configurations.
To make it easier to adopt SYCL, developers may want to migrate their existing CUDA* GPU code so they don’t have to start their SYCL development from a blank page. We’ve previously published articles on using the Intel® DPC++ Compatibility Tool to migrate CUDA to SYCL. This tool is included in the Intel® oneAPI Base Toolkit and supported by Intel technical consulting engineers.
SYCLomatic Open-Source Project
In response to developer requests, the compatibility tool has now been released as an open-source project under the name “SYCLomatic.” Many organizations have successfully used the tool, and some also wanted to enhance and customize its capabilities to tune it to their needs. One of those organizations was Argonne National Laboratory.
CRK-HACC is an N-body cosmological simulation code actively under development. To prepare for Aurora, the Intel DPC++ Compatibility Tool allowed us to quickly migrate over 20 [CUDA] kernels to SYCL. Since the current version of the code migration tool does not support migration to functors, we wrote a simple Clang tool to refactor the resulting SYCL source code to meet our needs. With the open-source SYCLomatic project, we plan to integrate our previous work for a more robust solution and contribute to making functors part of the available migration options,” said Steve (Esteban) Rangel of HACC (Hardware/Hybrid Accelerated Cosmology Code), Cosmological Physics & Advanced Computing (anl.gov).
Utilizing the Apache* 2.0 license with LLVM exception, the SYCLomatic project hosted on GitHub offers a community for developers to contribute and provide feedback to further open heterogeneous development across CPUs, GPUs and FPGAs. The GitHub portal includes a “contributing.md” guide describing the steps for technical contributions to the project. Developers are encouraged to use the tool and provide feedback and contributions to advance the tool’s evolution. This open-source project enables community collaboration to advance adoption of the SYCL standard, a key step in freeing developers from a single-vendor proprietary ecosystem. Improvements made to SYCLomatic will also be incorporated in the Intel DPC++ Compatibility Tool product.
How the SYCLomatic Tool Works
SYCLomatic assists developers in porting CUDA code to SYCL, typically migrating 90-95% of CUDA code automatically to SYCL code.1 To finish the process, developers complete the rest of the coding manually and then tune to the desired level of performance for the target architecture (Figure 1).
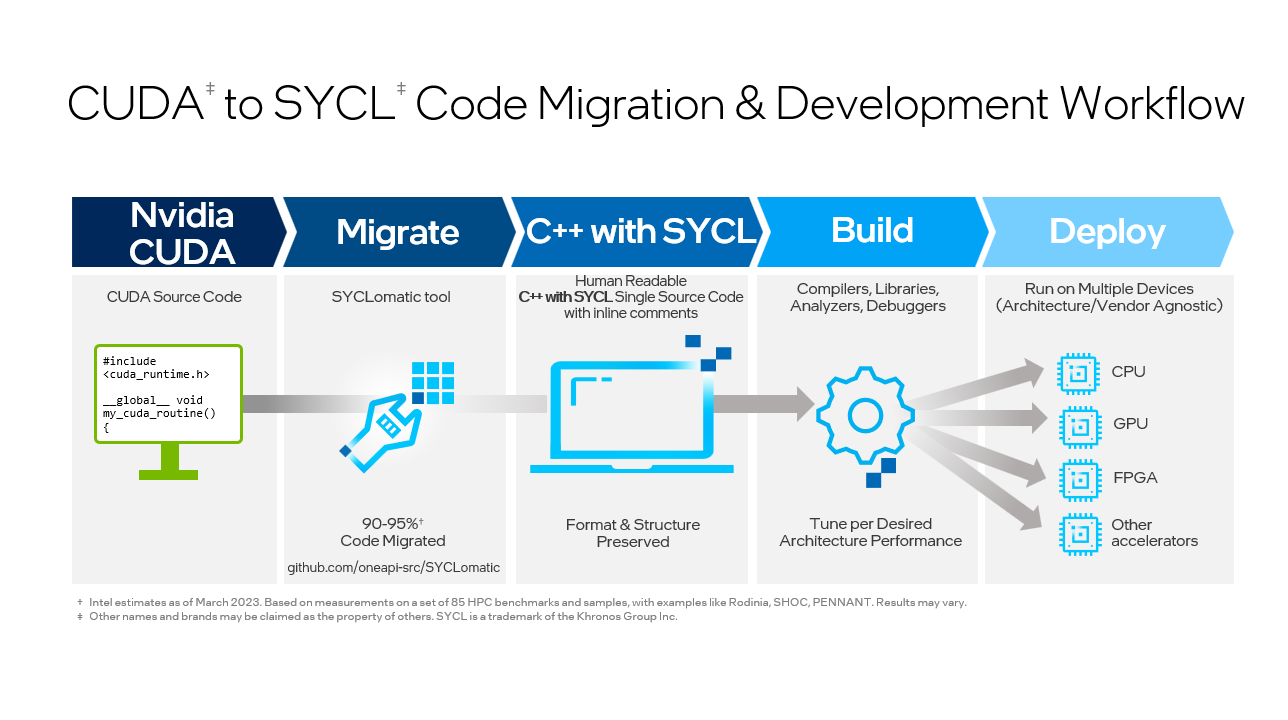
Figure 1. The SYCLomatic workflow.
Successful Code Migrations
Research organizations and Intel customers have successfully used the Intel DPC++ Compatibility Tool, which has the same technologies as SYCLomatic, to migrate CUDA code to SYCL (or Data Parallel C++, oneAPI’s implementation of SYCL) on multiple vendors’ architectures. Examples include the University of Stockholm with GROMACS 2022, Zuse Institute Berlin (ZIB) with easyWave, Samsung Medison and Bittware (view oneAPI DevSummit content for more examples). Multiple customers are also testing code on current and upcoming Intel® Iris® Xe architecture-based GPUs, including the Argonne National Laboratory Aurora supercomputer, Leibniz Supercomputing Centre (LRZ), GE Healthcare*, and others.
Example: Migrating CUDA Vector Addition to SYCL
To provide a practical overview of the migration process, this article uses a simple implementation of vector addition in CUDA*. We take a closer look at the code that SYCLomatic generates. Mainly, we focus on the code sections where CUDA and SYCL differ the most. We’ll be using SYCLomatic and the Intel® oneAPI DPC++/C++ Compiler from the Intel® oneAPI Base Toolkit for the task at hand. To install the toolkit, follow the Intel® oneAPI installation guide. Use the following workflow to migrate your existing CUDA* application to SYCL*:
- Use the intercept-build utility to intercept commands issued by the Makefile and save them in a JSON-format compilation database file. This step is optional for single-source projects.
- Migrate your CUDA code to SYCL using SYCLomatic.
- Verify the generated code for correctness and complete the migration manually if warning messages indicate this explicitly. Check the Intel DPC++ Compatibility Tool Developer Guide and Reference to fix the warnings.
- Compile the code using the Intel oneAPI DPC++/C++ Compiler, run the program, then check the output.
You can then use Intel’s oneAPI analysis and debug tools, including Intel® VTune™ Profiler, to optimize your code further.
Let’s take vector addition as an example. Vector addition involves adding the elements from vectors A and B into vector C. A CUDA* kernel computes this as follows:
__global__ void vector_sum(const float *A,
const float *B,
float *C,
const int num_elements)
{
int idx = blockDim.x * blockIdx.x + threadIdx.x;
if (idx < num_elements) C[idx] = A[idx] + B[idx];
}
In CUDA, a group of threads is a thread block equivalent to a workgroup in SYCL; however, we compute thread indexing differently. In CUDA, we use built-in variables to identify a thread (See how we calculated the idx variable in the code above). Once migrated to SYCL, the same kernel looks like this:
void vector_sum(const float *A,
const float *B,
float *C,
const int num_elements,
sycl::nd_item<3> item_ct1)
{
int idx = item_ct1.get_local_range().get(2) *
item_ct1.get_group(2) +
item_ct1.get_local_id(2);
if (idx < num_elements) C[idx] = A[idx] + B[idx];
}
Like a CUDA thread, a work item in SYCL has a global identifier in a global space or a local identifier within a workgroup. We can get these identifiers from the nd_item variable. So, we no longer need to compute the global identifier explicitly. However, this demonstration shows how we do it in SYCL, so we see the similarities to CUDA’s built-in variables. Notice that nd_items are three-dimensional because of the dim3 type in CUDA. In this context, we can make nd_items one-dimensional. This action maps a work item to each element in the vector. To run a CUDA kernel, we must set the block size and how many blocks we need. In SYCL, we must define the execution range. As the code below shows, we do this with an nd_range variable that combines the global range and local range. The global range represents the total number of work items, while the local range is the size of a workgroup.
const int num_elements = 512;
dpct::device_info prop;
dpct::dev_mgr::instance().get_device(0).get_device_info(prop);
const size_t max_block_size = prop.get_max_work_group_size();
const size_t block_size = std::min<size_t>(max_block_size, num_elements);
range<1> global_rng(num_elements);
range<1> local_rng(block_size);
nd_range<1> kernel_rng(global_rng, local_rng);
To invoke our SYCL kernel, we use a parallel_for and the execution range to submit the kernel to a queue. Each work item invokes the kernel once. We have the same number of work items for each vector element in this context. Let’s see how this looks:
dpct::get_default_queue().parallel_for(kernel_rng, [=](nd_item<1> item_ct1)
{
vector_sum(d_A, d_B, d_C, num_elements, item_ct1);
});
So far, we’ve explored how to implement and run a kernel. However, before running the kernel, we need to think about memory allocation and copy the data to the device.
- First, we allocate memory for the operand vectors in the host and initialize them.
- Then, we do the same on the device. CUDA uses the cudaMalloc routine. By default, the DPCT migrates this routine to malloc_device, which uses unified shared memory (USM).
- Now, we use the memcpy command to copy the vectors from the host memory to the device.
After these steps, we run our kernel. Once the execution completes, we copy the result back to the host. We then check the result for correctness. Finally, we free the memory in the host and device by calling free and sycl::free, respectively.
Conclusion
The Khronos SYCL C++ standard is the open path for developing heterogeneous code that runs across multiple architectures. SYCLomatic, the new open-source project, provides the same CUDA to SYCL code migration benefits as the Intel DPC++ Compatibility Tool that came before it. And now, anyone can contribute to help improve and/or tune the tool to their needs. Give it a try today.
Resources for Developers
- Migrate from CUDA* to SYCL*
- CUDA* to SYCL* Application Catalog
- Data Parallel C++: Programming Accelerated Systems Using C++ and SYCL
- SYCLomatic project on GitHub | Contributing.md guide
- Comparing programming models: CUDA and SYCL
- Learn about SYCL
- oneAPI specification
- Intel oneAPI Toolkits
-
Intel® Developer Cloud: Accelerate AI development using Intel®-optimized software on the latest Intel® Xeon® processors and GPU compute.
See Related Content
Articles
- Migrate CUDA to DPC++ Using Intel® DPC++ Compatibility Tool
Read - CUDA, SYCL, Codeplay, and oneAPI: A Functional Test Walkthrough
Read - Migrating the Jacobi Iterative Method from CUDA to SYCL
Read - Free Your Software from Vendor Lock-in using SYCL and oneAPI
Read