A newer version of this document is available. Customers should click here to go to the newest version.
Improve fMAX/II with Shannonization
Shannonization (named after Claude Shannon) is a loop optimization technique that improves the fMAX/II of a design by precomputing operations in a loop and removing the operations from the critical path. To demonstrate shannonization, consider the following example, which counts the number of elements in an array A that are less than some runtime value v:
int A[SIZE] = {/*...*/};
int v = /*some dynamic value*/
int c = 0;
for (int i = 0; i < SIZE; i++) {
if (A[i] < v) {
c++;
}
}A possible circuit diagram for this algorithm is shown in the following image, where the orange dotted line represents a possible critical path in the circuit:
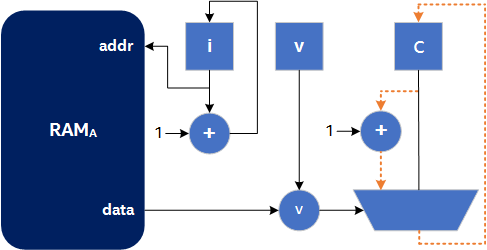
The goal of the shannonization optimization is to remove operations from the critical path. In this case, precompute the next value of c (fittingly named c_next) for a later iteration of the loop to use when required (that is, the next time A[i] < v). This optimization is shown in the following code sample:
int A[SIZE] = {/*...*/};
int v = /*some dynamic value*/
int c = 0;
int c_next = 1;
for (int i = 0; i < SIZE; i++) {
if (A[i] < v) {
// these operations can happen in parallel!
c = c_next;
c_next++;
}
}A possible circuit diagram for this optimized algorithm is shown in the following image, where the orange dotted line represents a possible critical path in the circuit:
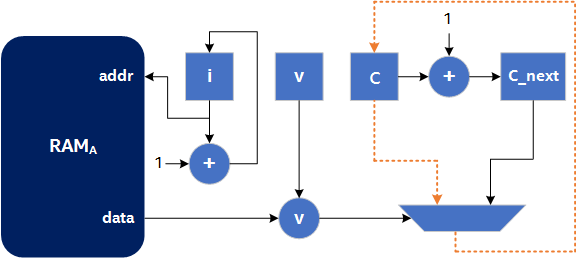
In the Figure 2, the + operation from the critical path is removed. This diagram assumes that the critical path delay through the multiplexer is higher than through the adder. This may not be the case, and the critical path could be from the c register to the c_next register through the adder, in which case, the multiplexer from the critical path is removed. Regardless of which operation has the longer critical path delay (the adder or the multiplexer), an operation from the critical path is removed by precomputing and storing the next value of c. This allows in reducing the critical path delay at the expense of area (in this case, a single 32-bit register).