A newer version of this document is available. Customers should click here to go to the newest version.
Mapping Source Code Instructions to Hardware
Based on your source code and the following principles, the Intel® oneAPI DPC++/C++ Compiler builds a custom hardware datapath in the FPGA’s logic:
- The datapath is functionally equivalent to the C++ program described by the source. Once the datapath is constructed, the compiler orchestrates work items and loop iterations such that the hardware is effectively occupied.
- The compiler builds the custom hardware datapath while minimizing the area of the FPGA resources (ALMs, DSPs, and so on) used by the design.
Mapping Operations to Hardware
For fixed architectures such as CPUs and GPUs, the source code is compiled by the compiler into a set of instructions that run on functional units with a fixed functionality. For these fixed architectures to be useful in a broad range of applications, some of their available functional units are not useful to every program. Unused functional units mean that your program does not fully occupy the fixed architecture hardware.
FPGAs are not subject to these restrictions of fixed functional units. On an FPGA, you can synthesize a specialized hardware datapath that can be fully occupied for an arbitrary set of instructions, which means you can be more efficient with the chip's silicon area.
By implementing your algorithm in hardware, you can fill your chip with custom hardware that is always (or almost always) working on your problem instead of having idle functional units.
The Intel® oneAPI DPC++/C++ Compiler maps statements from the source code to individual specialized hardware operations, as shown in the example in the following image:
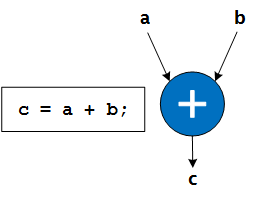
In general, each instruction maps to its own unique instance of a hardware operation. However, a single statement may map to more than one hardware operation, or multiple statements may combine into a single hardware operation when the compiler finds that it can generate more efficient hardware.
The latency of hardware operations is dependent on the complexity of the operation and the target fMAX.
The compiler then takes these hardware operations and connects them into a graph based on their dependencies. When operations are independent, the compiler automatically infers parallelism by executing those operations simultaneously in time.
The following figure illustrates a dependency graph created for the hardware datapath:

The dependency graph illustrates how the instruction is mapped to hardware operations and how the hardware operations are connected based on their dependencies. The loads in this example instruction are independent of each other and can therefore run simultaneously.
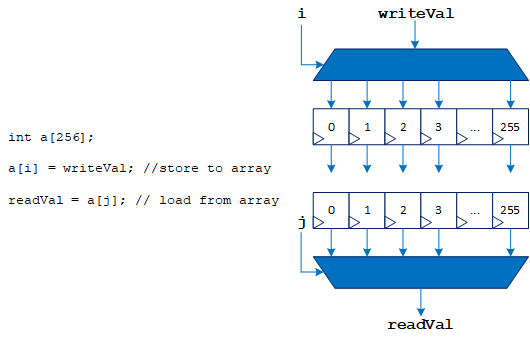
Mapping Arrays and Their Accesses to Hardware
Similar to mapping statements to specialized hardware operations, the compiler maps arrays to hardware memories based on memory access patterns and variable sizes. The datapath interacts with this memory through load/store units (LSUs), which are inferred from array accesses in the source code.
The following figure illustrates a simple example of mapping arrays and their accesses to hardware:
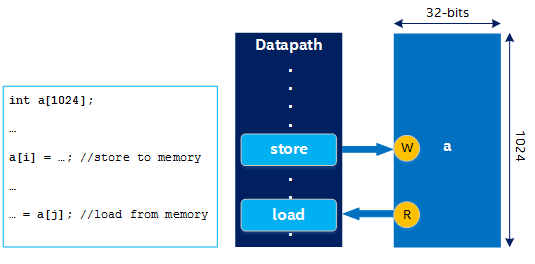
A RAM can have a limited number of read ports and write ports, but a datapath can have many LSUs. When the number of LSUs does not match the available number of read and write ports, the compiler uses techniques like replication, double-pumping, sharing, and arbitration. For more information, refer to Kernel Memory.
FPGAs provide specialized hardware block RAMs that you can configure and combine to match the size of your arrays. Doing so can provide many terabytes per second of on-chip memory bandwidth because each of these memories can interact with the datapath simultaneously.
Arrays might also be implemented in your kernel datapath. In this case, the array contents are stored as registers in the datapath when your algorithm is pipelined (as discussed in Pipelining). Storing array contents as registers in the datapath can improve performance in some cases, but it is a design decision whether to implement an array as registers or as memories.
When you access an array that is implemented as registers, LSUs are not used. The compiler might choose to use a select or a barrel shifter instead.