How to Use OpenMP Directives for Accelerator Offload
Jose Noudohouenou, software engineer, and Nitya Hariharan, application engineer, Intel Corporation
OpenMP* has supported accelerator offload since version 4.0. The Intel® oneAPI Base Toolkit provides support for OpenMP offload with Intel® C, C++, and Fortran compilers. This article shows how to get started with the OpenMP offload directives. It discusses some of the pragmas provided in the standard, show how to compile such programs, and provide an example application that shows you the code modifications necessary for OpenMP accelerator offload. Learn how to use the Intel® VTune™ Profiler and Intel® Advisor tools to identify performance hot spots and optimize the code.
OpenMP Offload Directives
The OpenMP declare target directive is used to map and make accessible a function, subroutine, or variables on an accelerator device. The target map directive maps data to the device environment and runs the offload code on the device. Additional map types in the map clause specify the mapping of data between the host and device:
- to:x specifies the data will be read-only on the device
- from:x specifies data is write-only on the device
- tofrom:x specifies data is in a read-write mode on both the host and the device
The code snippet in Figure 1 is a simple example of Single-Precision A·X Plus Y (SAXPY) with four offload variants:
- DEFAULT
- TEAMS
- THREADS
- TEAM_THREADS
Each snippet uses different OpenMP directives. The DEFAULT variant uses the basic OpenMP offload directive. The TEAMS variant uses the num_teams clause to create thread teams. There's no specification of the number of teams and threads. These are chosen at runtime. The THREADS variant is similar to the TEAMS variant, with the number of threads per team specified by the thread_limit clause. The TEAM_THREADS variant specifies both the number of teams and the number of threads per team.

Figure 1. Code snippet showing SAXPY code with four OpenMP offload variants
The SAXPY offload variants can be called as a regular routine in a main program and the default variant can be compiled as follows.

The -fiopenmp option enables the transformation of OpenMP in LLVM. The -fopenmp-targets=spir64 option notifies the compiler to generate an x86 + SPIR64 fat binary for the GPU device. To learn more about the compilation process, see Get Started and Documentation.
To compile the other variants, use the corresponding -D flag (for example, use -DTEAMS to compile the TEAMS variant). Run the program as follows:

Case Study: Quantum Chromodynamics
This section discusses incorporating OpenMP offload pragmas into the MILC application. We use an Intel® architecture-based machine, which has an Intel® Core™ i7-6770HQ processor running at 2.60 GHz and an integrated Intel® Iris® Pro Graphics 580 GPU v09. The Gen9 has 72 execution units (EUs) including three slices, three subslices per slice, and eight EUs per subslice. It also has an L3 cache size of 3 * 512 KB = 1.5 MB and LLC = 8 MB (shared with the CPU cores). All MILC runs use the wx12t12.in input file.
Let's focus on enabling OpenMP offload starting with profiling the code using Intel Advisor to identify the performance hot spots. Table 1 presents the top four hot spots on the host CPU. These code regions are good candidates for offloading to the Gen9. For each of these hot spots, we add the TEAM_THREADS variant of OpenMP pragmas. The corresponding code snippets are shown in Figures 2 to 5.
Table 1. Top MILC hotspots identified by the Offload Advisor tool of Intel Advisor

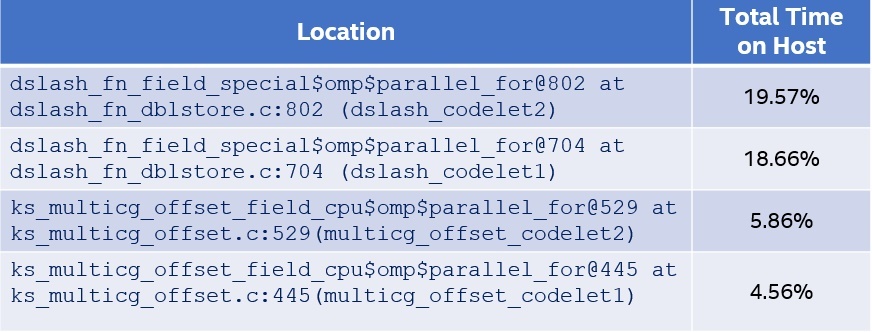

Figure 2. MILC dslash kernel codelet1
Table 2 shows an Intel VTune Profiler GPU offload analysis for each MILC codelet implemented on the Gen9. Along with the hot spots, the analysis provides information regarding the Single Instruction Multiple Data (SIMD) width (Swidth), either 8 or 16, used within a code region, which can then be used to tune the code to get an optimal thread_limit value. The num_teams value is straightforward and can be set to the number of EUs. The thread_limit value requires some information about the loop stride. If the loop stride is 1, the optimal thread_limit is the number of hardware threads per EU (Nthreads) * Swidth. If the stride is greater than 1, thread_limit is the first multiple of Swidth that is greater or equal to stride. The local work size (LWS) and global work size (GWS) are determined using these equations:

The Gen9 has seven hardware threads per EU and 72 EUs. All codelets use an LWS of 112, except multicg_offset_codelet1, which uses 56. The GWS of dslash_codelet1, dslash_codelet2, and multicg_offset_codelet2 is 112 * 72. The GWS for multicg_offset_codelet1 is 56 * 31. In multicg_offset_codelet1, there's a reduction operation that requires syncing between concurrent threads while each thread performs low-compute activities. So, to reduce synchronization costs, it’s better to use fewer EUs to run this codelet. Also, in terms of efficiency, the percentage of the total thread count (initially allocated) that is used to run multicg_offset_codelet1 kernel or loop instances is high and equal to 97.23 percent when setting num_teams to 31. The Call Counts column represents the number of times these codelets are called, while the GPU memory bandwidth shows the data read and write rates per codelet. All these characteristics have an impact on the performance of every hot spot.

Figure 3. MILC dslash kernel codelet1

Figure 4. MILC multicg offset codelet2
Table 2. Intel VTune Profiler GPU Offload Analysis of the MILC team offload
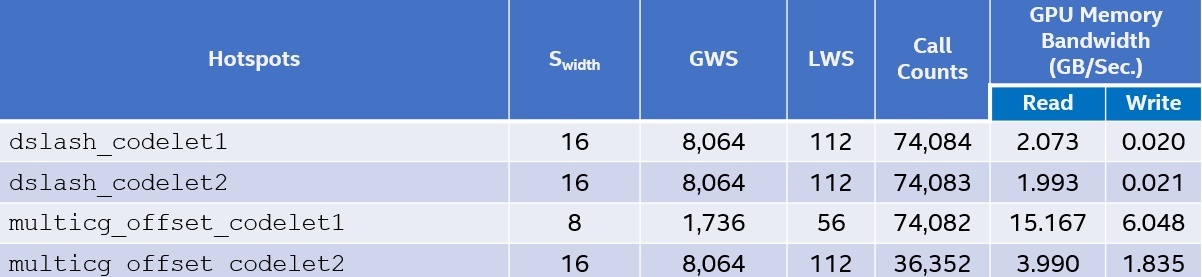

Figure 5. MILC multicg offset codelet2
Conclusion
OpenMP offload support, now provided as part of the Intel oneAPI Base Toolkit, lets you migrate compute-intensive parts of your application to accelerators. Follow the methodology outlined in this article to identify code regions that are suitable for offloading, along with the appropriate OpenMP offload pragmas, and then use profiling and tuning to achieve optimal performance.
______
You May Also Like