Exploit the Intel® Advanced Vector Extensions 512 (Intel® AVX-512) Single Instruction Multiple Data (SIMD) to Accelerate Prefix Sum Computations
Vamsi Sripathi and Ruchira Sasanka, senior high-performance computing (HPC) application engineers, Intel Corporation
@IntelDevTools
Get the Latest on All Things CODE
Introduction
Modern Intel® processors offer instruction-, data-, and thread-level parallelism. The ability to simultaneously run SIMD operands maximizes the use of processor arithmetic execution units. This article focuses on SIMD optimizations applied to vector scan operations.
Scan (also known as inclusive/exclusive scan, prefix sum, or cumulative sum) is a common operation in many application domains.1 As such, it is defined as a standard library function in C++, the OpenMP* runtime, and the Python* NumPy package.2,3 A scan of a vector is another vector where the result at index i is obtained by summing all the values up to index i (for inclusive scan) and i-1 (for exclusive scan) from the source vector. For instance, the inclusive scan of vector x with n elements is obtained by:
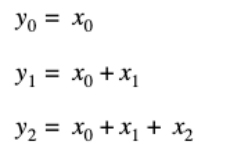
And generally defined as:
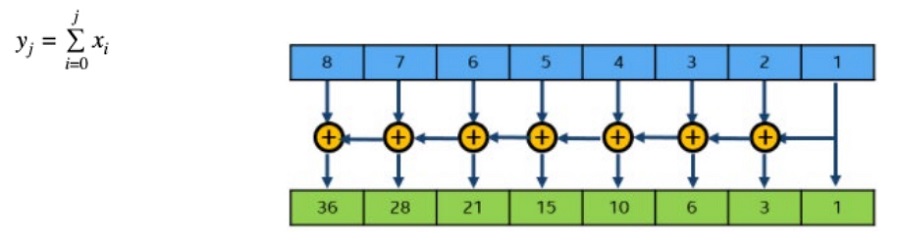
This article begins with a demonstration of inclusive scan, henceforth referred to simply as scan. Beginning with a brief overview of SIMD, also known as vectorization, the article continues with a baseline implementation of the scan operation in C and with OpenMP directives. Next, see how to implement an optimized scan algorithm in SIMD operating on 512-bit vector registers. The article concludes with performance comparisons of the baseline and optimized implementations.
SIMD Overview
SIMD instructions operate on wider vector registers that can hold multiple data operands. The width and the number of vector registers are architecture-dependent, with the latest generation of Intel processors supporting 32, 512-bit-wide vector registers. Intel provides x86 ISA extensions in the form of Intel® Advanced Vector Extensions (Intel® AVX), Intel® Advanced Vector Extensions 2 (Intel® AVX2), and Intel AVX-512 that allow various arithmetic and logical operations to be performed on the 256-bit- and 512-bit-wide registers, respectively. Depending on the width of vector register, they are named XMM, YMM, or ZMM, as shown in the following table:
Table 1. SIMD register naming
| Register Width | Register Name | Num. 64b operands/register | x86 ISA | Num. 64b ops per SIMD Add |
|---|---|---|---|---|
| 128-bit | XMM | 2 | SSE | 2 |
| 256-bit | YMM | 4 | AVX/AVX2 | 4 |
| 512-bit | ZMM | 8 | AVX512 | 8 |
SIMD execution is mainly facilitated through two methods:
- Implicit Vectorization
This relies on the compiler to automatically transform the scalar computational loops into vectorized or SIMD blocks. The compiler does the heavy lifting of identifying which computations to vectorize, how aggressively to unroll loops, and so forth, based on a cost model. It also handles the data alignment requirements of SIMD instructions by producing the necessary loop prologue and epilogue sections in the generated object code. All the programmer has to do is use the appropriate compiler optimization flags for the target CPU architecture. Intel® compilers also provide pragmas4 to give explicit hints to control the generation of SIMD instructions.
- Explicit Vectorization
- Vector intrinsics: These are C APIs provided by the compiler that map to the underlying hardware SIMD instructions.5 They allow the programming to control the type of SIMD instructions (Intel AVX, Intel AVX2, and Intel AVX-512) that are generated in the code and how aggressively they are used. This can be viewed as a hybrid mode wherein the programmer still relies on the compiler for critical aspects of tuning, such as register renaming and instruction scheduling, but at the same time can control the code generation of nontrivial, data-dependent operations, such as scan.
- Assembly language: This completely bypasses compiler optimization in favor of assembly language coding, which requires expert knowledge of underlying microarchitecture. This approach is not recommended.
The tradeoffs of these approaches are summarized in Table 2:
Table 2. Comparison of SIMD programming approaches
| Mode | Portability | Effort |
|---|---|---|
| Implicit Vectorization | High | Low |
| Vector Intrinsics | Medium | Medium |
| Assembly Instructions | Low | High |
Baseline Code
The baseline code for computing the scan of a vector is shown below, followed by the Intel compiler optimization report (generated using the -qopt-report=5 compiler option). The scan operation has inherent loop-carried dependencies, so the compiler is unable to fully vectorize the computation.

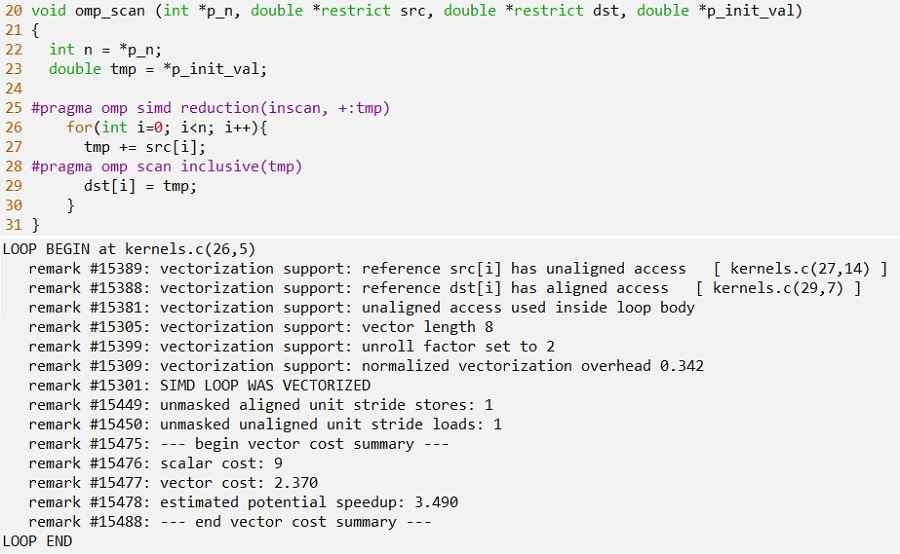
The same operation with the addition of OpenMP directives is shown below, along with the compiler optimization report. OpenMP is a portable, directive-based parallel programming model that includes SIMD support. The SIMD construct (combined with the reduction clause and scan directive) can be used to perform a scan operation on the vector. For more information, refer to the OpenMP specification, which provides good documentation.6,7 Because we are interested in understanding the impact of SIMD on workload performance, we are not parallelizing the loop, but instead limiting the OpenMP directives to vectorization only. The compiler optimization report shows that vectorization was performed using a vector length of eight (that is, Intel AVX-512) and that the loop was unrolled by a factor of 16 elements.
The next section compares the baseline and auto-vectorized variants to the explicit Intel AVX-512 SIMD implementation.
Explicit Vectorization
This section demonstrates the SIMD techniques to optimize the vector scan operations on Intel processors that support Intel AVX-512 execution units. The demonstration uses the double-precision floating point (FP64) datatype for input and output vectors. The Intel AVX-512 SIMD instructions used in this implementation are shown in Table 3.
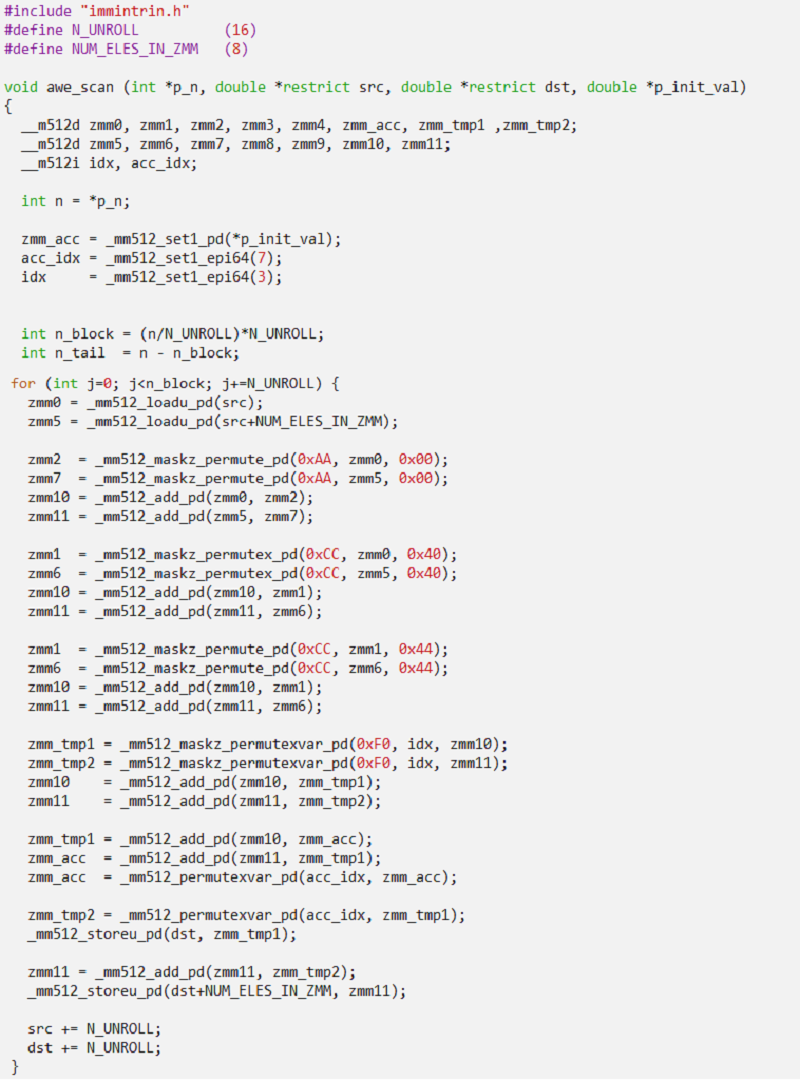
The main idea behind this implementation is to simultaneously perform a series of add operations in the lower and upper 256-bit lanes of the 512-bit register after applying the necessary shuffle sequence. For every eight input elements, we perform a total of five adds and five permutes. All the add operations form a dependency chain because we are accumulating the results in a single register. However, some of the permutes are independent of the add, so they can be executed simultaneously. Figure 1 shows a visual representation of the implementation, followed by the code showing the main loop block where we are processing 16 elements per iteration.
Table 3. Intel AVX-512 SIMD instructions
| Name | Intel AVX-512 Vector Intrinsics API |
Description |
|---|---|---|
| SIMD Load | __m512d _mm512_loadu_pd |
Load a set of eight FP64 elements from memory to Intel AVX-512 vector register. |
| SIMD Add | __m512d _mm512_add_pd |
Add FP64 elements in src1 and src2 and return the results. |
| SIMD
|
__m512d _mm512_maskz_permute_pd |
Shuffle FP64 elements in src within 128-bit lanes using the 8-bit control in imm8, and store the results using zeromask k. (Elements are zeroed out when corresponding mask bit is not set.) |
| SIMD |
__m512d mm512_maskz_permutex_pd |
Shuffle FP64 elements in src within 256-bit lanes using the 8-bit control in imm8, and store the results using zeromask k.(Elements are zeroed out when corresponding mask bit is not set.) |
| SIMD Store |
void _mm512_storeu_pd |
Store a set of eight FP64 elements to memory from Intel AVX-512 vector register. |
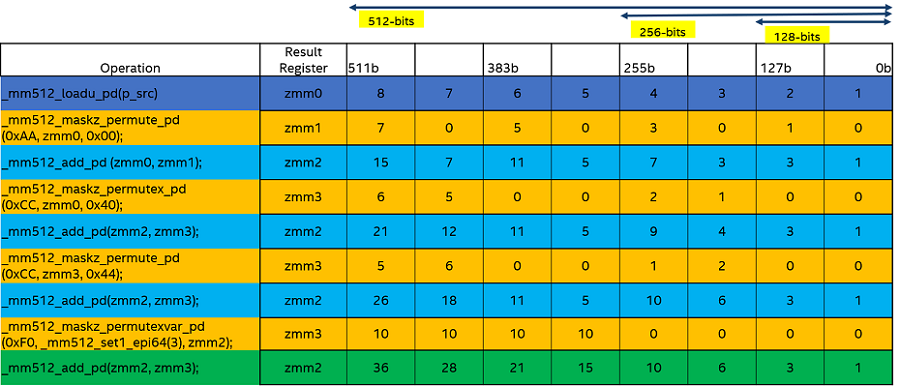
Figure 1. Explicit Intel AVX-512 SIMD scan operation sequence
Performance Evaluation
We evaluate the performance between the three versions of scan implementations on a single core of an Intel® Xeon® Platinum 8260L processor. The GNU Compiler Collection (GCC)* v9.3.0, Clang compiler v10.0.1, and Intel® C++ Compiler, v19.1.3.304, were compared for the baseline, OpenMP SIMD, and explicit Intel AVX-512 SIMD implementations. Table 4 shows the assembly code generated by the Intel C++ Compiler for the main block of each implementation
Table 4. Assembly code for the three scan implementations
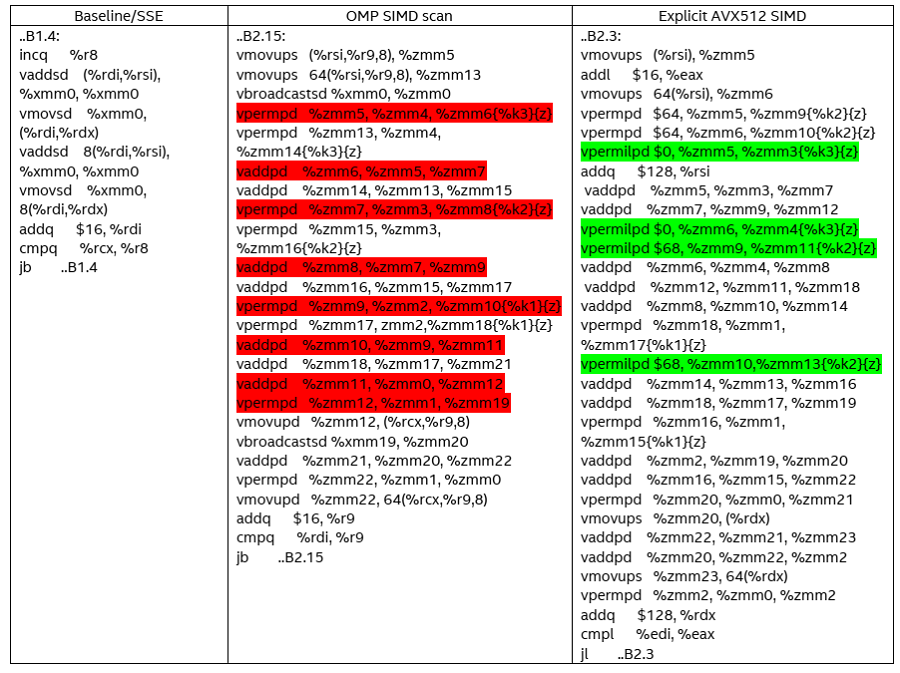
For the baseline code, the loop is unrolled by only two elements, and both scalar add operations form a dependency chain. This is inefficient because the generated code is not exploiting the wider Intel AVX-512 execution units.
The OpenMP SIMD implementation is more interesting because the generated code uses Intel AVX-512 add and permute operations and is unrolled by 16 elements. There are total of eight adds, eight permute, and two broadcast instructions to process 16 input elements. For a set of eight elements, the add and permutes form a dependency chain (highlighted in red). In addition, all the permutes generated in this version of the code shuffle elements within 256b lanes. Permutes that shuffle elements within a 128b lanes have lower latency (one cycle) than permutes that shuffle within 256b lanes (three cycles).
Our explicit Intel AVX-512 SIMD implementation is also unrolled by 16 elements, and uses 11 add and 10 permute instructions to process those 16 elements. Even though we use greater number of add and permute instructions compared to the OpenMP SIMD scan, it has two advantages. First, four out of ten permutes are within a 128b lane (one-cycle latency), and hence are more efficient. These four permute instructions are highlighted in green. Second, some of the permutes are independent of the add instructions. This helps by providing more instruction-level parallelism and more effective utilization of Intel AVX-512 execution units. We do an extra add to compute the accumulation result as soon as possible. This puts more concurrent instructions in flight and mitigates stalls in the execution pipeline for future iterations.
Figure 2 shows the performance for vector sizes ranging from 64 to 1,024 elements in steps of 32 and with all vectors residing in L1 cache. We can make the following observations from the performance data:
- The explicit Intel AVX-512 SIMD implementation outperforms both the baseline and OpenMP SIMD implementations.
- GCC and Clang are unable to vectorize the scan computations. Their performance remains unchanged, even with the OpenMP SIMD directives.
- Intel C++ Compiler does a great job of auto-vectorization when OpenMP SIMD directives are used.
- The average speed-up of the explicit SIMD scan implementation over the baseline and OpenMP SIMD scans is 4.6x (GCC and Clang) and 1.6x (Intel C++ Compiler), respectively.
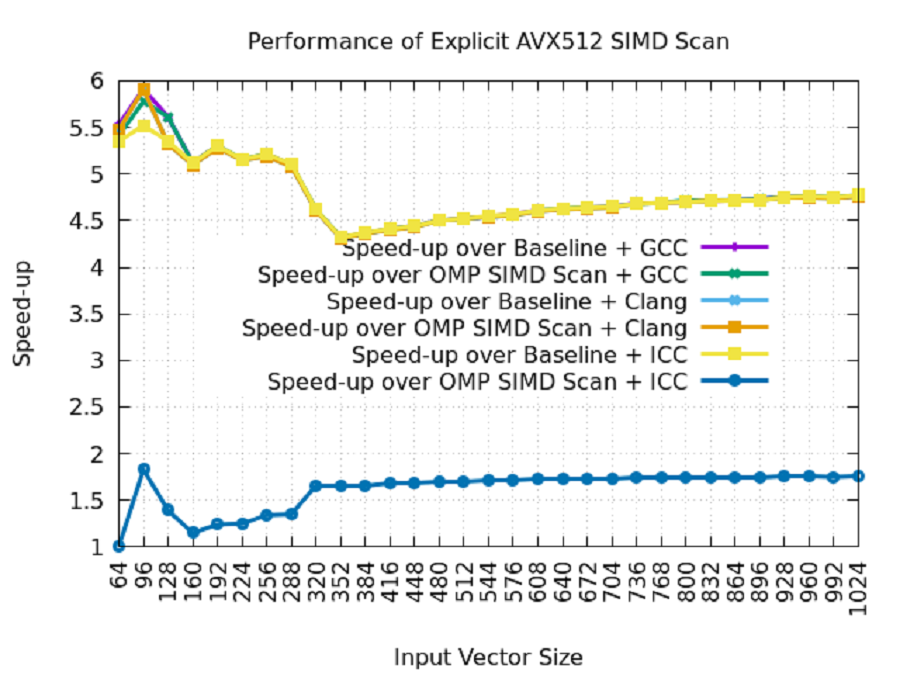
Figure 2. Performance comparison of an explicit Intel AVX-512 scan
Final Thoughts
We have briefly introduced explicit SIMD programming and applied it to vector scan computations. While optimizing compilers can often provide good performance, there may be cases, as demonstrated in this article, where there is room for improvement. Therefore, it is useful for developers to understand explicit SIMD programming to achieve maximum performance.
References
- Guy E Blelloch (2018) Prefix Sums and Their Applications
- Inclusive Scan Algorithm
- NumPy Cumulative Sum
- Intel C++ Compiler Classic Developer Guide and Reference
- Intel C++ Compiler Classic Developer Guide: About Intrinsics
- OpenMP API Specification: SIMD Directives
- OpenMP API Specification: Scan Directive
______
You May Also Like
| Intel® oneAPI DPC++/C++ Compiler |