Intel® Innovation 2022 inspired me to write this blog. I will highlight how easy it is to migrate from CUDA's proprietary and GPU-centric programming model to the open standards driven SYCL C++ language extension using SYCLomatic.
The Starting Point
During the past decade or so, GPUs have moved away from their original purpose of being dedicated to graphics processing and accelerating software for AI and HPC domains. The latest supercomputers across the world, such as the ones being installed by the US Department of Energy, are using accelerators, including GPUs, to bring exascale performance to researchers. In fact, organizations around the world are now using accelerators to bring huge performance gains to their software.
The good news for software developers is that there is a growing number of accelerators from multiple organizations around the world, with increasingly targeted architectures for specific domains, in particular AI and machine learning.
The challenge is that many existing software projects are using proprietary programming models such as CUDA*. Not only is CUDA very much focused on specific GPU architectures, it also limits your code to run only on Nvidia GPUs. This severely limits the choice you have when looking at target architectures for your projects.
The Solution
We have a straightforward solution that brings developers an open standard and open-source alternative to CUDA. It opens the possibility of deploying your software on architectures that include accelerators from multiple vendors.
This solution is SYCL*, a programming model that has been around for several years, is managed by the Khronos group, and is defined by a cross-industry group of experts using a democratic process. SYCL is implemented using only standard C++, unlike CUDA, so you can write your code using the features and syntax you already recognize.
What SYCL brings you is choice: the choice of what processors you want to target now, and those you want to target in the future. What’s more, the Intel® oneAPI DPC++/C++ Compiler is an open-source implementation of SYCL, based on the LLVM* compiler project that enables you to target GPUs from Intel, Nvidia, and AMD.
Straightforward Code Migration
If I have convinced you to give it a go, the migration of code from CUDA to SYCL is made straightforward through flexible porting mechanisms.
I’ll talk about what I call the semi-automatic method. We have developed an open-source example project that implements an nbody simulation and demonstrates performance portability using SYCL. The nbody project implements a well-known formula that simulates a fictional galaxy, and it includes everything you need to rapidly try out the migration for yourself, including original CUDA source and scripts.
The open source SYCLomatic project provides a tool that takes CUDA code and automatically migrates it to SYCL code. This maybe sounds a bit too good to be true … but it isn’t. You can expect the tool to migrate around 90% of your code, leaving only a little work to do yourself.
Let me walk through the steps to migrate a CUDA implementation of the nbody simulation using SYCLomatic.
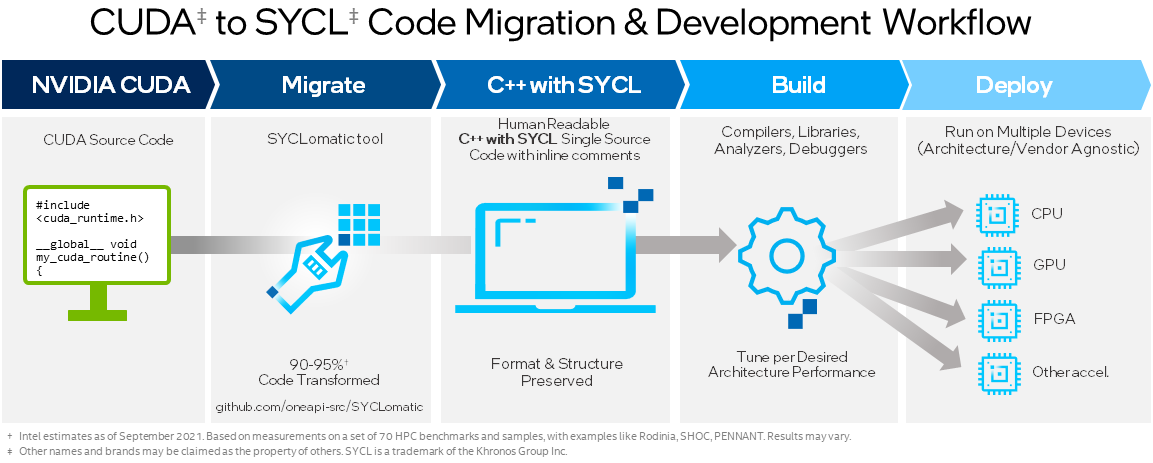
Figure 1. SYCL Migration Process Flow
Step 1
The first step we need to do is to figure out what code we want the SYCLomatic tool to migrate. In this example, the “simulator.cu” file is where our CUDA kernel lives and it’s the only file we need to provide. We give the command and the source file location to kick things off and pass a couple of flags.
If you are wondering what the command is, it’s ‘c2s’ which stands for CUDA 2 SYCL!
It’s possible to run the tool on either a single file or on multiple files if your project includes many CUDA kernels in different files. You even can use your make file integration to ensure all relevant files are selected.
Step 2
Once the c2s script has completed, you’ll almost certainly see a list of warnings. It’s not too important that you read through these on the command line since SYCLomatic inserts these warnings into the migrated code. You can go straight to the converted code and have a look in the source files for any warnings SYCLomatic has inserted.
A common warning you will see is related to the difference in the way that CUDA and SYCL handle errors and exceptions:
- In CUDA, errors are returned from many function calls, such as a memory copy or synchronization.
- In SYCL, errors are handled using exceptions.
The warnings will tell you where you might need to make sure you have an exception handler implemented to catch any problems that might occur.
You will most likely see some other places in the migrated code where the SYCLomatic tool was not quite sure what to do. That’s fine—after all, we humans sometimes need some help to write our code. The good news is that SYCLomatic inserts comments in the code to explain why it thinks you need to take a closer look at that particular part of the code. It sometimes even suggests the solution.
Real-World Example
The short video excerpt from the presentation and demo we provided at Innovation 2022 walks you through a simple real-world example illustrating the ease of porting:
The NBody GitHub* Project
Step 3
Once you’ve completed your migration, you can compile your new SYCL code using the Intel oneAPI DPC++/C++ Compiler. If you have enabled the Nvidia target for DPC++, you can still run your code on an Nvidia GPU and also compile for Intel® processors and also AMD’s using oneAPI for AMDGPUs.
What’s more, when we run the CUDA and SYCL nbody code on the same hardware, the performance is similar; thus, the only thing you lose is closed proprietary code in your software.
If you want to see how simple the migration process is, do this:
- Clone the NBody GitHub project
- Use the script to load in a Docker container
- Run the conversion …
- … and you’ll find out how easy it really is to migrate from CUDA to SYCL.
Additional Innovation 2022 Resources:
Next Steps
Check out how oneAPI fits into your next heterogeneous software development project.
Give it a try and let us know whether this approach to easy migration from CUDA to SYCL works for you. Check out the SYCLomatic GitHub Repository and the Migrate from CUDA to C++ with SYCL Guide.
Get the Software
Test it for yourself today by downloading and installing the Intel® oneAPI Base Toolkit with Priority Support for that extra level of in-depth professional support and guidance.
In addition to these download locations, they are also available through partner repositories. Detailed documentation is also available online.
See Related Content
On-demand Webinars & Workshops
- Advanced SYCL Concepts for Heterogenous Computing
- Learn Heterogeneous C++ with SYCL
- Advanced SYCL* Concepts for Heterogeneous Computing
Podcast
Tech Articles
- Free Your Software from Vendor Lock-in using SYCL and oneAPI
- SYCLomatic: A New CUDA-to-SYCL Code Migration Tool
- CUDA, SYCL, Codeplay, and oneAPI: A Functional Test Walkthrough
- The Case for SYCL: ISO C++ Is Not Enough for Heterogeneous Compute
Get the Software
Intel® oneAPI Base Toolkit
Get started with this core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures.