A Practical Guide
Bei Wang, high-performance computing (HPC) software engineer, Princeton University; Carlos Rosales-Fernandez, software technical consulting engineer, Intel Corporation; and William Tang, professor, Princeton Plasma Physics Laboratory
@IntelDevTools
The basic particle method is a well-established approach to simulating the behavior of charged particles interacting with each other through pairwise electromagnetic forces. At each step, the particle properties are updated according to these calculated forces. For applications on powerful modern supercomputers with deep cache hierarchies, a pure particle method is efficient with respect to both locality and arithmetic intensity (compute-bound).
Unfortunately, the O(N2) complexity makes a particle method impractical for plasma simulations using millions of particles per process. Instead of calculating O(N2) forces, the particle-in-cell (PIC) method uses a grid as the medium to calculate long-range electromagnetic forces. This reduces the complexity from O(N2) to O(N + M log M), where M is the number of grid points, generally much smaller than N. However, achieving high parallel and architectural efficiency is a significant challenge for PIC methods due to the gather/scatter nature of the algorithm.
Attaining performance becomes even more complex as HPC technology moves to the era of multicore and many-core architectures with increased thread and vector parallelism on shared-memory processors. A deep understanding of how to improve the associated scalability has a wide-ranging influence on numerous physical applications that use particle-mesh algorithms―including molecular dynamics, cosmology, accelerator physics, and plasma physics.
This article is a practical guide to improving performance by enabling vectorization for PIC codes.
Optimization for PIC Codes
The code example for this demonstration is the particle class in Athena++, an astrophysical magnetohydrodynamics (MHD) code written in C++ .1 The particle class encapsulates basic data structures and functions in PIC methods. Particle properties are represented by phase space position―that is, physical space position (x1, x2, x3) and velocity (v1, v2, v3). The class functions implement three essential particle-based operations in PIC methods:
- Deposit: Charge deposition from particles onto grid
- Move: Interpolation of grid-based fields onto particles and updating of particle properties using the fields
- Shift: Move particles among processes in the distributed environment. Usually, deposit and move take 80% to 90% of the total computational time and are the focus for optimizations.
Data Layout and Alignment
Particle properties can be stored as array-of-structures (AoS) or structure-of-arrays (SoA) data layout (Figure 1).
AoS helps to pack and unpack particles for shift, but doesn’t help to enable vectorization for deposit and move with stride-one memory access. Since deposit and move are the hot spots of the code, choose SoA data layout for particle representation. Specifically, allocate the memory with alignment using the posix_memalign() function (Figure 2).
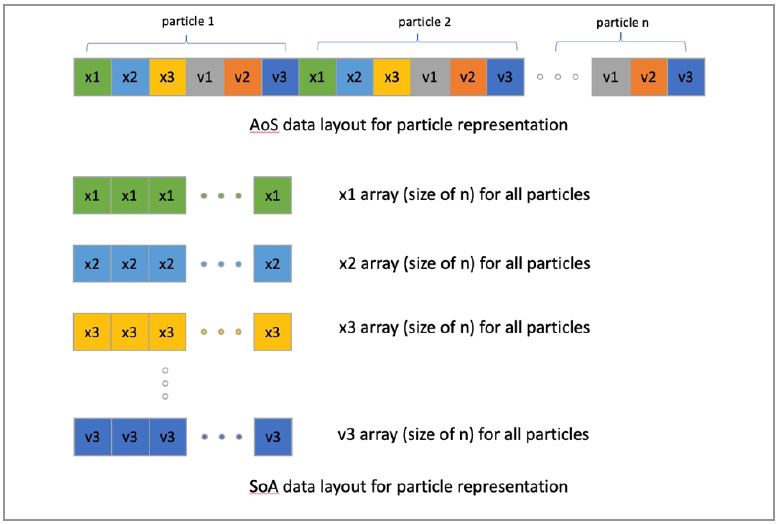
Figure 1. Particle representation using AoS and SoA layout

Figure 2. Allocate the memory with alignment using the posix_memalign() function
Start the optimization by checking the vectorization report of the original code for deposit.cpp and move.cpp (Figure 3).

Figure 3. Original code for deposit.cpp (left) and move.cpp (right)
Compile the code with the Intel® C++ Compiler v19.0 and the following options: -O3 -g -qopt -report5 -xCORE-AVX512 -qopenmp simd. By default, the compiler vectorizes the innermost loop for both deposit (L106) and move (L121). The vectorization report shows that the compiler fails to do so because of a potential data dependency in deposit.cpp (Figure 4) and efficiency reasons in move.cpp (Figure 5).

Figure 4. Vectorization report for deposit.cpp
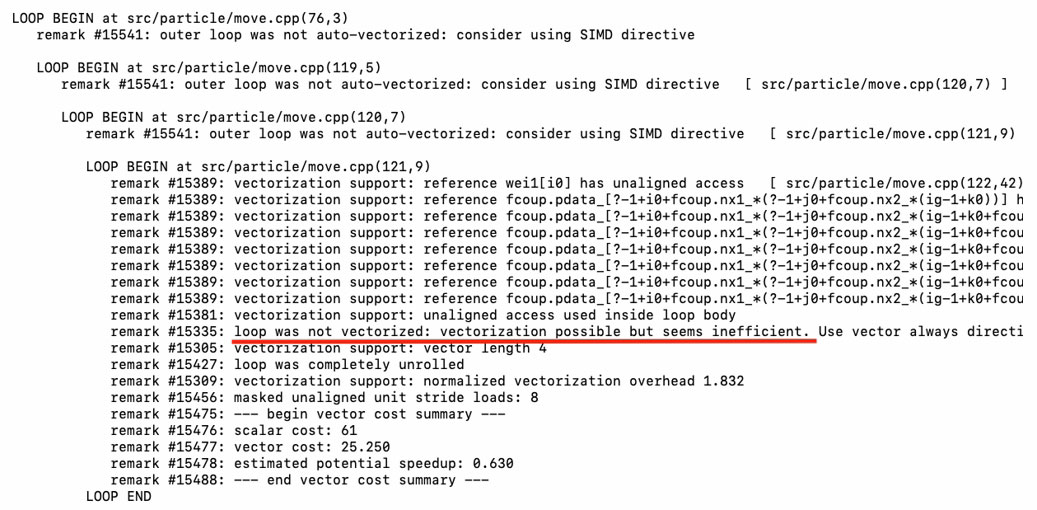
Figure 5. Vectorization report for move.cpp
Explicit Single Instruction Multiple Data (SIMD) via OpenMP* Directives
For both deposit and move, the loop count for the outermost loop (for example, nparticle loop) is large, while the loop count for the innermost loop is small. So, the outermost loop is a more suitable candidate for vectorization. The first attempt is to enable vectorization for the outermost loop in deposit and move using OpenMP* SIMD directives. For both kernels, there’s no data dependency with respect to pointer aliasing. In considering vectorization for deposit in the outermost loop, a potential data dependency appears when two particles within a single vector length try to write on the same memory location for the grid-based array (for example, mcoup). When compiling for Intel® Advanced Vector Extensions 2 (Intel® AVX2), it’s important to use #pragma omp ordered simd so that the loop can be safely vectorized. Since Intel® Advanced Vector Extensions 512 (Intel® AVX-512) provides conflict detection instructions (vpconflict), this code is no longer necessary for Intel AVX512. Also, use aligned and simdlen clauses in the OpenMP SIMD directives so that the compiler generates more efficient vector instructions, for example:

Note the current Intel C++ Compiler only allows a local variable name in the aligned clause list. Using a class data member name directly causes a compiler error. The solution is to define local variables and assign class data member variables to local variables, for example:

After adding the OpenMP SIMD directives, the vectorization report shows that the compiler has now successfully vectorized the outermost loop with aligned access to the particle data (Figure 6). Unfortunately, the vectorized version is inefficient and doesn’t give a speedup over the scalar version due to the gather/scatter nature of the kernels. For example, the estimated potential speedup is only 0.55 and 0.67 for deposit and move, respectively.
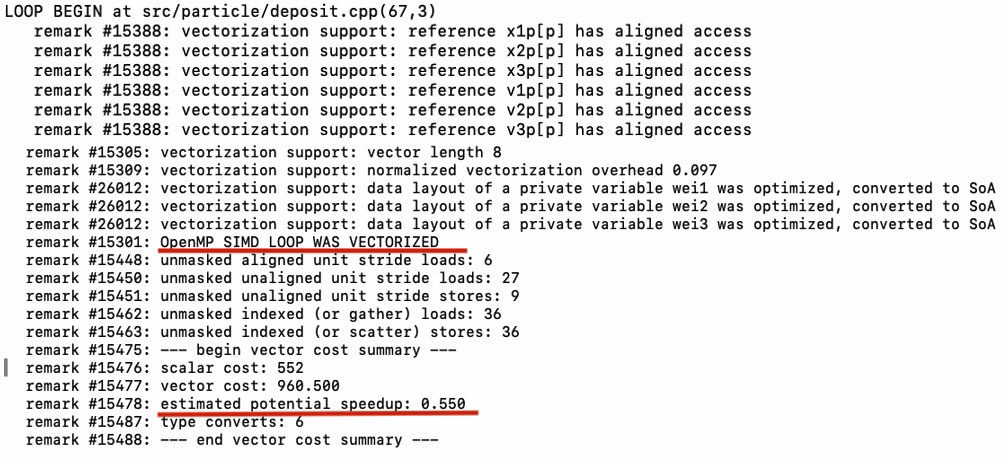
Figure 6. Vectorization report for loops in deposit (after adding OpenMP SIMD directives)
Strip Mining
Strip mining is a common technique to help the compiler automatically vectorize code by exposing data parallelism.2 The idea is to transform a single loop into a nested loop where the outer loop strides through a strip and the inner loop strides all iterations within the strip (Figure 7).
Usually, the strip size is a multiple of the vector length. In some computationally-intensive loops, the strip mining technique alone can lead to a significant performance boost. For deposit and move, replacing the particle loop with two nested loops doesn’t help with performance due to the gather/scatter. After applying strip mining, for example, the estimated potential speedup is still only 0.52 and 0.67 for deposit and move, respectively (Figure 8).

Figure 7. Strip mining for particle loop
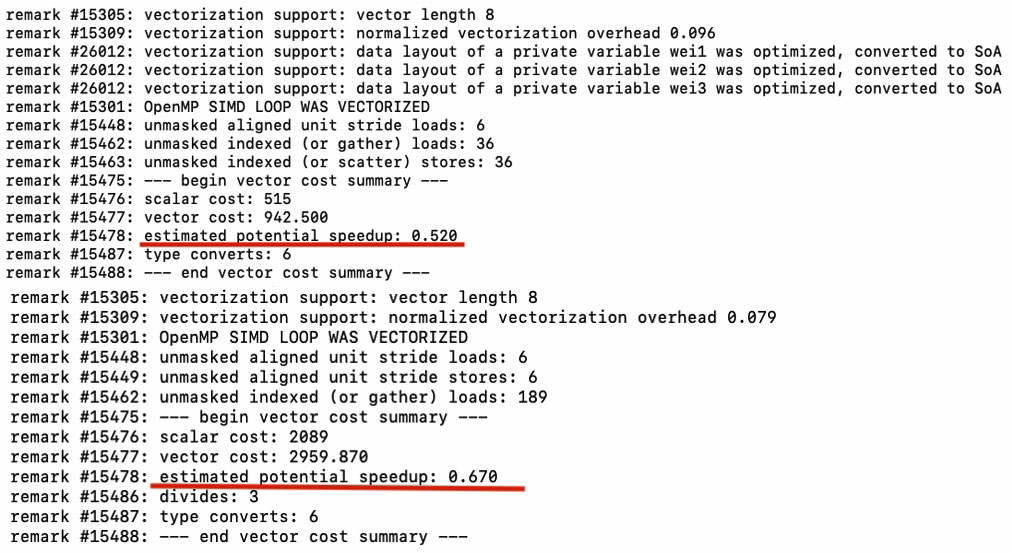
Figure 8. Vectorization report for deposit and move after applying strip mining
But, strip mining can be a powerful technique when you use it as a basis for other techniques, such as loop fission.
Loop Fission for move
The move loop includes two operations:
- The interpolation of grid-based fields onto particles (gather)
- Updating of particle properties according to the interpolated fields
While the former won’t benefit from vector instructions, the latter will. The idea here is to use loop fission to separate the non-vectorizable operation from the vectorizable one to improve performance. At the same time, by applying strip mining with loop fission, we can significantly reduce the storage requirement for passing local variables from the first loop to the second. Figure 9 shows the new move implementation.
The vectorization report shows that although there is no potential speedup for the first loop, the second achieves a 6.59 estimated potential speedup (Figure 10).
Vectorizable Charge Deposition Algorithm for deposit
Compared with move, deposit is more challenging to optimize. For the scatter operation, the performance challenges involve not only random memory accesses and potential data conflicts, but also increased pressure on the memory subsystem. Also, unlike move, which also includes many independent computationally-intensive operations (in other words, updating particles properties), deposit is mostly memory operations. A key optimization here is to reduce (or even avoid) data conflicts and regularize memory accesses. Motivated by the portable SIMD charge deposition algorithm in the Particle-in-Cell Scalable Application Resource (PICSAR) code,3 a vectorizable charge deposition algorithm for deposit was implemented (Figure 11).


Figure 9. New move implementation with strip mining and loop fission
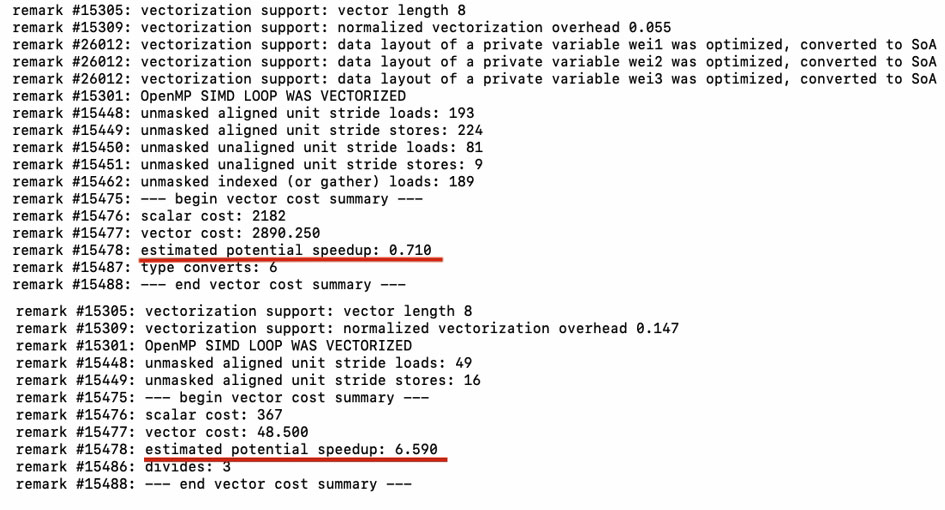
Figure 10. Vectorization report for the revised move code
First, the outermost particle loop is changed to two nested loops using strip mining. In the first nested loop (L69-L133), the particle properties are deposited on a set of local arrays with stride-one memory access, so the compiler generates highly vectorized machine code.
In the second nested loop (L135-L159), the information saved in the local arrays is transferred to an extended global grid array (L163-L205), where each grid point is associated with particle deposition on surrounding grid points (in other words, a 27-point stencil). The price you pay is the extra storage required for the extended global array. The storage can be reduced if you consider the 27-point stencil as three 9-point stencils.
The grid-based values in the extended global array need to be merged at the end. Though it's difficult to vectorize the merging operation, the cost isn’t significant, since the loop is over grid indices at least an order of magnitude smaller than the particle one.

Figure 11. Vectorizable charge deposition algorithm for deposit
Figure 12 shows the vectorization report for the new implementation. The first and second loops now achieve 5.72 and 5.69 estimated potential speedup, respectively.
Performance Evaluation on Intel® Architectures
Performance was evaluated on a 10x10x10 test grid with 100 particles per cell. We ran the simulations for 1,001 timesteps and measured the total wall clock time. We measured performance on single-core Intel® Xeon® and Intel® Xeon Phi™ processors (Figure 13):
- BDW: Intel® Xeon® E5-2680 processor v4, 2.4 GHz, two sockets, 14 cores
- SKX: Intel® Xeon® Gold 6148 processor, 2.40 GHz, two sockets, 20 cores
- KNL: Intel® Xeon Phi™ 7250 processor, 1.4 GHz, one socket, 68 cores
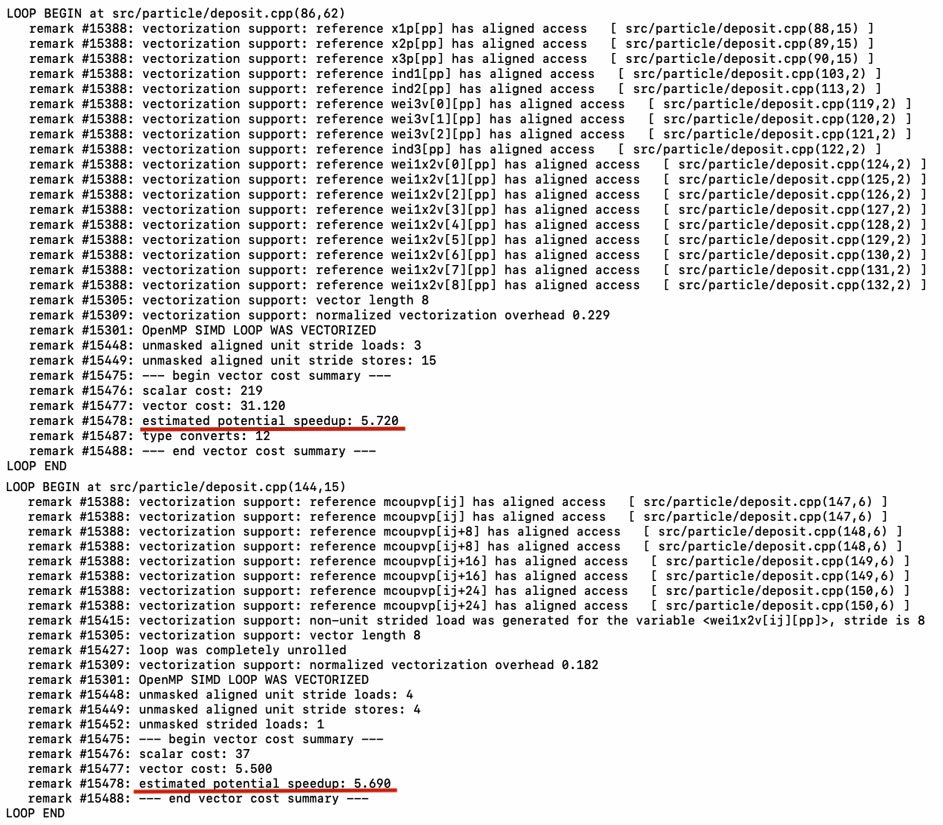
Figure 12. Vectorization report for deposit
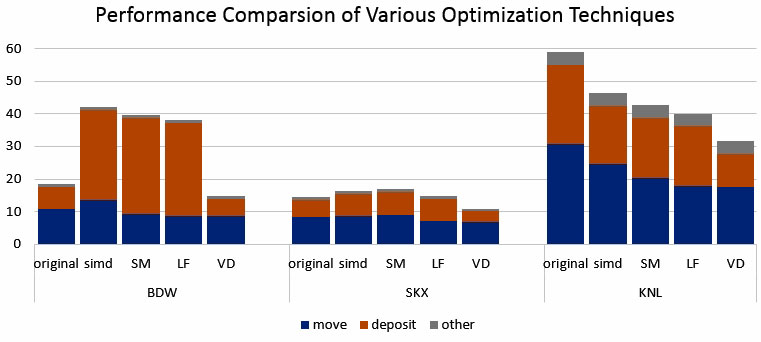
Figure 13. Performance comparison of various optimization techniques on Intel® processors. The optimization techniques include SIMD, strip mining (SM), loop fission for move (LF), and vectorizable charge deposition (VD). For each case, the reported number is the averaged time of multiple runs on a dedicated system.
You can see that the actual performance is consistent with the estimated potential speedup from the compiler report. The Intel Xeon E5-2680 processor has significant performance overhead in using SIMD for deposit. This is due to the #pragma omp ordered simd clause ensuring the right order of writing to the grid array when compiling with Intel AVX2 instructions. Overall, strip mining, combined with other techniques, has led to 1.3x to 1.9x performance boost on Intel processors.
Acknowledgements
This work was supported by the Intel® Parallel Computing Centers. We would like to thank Jason Sewall at Intel for providing strong technical support for this work. We also would like to thank Lev Arzamasskiy and Matthew Kunz in the Princeton University Department of Astrophysical Sciences for sharing their source code.
References
- Athena++
- Optimization Techniques for the Multicore and Manycore Architectures, Part 2 of 3: Strip-Mining for Vectorization
- PICSAR
______
You May Also Like
Extend the Roofline Model
Listen
Intel® Advisor
Design code for efficient vectorization, threading, memory usage, and GPU offloading. Intel Advisor is included as part of the Intel® oneAPI Base Toolkit.
Get It Now
See All Tools