How to Use the OpenMP Single Instruction Multiple Data (SIMD) Directive to Tell the Compiler What Code to Vectorize
Clay P. Breshears, PhD, principal engineer, Omics Data Automation, Inc.
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
OpenMP* was created over 20 years ago to provide a standard for compiler-directed threading that's easier to use and understand than an explicit threading library like pthreads. Many of the details about creating and destroying, managing, and assigning computations to threads was abstracted away into compiler directives. Modern CPUs have vector registers that allow the same instruction to be run on multiple pieces of data. Such instruction-level parallelism greatly improves performance and power efficiency. But with thread-level parallelism, the compiler sometimes needs help with getting it right. The SIMD directive and clauses were added to OpenMP to give programmers a way to tell the compiler what computations can be vectorized.
Simple Vectorization Example
The code in Figure 1 is used to compute the value of π. This is done by calculating the area under the curve of the function 4.0 / (1.0 + x2) for x between 0 and 1. The general process used in the code is known as numerical integration or Riemann sums.

Figure 1. Riemann sums serial code
If you think back to your linear algebra course, you should recall the midpoint rule of estimating the area under the curve between fixed values on the x-axis. The interval is divided into some number of equal-sized partitions. At the midpoint of each partition, the value of the function is computed. The width of each partition is multiplied by the functional value of the midpoint (or height) to yield the area of a rectangle mostly under the curve. The sum of the areas of all the rectangles across the interval yields a value that's close to the actual numerical answer.
Depending on the chosen width, some parts of the rectangle are outside the curve, and some area under the curve that's not within a rectangle. However, the estimate is more precise as the width decreases or as the number of rectangles increase.
Notice that the loop in Figure 1 generates a set of values, one at a time, through the loop iterator, i. The x variable holds the midpoint value, which is used to compute the functional value (the height of the rectangle at the midpoint). This is to the running total sum. Once the loop is complete, the width of all the rectangles, which is fixed at width, is multiplied by the sum of heights to compute the area. (The actual area multiplication could be done within the loop before adding the value to sum, but as an optimization, it was pulled out of the loop and performed once rather than hundreds of thousands or millions of times.)
Each iteration of the loop computing a rectangle’s area is independent. Thus, the loop could be threaded with OpenMP and the partial answers generated within each thread summed together to arrive at an answer. But that's a topic for another article. The aim of this article is to show how this loop can be vectorized.
The loop body is performing the same computations over and over again on a range of values generated by each loop iteration. These are an addition and multiplication to compute x and a multiplication, addition, and division added to sum. If sets of those values could be loaded into a vector register, those computations could be run in fewer instruction cycles. For the sake of oversimplification, a back-of-the-envelope calculation shows each loop iteration performing six arithmetic operations 10 million times. By packing four or eight values into one register and performing the arithmetic operation on all of those values in a single instruction, the number of running instructions goes from 60 million scalar instructions to 15 million or 7.5 million vector instructions.
Simple Use of OpenMP SIMD Directives
Since vector registers need to be populated with multiple values, the basic OpenMP SIMD directive omp simd is used to vectorize loops that are generating multiple values and performing the same computations on each. Figure 2 shows the loop from Figure 1 with the added OpenMP directive. This informs the compiler that the computations within the loop can be converted from scalar to vectorize operations.

Figure 2. Example of OpenMP omp simd directive to vectorize a loop
Each num_rects iteration can be bundled (each with the corresponding values of the loop iterator, i) into a logical iteration where the loop body operations are carried out on each of the bundled iterations through supported SIMD hardware. The OpenMP standard calls these bundles of iterations a SIMD chunk. The number of serial iterations that are placed into a SIMD chunk depend on:
- The hardware and instruction set support for vector operations at execution
- The size of the values being operated on
- Other implementation-specific factors
Table 1 shows some timing results for the two versions of the Riemann sums code. There's an obvious performance advantage to vectorizing this code.
Table 1. Timing results of serial and vectorized Riemann sums code
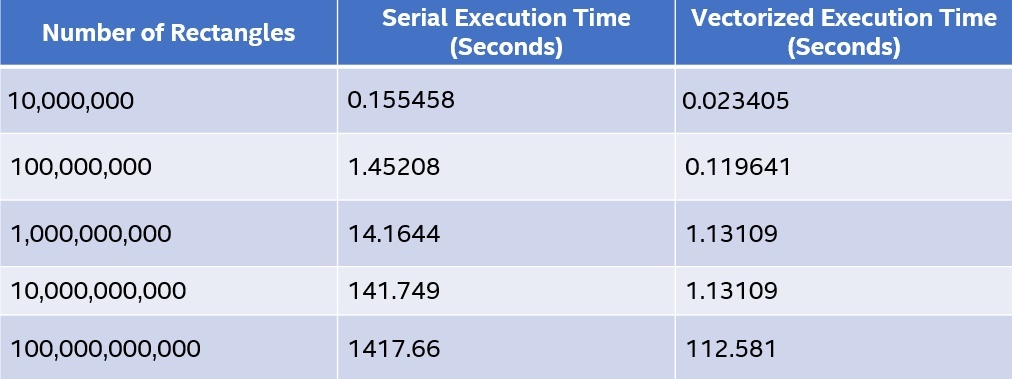
We can add several clauses to the SIMD directive. If you're familiar with OpenMP (and as seen in the previous example), you can use the private and reduction clauses as needed. Other, more specific, clauses are used with the SIMD directive. The clauses give better hints to the compiler about memory layout and access patterns that would produce better code or overcome some of the compiler’s conservative tendencies (for example, the safelen clause discussed next). This article doesn’t go into all of the available clauses. Consult the OpenMP specification for complete details.
Advantages of the Intel® Compiler
Before going into more details about OpenMP SIMD support, a confession about the results presented in Table 1 is in order. The Intel® compiler has been improved over the years and benefits from intimate knowledge of the vector hardware changes and currently supported vector instructions in Intel® processors. As a result, the loop in Figure 2 doesn’t need hints from the OpenMP SIMD directive to recognize the vector possibilities and to vectorize the code. The confession is that the serial code was compiled with optimization disabled (via the -O0 flag) to prevent the compiler from automatically vectorizing or parallelizing the loop.
The compiler optimization report provides insights into what the compiler finds on its own for vector and parallel optimizations. Plus, for those loops we assume can be vectorized, we can also use the generated optimization reports to determine why the compiler decided not to vectorize. Then, we can reexamine the code and consider transformations to allow vectorization. This could be refactoring the code to better order the operations or adding OpenMP SIMD directives and clauses to assure the compiler that vectorization is safe.
As a quick example, Figure 3 shows the compilation command on the original serial code (Figure 1) to determine what the compiler sees regarding vectorization.

Figure 3. Compile with vectorization optimization report flags
This generates a pi.optrpt output file containing the information shown in Figure 4.

Figure 4. Output vectorization report
In the actual code that was compiled, line 16 is the for-loop and line 17 is the assignment of x. (The emulation comment remained after casting the iteration variable, i, to double.) Thus, the Intel compiler can identify code that can be safely vectorized without any programmer intervention.
If you suspect that a loop should be vectorizable, try adding OpenMP SIMD directives, recompiling with the -fopenmp flag, and looking at the console output from the compiler. Even with SIMD directives, if the compiler is unable to safely vectorize the loop, it gives a warning message shown in Figure 5.

Figure 5. Compiler output for nonvectorizable code
At this point, use the -qopt-report option to request an optimization report from the compiler to determine why it was unable to vectorize the code. With this information, you can reevaluate the code with an eye toward:
- Refactoring it to remove the impediment
- Adding some clauses to the directive that assure the compiler that vectorization is saf
- Examining the loop for other possible optimizations
The safelen Clause
Now let's consider the function shown in Figure 6.

Figure 6. Another loop for possible vectorization
This code takes two floating-point arrays (A, B), a scaling factor (scale), and start and end (s, e) positions of the first array to be updated by adding a scaled value from a corresponding element of the second array. This is a floating-point, multiply-add operation that's typically vectorizable if there's no overlap between the A and B arrays.
If B is part of A, but a part that has higher index values (in other words, further down in the A array than the current element being computed), the code has an antidependency, or a write-after-read dependency. For example, if B is A offset by two elements, consider this (size 4) SIMD chunk of the inner loop:

Figure 7
There's no problem with vectorization because the current values of A[k+2] to A[k+5] are copied into a vector register, multiplied by scale, then added to the current values of A[k] to A[k+3] (also loaded into a vector register).
The third case, where B is A offset by a negative value, the code has a true dependency, or read-after-write dependency, that can cause problems if vectorized. Consider the case of a -2 offset. The SIMD chunk in Figure 7 unwinds to:

Figure 8: Separate file holding the computation from the original example
There's a problem with reading the original values of A[k] and A[k+1] before the updated (correct) values have been written into them. If the minimum value of the offset is known, this is where the safe minimum length of SIMD chunks is given to the compiler through the safelen clause. If the gap between elements is never less than, for example, 12 between A and B (whenever those two arrays are actually part of the same array), the original function in Figure 6 can be vectorized with OpenMP, as shown in Figure 9. The compiler can now construct vector code that is safe for vector lengths of 12 elements or less.

Figure 9. Use the safelen clause to communicate to the compiler the safe length of vectors
Note Using the Intel compiler on the original scale() function (Figure 6) generates a vectorized version of the code. This is because a loop is contained in the code and it appears to be safe. However, since there's a chance of a true dependency, the compiler also generates the serial version of the loop. At runtime, the addresses of the A and B parameters are compared, and the correct choice of compiled code runs.
Return of the Simple Example
As mentioned at the end of the previous section, the Intel compiler generates vectorized code when it’s safe to do so. Otherwise, it generates a serial code. But, what about a loop that contains a call to a user-defined function? If that function isn’t inlined, the compiler cannot determine if the loop can be vectorized safely.
Figures 10 and 11 show a restructured version of the Riemann sums code that's been split into two files. Figure 10, pi_func.cc, is the computation of the functional value at the ith midpoint within the bounds of the curve for which we're computing the area. Figure 11, pi_driver.cc, is the main body of the Riemann sums driver code.

Figure 10. Separate file holding the computation from the original example

Figure 11. Driver code to call a user-defined function from within the loop
One advantage of constructing the code this way is the ability to substitute almost any computational function that makes the driver code a more general Riemann sums algorithm. The print statement needs to be changed and the function name updated to something more generic. Then your desired computational function for processing is simply linked to the driver.
Without a loop in the pi_func.cc file (Figure 10), the compiler is unable to vectorize that computation. With the user-defined pi_func() call in the loop (Figure 11), the compiler cannot determine whether the code can be vectorized. In fact, compiling the pi_func.cc file with the report-generating options for vectorization gives an empty report.
The declare simd directive can be used to tell the compiler to vectorize code that the programmer knows is safe. The first step is to add the pragma shown in Figure 12 to the function pi_func().

Figure 12. Add declare simd to denote that the function is vectorizable
This is also done at the extern declaration in the driver code file (Figure 13). To complete the process, the loop containing the call to pi_func() needs to be denoted as vectorizable in much the way it was in the original example.

Figure 13. Relevant code lines from Figure 11 with added OpenMP SIMD directives
The compilation process of the pi_func() code creates a vectorized version of the function, say vec_pi_func(). Within the driver function, the loop body is altered to call a vectorized version of the function vec_pi_func(). Essentially, if the vector length supported by the hardware and the data style was four, the four calls of pi_func() with parameter values i, i+1, i+2, and i+3 are substituted for a single call to the vectorized version, vec_pi_func(), with the four values copied into a vector register for running the vector.
Table 2 shows some timing results from running the two versions of the separated Riemann sums code with the function value calculation set off in a separate file. The vectorized version uses the declare simd clause for vectorization. The vectorized version in this example is demonstrably faster than the serial code, though not as much as the original version shown at the outset.
Table 2. Runtimes for serial and vectorized compilations of Riemann Sums code with the userdefined function
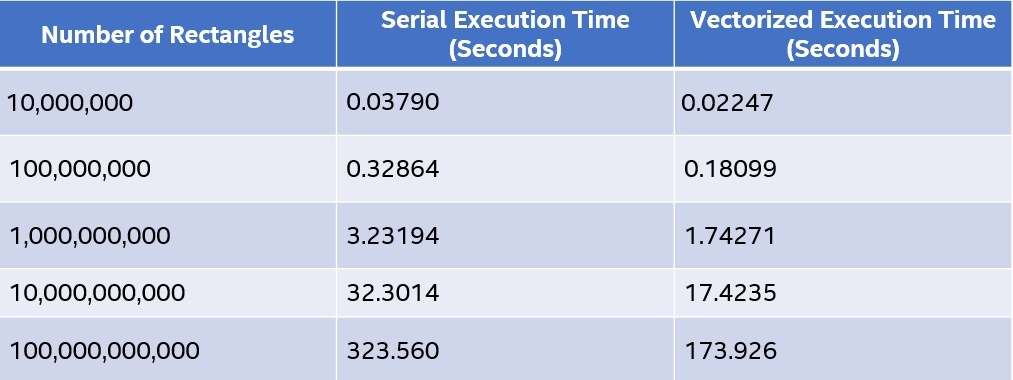
Reduce the Runtime
For computations that can be run simultaneously, a vectorized solution on hardware that supports the running reduces the runtime by actually making multiple computations within the same machine cycles. This even applies to parallelized code. Try this exercise: Take the original Riemann sums code in Figure 1 and make the for-loop both threaded and vectorized.
In straightforward cases, the Intel compiler automatically vectorizes loops of computations at the appropriate compiler optimization levels. The optimization reports from the Intel compiler give you information about what was vectorized and what wasn’t (and why it wasn’t vectorized). In the latter case, if you believe the compiler was too conservative, you can restructure the code or add OpenMP SIMD directives and clauses to give the compiler hints about what is safe to vectorize. For the full range of SIMD pragmas and clauses, consult the OpenMP documentation for the version supported by your compiler.
References
- All compilation and running was done on the Intel® DevCloud.
- The Intel compiler version used was 19.1 20200306.
- Running happened in an interactive session on Intel® Xeon® Platinum processors with 384 GB memory. The session launched with the following command: qsub -I -l nodes=1:plat8153:ppn=2 -d.
______
You May Also Like
Run HPC Applications on CPUs and GPUs with Xe Architecture
Watch
Intel® oneAPI DPC++/C++ Compiler
Compile ISO C++, Khronos SYCL*, and DPC++ source code across CPUs, GPUs, and FPGAs.
Part of the Intel® oneAPI Base Toolkit.