A newer version of this document is available. Customers should click here to go to the newest version.
Model Offloading to a GPU
Find high-impact opportunities to offload/run your code and identify potential performance bottlenecks on a target graphics processing unit (GPU) by running the Offload Modeling perspective.
The Offload Modeling perspective can help you to do the following:
- For code running on a CPU, determine if you should offload it to a target device and estimate a potential speedup before getting a hardware.
- For code running on a GPU, estimate a potential speedup from running it on a different target device before getting a hardware.
- Identify loops that are recommended for offloading from a baseline CPU to a target GPU.
- Pinpoint potential performance bottlenecks on the target device to decide on optimization directions.
- Check how effectively data can be transferred between host and target devices.
With the Offload Modeling perspective, the following workflows are available:
- CPU-to-GPU offload modeling:
- For C, C++, and Fortran applications: Analyze an application and model its performance on a target GPU device. Use this workflow to find offload opportunities and prepare your code for efficient offload to the GPU.
- For SYCL, OpenMP* target, and OpenCL™ applications: Analyze an application offloaded to a CPU and model its performance on a target GPU device. Use this workflow to understand how you can improve performance of your application on the target GPU and check if your code has other offload opportunities. This workflow analyzes parts of your application running on host and offloaded to a CPU.
- GPU-to-GPU offload modeling for SYCL, OpenMP target, and OpenCL applications: Analyze an application that runs on a GPU and model its performance on a different GPU device. Use this workflow to understand how you can improve your application performance and check if you can get a higher speedup if you offload the application to a different GPU device.
How It Works
The Offload Modeling perspective runs the following steps:
- Get the baseline performance data for your application by running a Survey analysis.
- Identify the number of times kernels are invoked and executed and the number of floating-point and integer operations, estimate cache and memory traffics on target device memory subsystem by running the Characterization analysis.
- Mark up loops of interest and identify loop-carried dependencies that might block parallel execution by running the Dependencies analysis (CPU-to-GPU modeling only).
- Estimate the total program speedup on a target device and other performance metrics according to Amdahl's law, considering speedup from the most profitable regions by running Performance Modeling. A region is profitable if its execution time on the target is less than on a host.
The CPU-to-GPU and GPU-to-GPU modeling workflows are based on different hardware configurations, compilers code-generation principles, and software implementation aspects to provide an accurate modeling results specific to the baseline device for your application. Review the following features of the workflows:
CPU-to-GPU modeling |
GPU-to-GPU modeling |
|---|---|
Only loops/functions executed or offloaded to a CPU are analyzed. |
Only GPU compute kernels are analyzed. |
Loop/function characteristics are measured using the CPU profiling capabilities. |
Compute kernel characteristics are measured using the GPU profiling capabilities. |
Only profitable loops/functions are recommended for offloading to a target GPU. Profitability is based on the estimated speedup. |
All kernels executed on GPU are modeled one to one, even if they have low speedup estimated. |
High-overhead features, such as call stack handling, cache and data transfer simulation, dependencies analysis, can be enabled. You might need to run the Dependencies analysis to check if loop-carried dependencies affect performance on a GPU. |
High-overhead features, such as call stack handling, cache and data transfer simulation, dependencies analysis, are disabled. You do not need to run the Dependencies analysis. |
Data transfer between baseline and target devices can be simulated in two different modes: footprint-based and memory object-based. |
Memory objects transferred between host and device memory are traced. |
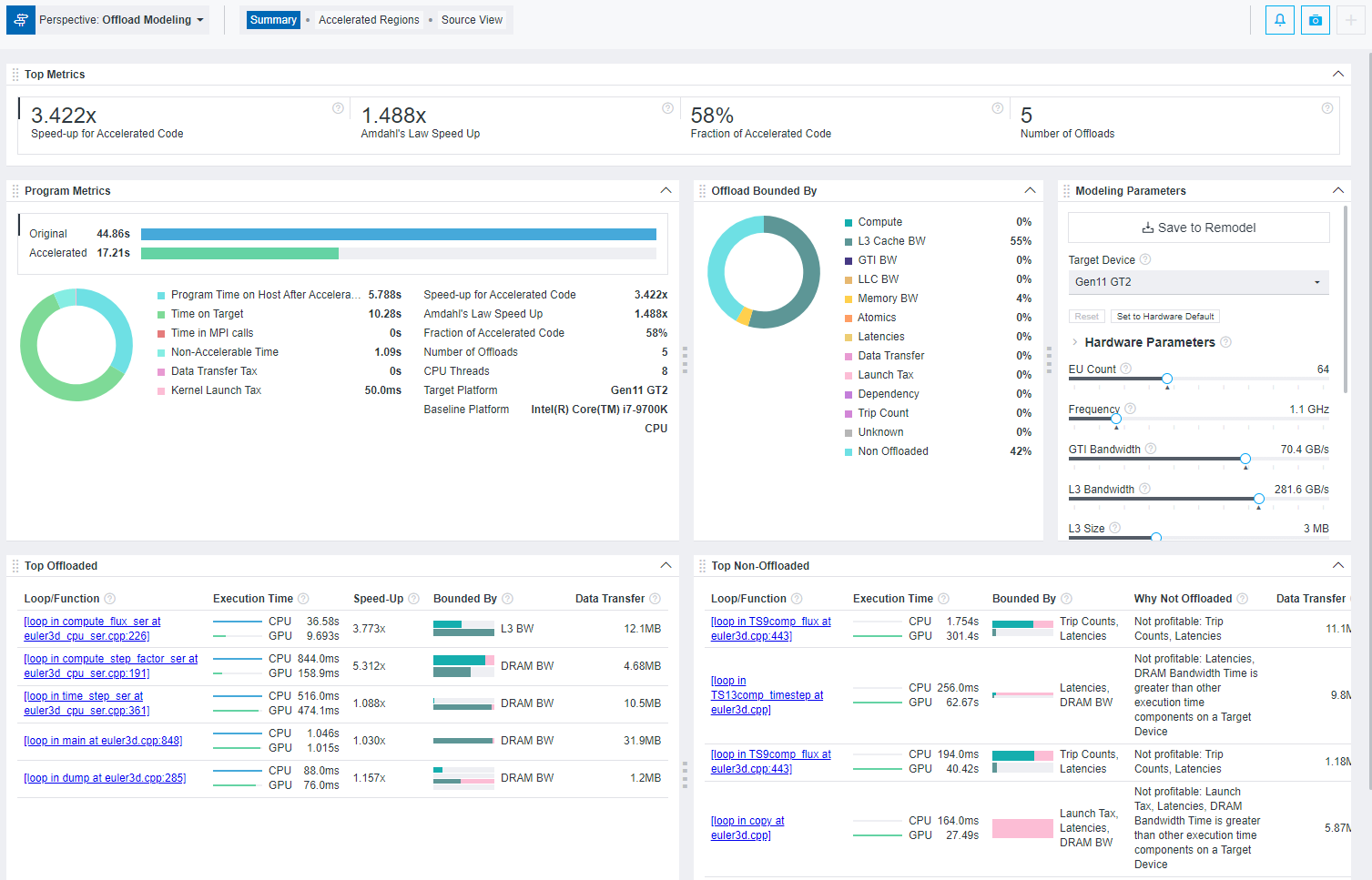
Offload Modeling Summary
Offload Modeling perspective measures performance of your application and compares it with its modeled performance on a selected target GPU so that you can decide what parts of your application you can execute on the GPU and how you can optimize it to get a better performance after offloading.
- Main metrics for the modeled performance of your program indicating if you should offload your application hotspots to a target device or not
- Specific factors that prevent your code from achieving a better performance if executed on a target device (the factors that your code is bounded by)
- Top offloaded loops/functions that provide the highest benefit (up to five)
- For the CPU-to-GPU modeling: Top non-offloaded loops/functions (up to five) with reasons why a loop is not offloaded