There is an ever-growing number of accelerators in the world. This raises the question of how various ecosystems will evolve to allow programmers to leverage these accelerators. At higher levels of abstraction, domain-specific layers like TensorFlow* and PyTorch* provide great abstractions to the underlying hardware. However, for developers who maintain code that talks to the hardware without such an abstraction the challenge still exists. One solution that is supported on multiple underlying hardware architectures is C++ with SYCL*. Here is the description of SYCL from the Kronos Group webpage:
SYCL (pronounced ‘sickle’) is a royalty-free, cross-platform abstraction layer that enables code for heterogeneous processors to be written using standard ISO C++ with the host and kernel code for an application contained in the same source file.
This sounds pretty good assuming you:
- are comfortable learning a C++ like language
- want the flexibility of not being tied to your underlying hardware vendor
- you are starting your code from scratch
Since people who program at this level of the stack are already using C++, it is safe to say that the first assumption is reasonable and if you’re still reading, I’ll assume number two as well. However, the third point is very often not the case. For the rest of this story, we will discuss how to take a CUDA* code, migrate it to SYCL and then run it on multiple types of hardware, including an Nvidia* GPU.
To test how viable this is, we’ll be using a series of freely available tools including SYCLomatic, Intel® oneAPI Base Toolkit, and the Codeplay oneAPI for CUDA* compiler.
(See the Intel® DPC++ Compatibility Tool Release Notes and oneAPI for CUDA Getting Started Guide for information on supported CUDA versions for these tools.)
For reference, I’m using my personal Alder Lake system—Intel® Core™ i9 12900KF Alienware R13—with a 3080Ti GPU. My software stack is Windows* 11 Pro, and I’m developing in Ubuntu* 20.04 leveraging the Windows Subsystem for Linux* (WSL).
Migrating CUDA to SYCL
CUDA is often used to program for general-purpose computing on GPUs. The drawback is it only runs on Nvidia GPUs. To help migrate from CUDA to SYCL, we will be leveraging the Intel® DPC++ Compatibility Tool. (Note that Intel open-sourced the technology behind this tool to further advance the migration capabilities for producing more SYCL-based applications into the SYCLomatic project.)
There is already a nice write-up that is posted on both Stack Overflow and Intel® Developer Zone that walks through taking the jacobiCudaGraphs implementation from the cuda-samples GitHub repository and migrating the code, so rather than retype I’ll just link it here.
Note that if you just want to see how Codeplay’s oneAPI for CUDA compiler works for SYCL code, you can skip this tutorial and see the final code in the oneAPI-Samples repository on GitHub.
Testing SYCL on a variety of hardware
Once you have migrated to SYCL code, you should be able to run it on a variety of hardware. Let’s put it to the test, shall we? To make it easier to do this walkthrough, you can check out the oneAPI-samples directory which includes the migrated code already:
One minor note: In the oneAPI samples, the jacobi.h has an NROWS value of 1024 instead of 512. If you are using the pre-canned sample, you may want to manually update that for comparison purposes.
Here is the output when I follow the cuda-sample instructions to build and run the code:

SYCL on CPU
Intel provides a SYCL-based compiler in the oneAPI Base Toolkit, which is available here:
Because I’m using Ubuntu, I just followed the instructions to do an APT-based installation. Make sure to add the compiler paths to your workspace by running:
> source /opt/intel/oneapi/setvars.sh
I then went to the oneAPI-samples/DirectProgramming/DPC++/DenseLinearAlgebra/jacobi_iterative/sycl_dpct_migrated/src directory and compiled the code using the Intel DPC++ SYCL compiler:
> dpcpp -o jacobiSyclCPU main.cpp jacobi.cpp -I ../Common/
Note that the include of ../Common is from the SYCLomatic workflow, which creates some helper files to enable my migration from CUDA to SYCL. My executable file in this case is jacobiSyclCPU, so let’s give that a run:
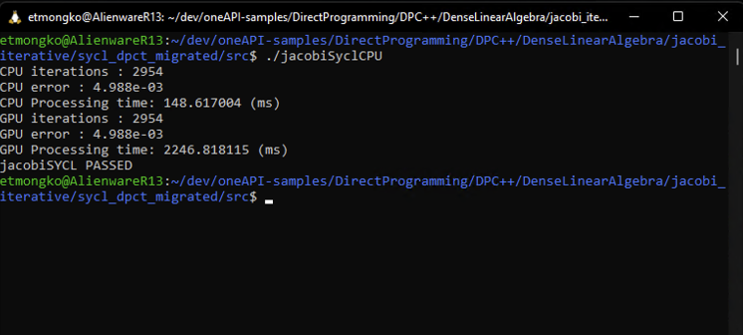
Looking at the output there are a couple things to consider:
- The SYCL version of the code is compiled with the Intel® oneAPI DPC++/C++ Compiler and the cuda-sample code is compiled with the GNU compiler.
- The migrated SYCL code, which is originally parallelized for the GPU, is now running on the CPU and is slower than the serialized version of the code. This is due to memory buffer setup and synchronization that is not required for the serialized version.
- The text “GPU ***” is incorrect because I just migrated the code and didn’t change the text to reflect that I’m targeting a CPU in this case.
SYCL on Nvidia GPU
Now that we’ve seen that we can run SYCL code on the CPU, let’s do something more interesting: Take the migrated code and see if we actually can run it on my GPU.
The first step was to install the oneAPI for CUDA compiler from Codeplay. I followed their instructions to install and build the compiler, inlined here for your convenience:
git clone https://github.com/intel/llvm.git -b sycl
cd llvm
python ./buildbot/configure.py --cuda -t release --cmake-gen “Unix Makefiles”
cd build
make sycl-toolchain -j `nproc`
make install
WSL2 Tip
A quick aside, while doing this installation I noticed it was running pretty slowly, a little bit of asking around and the issue was that I was running my compilation in WSL against a Windows filesystem instead of the WSL ext4 filesystem. Moving to the local filesystem made it exponentially faster, so good tip. For more details check out some WSL filesystem benchmarks here. It’s a bit older but still seems to be relevant.
Compiling and Running for CUDA
With my compiler installed, I am ready to compile to run on an Nvidia GPU. Due to how the migrated code was generated, I need to have include files from both the oneAPI DPC++/C++ Compiler and Codeplay’s compiler in my path:
> source /opt/intel/oneapi/setvars.sh
> export PATH=/home/etmongko/llvm/build/bin:$PATH
> export LD_LIBRARY_PATH=/home/etmongko/llvm/build/lib:$LD_LIBRARY_PATH
Now I run the Codeplay compiler to generate my CUDA-enabled binary:
> clang++ -fsycl -fsycl-targets=nvptx64-nvidia-cuda -DSYCL_USE_NATIVE_FP_ATOMICS -o jacobiSyclCuda main.cpp jacobi.cpp -I ../Common/
This generated the jacobiSyclCuda binary. Let’s give it a try!

Ugh. Not good.
Ouch! A Segmentation Fault is not a good start. The good news is that I found the issue with a little debugging. I had both oneAPI and the Codeplay libraries in my path, which caused some issues. To get around the issues, I opened a new terminal and simply ran:
> export LD_LIBRARY_PATH=/home/etmongko/llvm/build/lib:$LD_LIBRARY_PATH
to include just the Codeplay libraries. After this simple tweak, the SYCL code ran without any problem on my GPU.

It works!
Yay! We can see that the CPU time is similar to the baseline example. Additionally, the GPU portion is significantly faster than using the CPU, as in our second example. However, the performance is not quite on par with the native CUDA implementation … which isn’t unexpected because this was a simple migration from CUDA to SYCL without any optimizations.
Conclusion
C++ with SYCL code can be compiled and run on multiple backends. In this case we went through CPU and Nvidia GPU examples, but the beauty of SYCL is that it allows us to leverage other backends.
(Teaser: In my next blog I’ll be testing out developer workflows with a brand new laptop based on Intel® Arc™ A370M hardware, so we’ll see how SYCL enables multiple vendor backends.)
As a developer, I think alignment on hardware-agnostic solutions will eventually make our lives easier, we just need to get there. Migrating from CUDA to SYCL is not trivial, but there is a lot of community support around it and the tools are continually getting better.
Wouldn’t it be nice if as new hardware came out you could run your code on it if it happened to be faster or more power-efficient or more cost-effective? That’s a question for another time and discussion, but it is a nice thought.
Want to Connect? If you want to see what random tech news I’m reading, you can follow me on X (formerly Twitter).
Discover More Related Content
Blogs
On-Demand Webinars
- Scale C++ Applications Efficiently with TBB Concurrent Containers
- Intel® MPI Library Boosts Performance & Supports Container & Cloud
- Tips to Improve Heterogeneous Application Performance
Get the Software
Get started with this core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures.