A newer version of this document is available. Customers should click here to go to the newest version.
Optimize Inner Loop Throughput
In this topic, you learn how to optimize throughput of an inner loop with a low trip count. A low trip count is relative. For understanding the concept, consider low to be on the order of 100 or fewer iterations.
Prior to reading the rest of this topic, you must review Maximum Frequency (fMAX) and Optimize Loops With Loop Speculation.
Consider the following example code snippet:
for (int i; i < kOuterLoopBound; i++) {
int inner_loop_iterations = rand() % kInnerLoopBound;
for (int j; j < inner_loop_iterations; j++) {
/* ... */
}
}Before you optimize the inner loops with low trip counts, assume the following:
- kOuterLoopBound is a number greater than one million.
- kInnerLoopBound is 3. This means that the value of inner_loop_iterations is dynamic, but you know that it is in the range (0,3).
- II of the inner loop is 1, which means that a new inner loop iteration can start every cycle. This means that the outer loop II is dynamic and depends on how many inner loop iterations the previous outer loop iteration must start.
A possible timing diagram for this loop structure is shown in the following figure, where the numbers in the squares are the values of i and j, respectively:
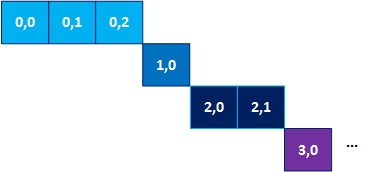
In general, the Intel® oneAPI DPC++/C++ Compiler optimizes loops for throughput with the assumption that the loop has a high trip count. These optimizations include (but are not limited to) speculating iterations and inserting pipeline registers in the circuit that starts loops. The next two sections describe how these optimizations can substantially decrease throughput and how you can disable them to improve your design when applied to inner loops with low trip counts.
Speculated Iterations
Loop Speculation enables loop iterations to be initiated before determining whether they should have been initiated. Speculated iterations are the iterations of a loop that launch before the exit condition computation has been completed. This is beneficial when the computation of the exit condition is preventing effective loop pipelining. However, when an inner loop has a low trip count, speculating iterations result in a relatively high proportion of invalid loop iterations.
For example, consider that the compiler speculated two inner loop iterations for the code above. In that case, the timing diagram appears as shown in the following diagram, where the orange blocks with the S denote an invalid speculated iteration:
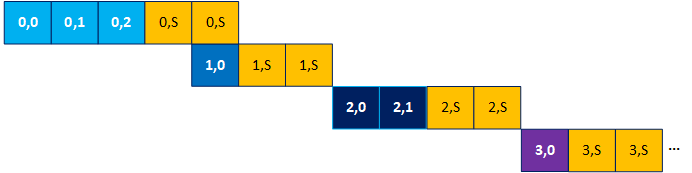
In this case where the inner loop iteration count is in the range (0,3), speculating two iterations can cause up to a 3x reduction in the design's throughput. This happens when each outer loop iteration launches one inner loop iteration (inner_loop_iterations is always 1), but two iterations are speculated. For this reason, Intel® advises to force the compiler to not speculate iterations for inner loops with known small trip counts using the [[intel::speculated_iterations(0)]] attribute.
Dynamic Trip Counts
As mentioned earlier, the compiler's default behavior is to optimize loops for throughput. However, as you saw in the previous section, loops with low trip counts have unique throughput characteristics that lead to the compiler making different optimizations. The compiler attempts its best to determine if a loop has a high or low trip count and optimizes accordingly. However, in some circumstances, you may need to provide it with more information to make a better decision.
In the previous section, this additional information was the speculated_iterations attribute. However, it is not just speculated iterations that cause delays in the launching of inner loops. The compiler uses other heuristics. For example, the compiler may attempt to improve the fMAX of a loop circuit by adding a pipeline register on the circuit path that starts a loop, which results in a one-cycle delay in starting the loop. For outer loops with large trip counts, this one cycle delay is negligible. However, for inner loops with small trip counts, this one cycle delay can cause throughput degradation. Like the speculated iteration case discussed in the previous section, this one cycle delay can result in up to a 2x reduction in the design's throughput.
If the inner loop bounds are known to the compiler, it decides whether to turn on/off this delay register depending on the (known) trip count. However, in the code snippet above, the inner loop's trip count is not a constant (inner_loop_iterations is a random number at runtime). In cases like this, Intel recommends explicitly bounding the trip count of the inner loop. This is illustrated in the example code snippet in the following, where j < kInnerLoopBound exit condition is added to the inner loop. This gives the compiler more explicit information about the loop's trip count and allows it to optimize accordingly.
for (int i; i < kOuterLoopBound; i++) {
int inner_loop_iterations = rand() % kInnerLoopBound;
for (int j; j < inner_loop_iterations && j < kInnerLoopBound; j++) {
/* ... */
}
}