The use of accelerators is increasing every year, with software developers taking advantage of GPUs in particular to run a variety of HPC and AI algorithms on highly parallel systems. The data center accelerator market is projected to grow from $13.7 billion in 2021 to $65.3 billion by 2026 according to research from MarketsandMarkets1.
During the past decade or so software developers have largely been bound to CUDA* to write highly parallel software that can make use of GPUs that, whilst originally designed for graphics processing, are now being used in a wide range of disciplines that include AI and machine learning. The challenge with this approach for software developers is that CUDA is a proprietary programming interface and can only be used to run on processors from NVIDIA. This ties organizations into a single vendor and limits the ability to innovate with the latest processor architectures.
The market is changing and there is increasing choice from a wide range of processor vendors including Intel (especially with the upcoming Intel® Iris® Xe GPU), and new specialized processors such as those harnessing the RISC-V instruction set architecture. Software developers need to be able to not only take maximum advantage of the existing processor targets but also adapt and capitalize on this explosion of new architectures and innovations; but how is this possible without writing new code for each of these new processors from different vendors?
This is where SYCL* and oneAPI offer a flexible and non-proprietary alternative. SYCL is an industry defined, royalty free, open standard interface for writing software that runs on highly parallel processor targets. SYCL is already widely adopted; it is being used to enable performance portability on some of the fastest supercomputers in the world. Argonne, Lawrence Berkeley and Oak Ridge National Laboratories in the United States are using SYCL to enable their researchers to write software that can be run on Aurora (using Intel® GPUs), Perlmutter, Polaris, Summit (using NVIDIA GPUs), and Frontier (using AMD GPUs) supercomputers whilst achieving the best performance. In Europe, the team porting GROMACS to the Lumi supercomputer chose SYCL as their programming model with a view to enabling performance portability with existing and future machines across the continent. Other government and commercial organizations are using SYCL to deploy complex software to their multi-vendor systems.
SYCL sits at the heart of oneAPI, an open and standards-based programming environment for accelerator architectures. oneAPI defines and implements a set of commonly used libraries and frameworks that enable highly parallel software to run with performance and portability across architectures. oneAPI includes libraries for common math and neural network algorithms alongside the building blocks required to write highly optimized applications. Together this provides software developers with everything they need to write HPC and AI applications.
You may be thinking, SYCL sounds great but how difficult is it going to be to move all my code from CUDA to SYCL? To understand how straightforward it is, let’s walk through an N-body simulation project we have been working on and demonstrate how to migrate this from CUDA to SYCL.
An N-body simulation is used to show gravitational interaction in a fictional galaxy using a defined set of equations (Figure 1). This project is based on an existing open-source N-body simulation written by Sarah Le Luron using C++. This code was adapted to implement a kernel to run some of the simulation calculations in parallel on an NVIDIA GPU, helping to achieve a faster execution time compared to running on a CPU.

Figure 1. N-body simulation of a fictional galaxy.
How do we port this kernel code to SYCL? Whilst this project has a single kernel, other applications may have hundreds of CUDA kernels in a code base, and this next step will remove a lot of the heavy lifting and save significant development time.
The first step involves using the recently open-sourced SYCLomatic tool, which provides a semi-automated way to port CUDA to SYCL. Given one or more CUDA source files, it converts the source code to SYCL. Simply tell the tool what source files need to be converted and it will produce a C++ source file containing the ported code. Figure 2 shows how simple the steps are at this stage using the intercept-build script. This tracks and saves the commands and flags in a JSON file which is useful for projects with multiple source files. By pointing the tool at the source files that need to be ported it produces a set of SYCL code files alongside some helper classes and functions that are used to simplify the porting at this stage.

Figure 2. SYCLomatic workflow.
Let’s look at some of the code that SYCLomatic generates (Figure 3). This comparison shows a portion of the code that was converted by the tool. One of the changes made is to the built-in square root method. This is a simple translation from the CUDA version to the SYCL equivalent. You can also see that the tool generates comments that help to give the developers guidance and hints on further changes that you might need to make to optimize or ensure accuracy in your application. There are other changes to the kernel code that can be examined in the project repository. It’s worth noting that for this N-body project no further changes were required to the SYCLomatic-generated source code. This demonstrates the effectiveness of this tool, but it’s worth understanding that usually developers will need to do some level of manual code changes for their project.
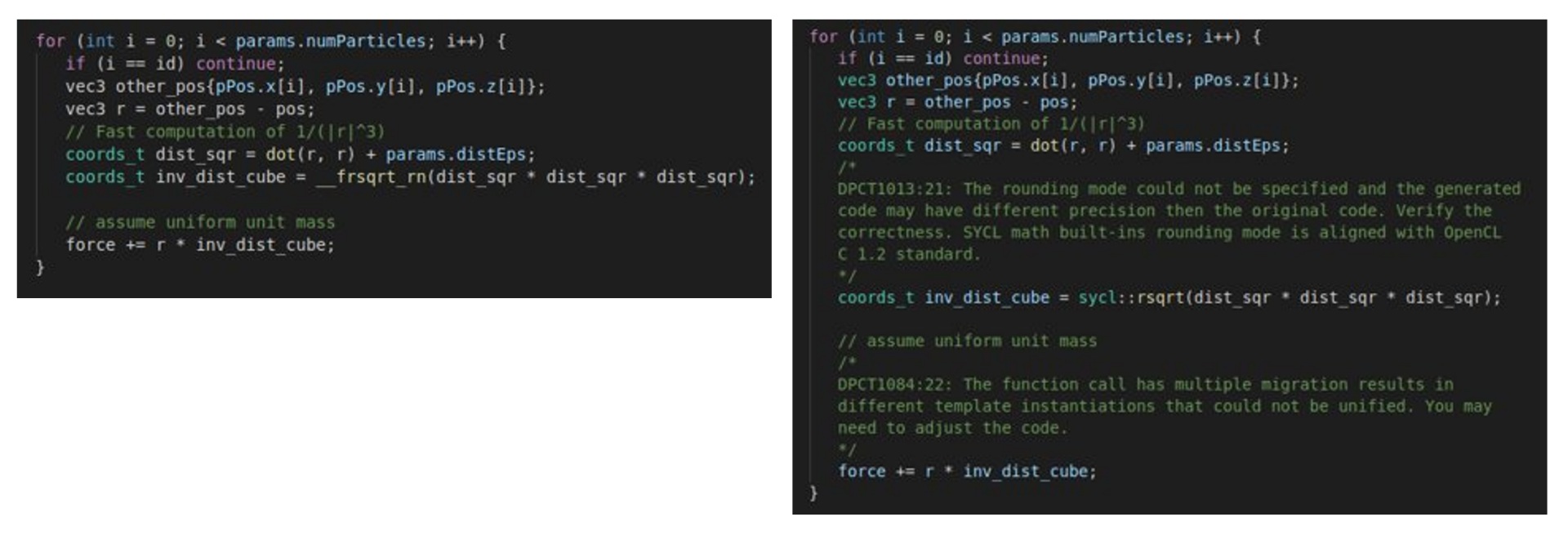
Figure 3. Converting CUDA* (left) to SYCL* (right) using SYCLomatic.
Now that the porting is done, it’s possible to run this SYCL code on a range of processors. Let’s focus on using an NVIDIA GPU target with the DPC++ compiler. DPC++ is an open-source SYCL compiler that is part of the oneAPI initiative. It includes support for Intel processors, NVIDIA GPUs and AMD GPUs. There are instructions on how to set up your environment to use the NVIDIA and AMD targets on the Codeplay website and open source DPC++ repository.
Running the N-body simulation using CUDA and SYCL on the same NVIDIA hardware shows comparable performance (Figure 4). Running the CUDA and SYCL versions of this N-body simulation on the same NVIDIA GeForce* GPU demonstrates it is possible to achieve comparable performance using either native CUDA or SYCL. The times in the images show the kernel time for the N-body gravity simulation is close, and in this instance the SYCL version is slightly faster compared to the native CUDA code. It’s worth noting that your mileage will vary but there are examples across both research and commercial organizations that show performance results using SYCL that closely match CUDA. See the Zuse Institute Berlin’s video presentation showing how their Tsunami simulation code was able to achieve this.
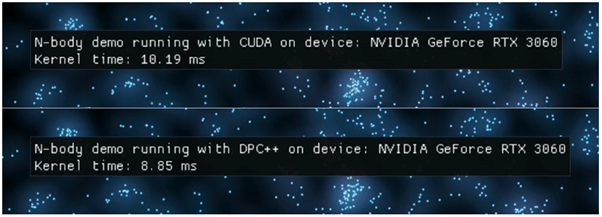
Figure 4. The original CUDA* N-body code (top) and the converted SYCL* code (bottom) give comparable performance.
Whilst performance portability is achievable with SYCL on NVIDIA GPUs using DPC++ there will be times when it’s necessary to figure out where your code needs to be fine-tuned to bring out the best from the hardware. Alongside the ability to run SYCL code on NVIDIA hardware, it’s also possible to enjoy the benefits of the NVIDIA profiling tooling including NVIDIA Nsight* (Figure 5). Without any code or configuration changes, these same familiar tools can be used to help you fine tune and optimize your application to get the absolute best performance.

Figure 5. NVIDIA Nsight* can be used to profile SYCL* applications when using the CUDA* backend
By examining the information from these tools, it is possible to track down kernel and memory optimizations making it easier to pinpoint the area of your code to focus on. If you are wanting to get into the very fine details, it’s also possible to examine the generated low-level PTX instructions using the compiler output. What this means is that developers can use the tools most suitable for their target architecture using SYCL, whether that’s NVIDIA’s Nsight for NVIDIA GPUs or Intel® VTune™ for Intel® platforms. The path from CUDA to SYCL is not as daunting as it seems, and the benefits are clear to see. Code written with SYCL enables a future-proofed software development environment allowing software development teams to target existing accelerator processors, such as those from Intel, NVIDIA, and AMD, and be ready to adopt the latest architectures such as novel RISC-V based accelerators.
Take some time to examine the open-source N-body project code we have developed, use SYCLomatic to port your CUDA code to SYCL and future-proof your software for the next generation of processors.