Developer Guide
FPGA Optimization Guide for Intel® oneAPI Toolkits
A newer version of this document is available. Customers should click here to go to the newest version.
Simple Host-Device Streaming
You can take advantage of SYCL Unified Shared Memory host allocation and zero-copy host memory to implement a streaming host-device design with low latency and high throughput.
Before you begin learning how to stream data, review Pipes and Zero-Copy Memory Access concepts.
SYCL USM host allocations are only supported by some BSPs, such as the Intel® FPGA Programmable Acceleration Card (PAC) D5005 (previously known as Intel® FPGA Programmable Acceleration Card (PAC) with Intel® Stratix® 10 SX FPGA). Check with your BSP vendor to see if they support SYCL USM host allocations.
To understand the concept, consider the following design example:
- An offload design that maximizes throughput with no optimization for latency. See DoWorkOffload in simple_host_streaming.cpp.
- A single-kernel design that uses the methods described below to achieve a much lower latency while maintaining throughput. See DoWorkSingleKernel in simple_host_streaming.cpp and single_kernel.hpp.
- A multi-kernel design that uses the methods described below to achieve a much lower latency while maintaining throughput. See DoWorkMultiKernel in simple_host_streaming.cpp and multi_kernel.hpp.
Offload Processing
Typical SYCL designs perform offload processing. All of the input data is prepared by the CPU, and then transferred to an FPGA device. Kernels are started on the device to process the data. When the kernels finish, the CPU copies the output data from the FPGA back to its memory. Memory synchronization is achieved on the host after the device kernel signals its completion.
Offload processing achieves excellent throughput when the memory transfers and kernel computation are performed on large data sets, as the CPU's kernel management overhead is minimized. You can conceal data transfer overhead using double buffering or N-way buffering to maximize kernel throughput. However, a significant shortcoming of this design pattern is latency. The coarse-grain synchronization of waiting for the entire set of data to be processed results in a latency that is equal to the processing time of the entire data.
Host-device Streaming Processing
The method for achieving lower latency between the host and device is to break data set into smaller chunks and, instead of enqueueing a single long-running kernel, launch a set of shorter-running kernels. Together, these shorter-running kernels process the data in smaller batches. As memory synchronization occurs upon kernel completion, this strategy makes the output data available to the CPU in a more granular way. This is illustrated in the following figure, where the orange lines illustrate the time when the first set of data is available in the host:
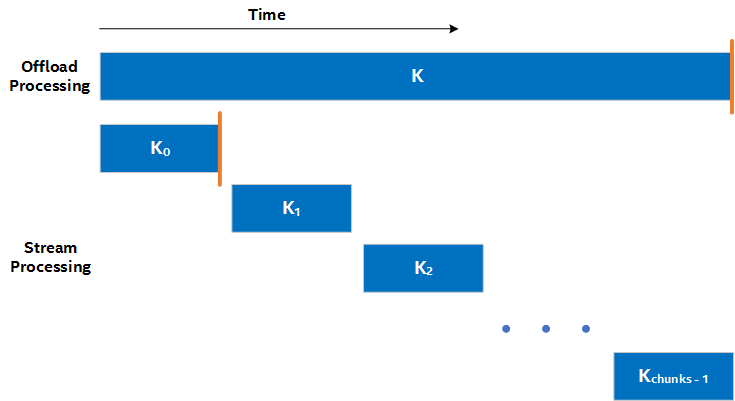
In the streaming version, the first piece of data is available in the host earlier than in the offload version. To understand how much earlier, consider that you have total_size elements of data to process and you break the computation into chunks chunks of size chunk_size=total_size/chunks (as is the case in Figure 1). Then, in an ideal situation, the streaming design achieves a latency that is chunks times better than the offload version.
Setting the chunk_size
You might wonder if you can set the chunk_size to 1 (i.e., chunks=total_size) to minimize the latency. In the figure above, you may notice small gaps between the kernels in the streaming design (for example, between K0 and K1). This is caused by the overhead of launching kernels and detecting kernel completion on the host. These gaps increase the total processing time and therefore, decrease the throughput of the design (that is, when compared to the offload design, it takes more time to process the same amount of data). If these gaps are negligible, then the throughput is negligibly affected.
In the streaming design, the choice of the chunk_size is thus a tradeoff between latency (a smaller chunk size results in a smaller latency) and throughput (a smaller chunk size increases the relevance of the inter-kernel latency).
Lower Bounds on Latency
Lowering the chunk_size can reduce latency, sometimes at the expense of throughput. However, even if you are not concerned with throughput, there still exists a lower-bound on the latency of a kernel. Review the following figure:
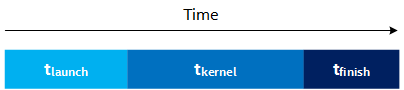
In the Figure 2:
- tlaunch is the time for a kernel launch signal to go from the host to the device.
- tkernel is the time for the kernel to execute on the device.
- tfinish is the time for the finished signal to go from the device to the host.
Even if you set chunk_size to 0 (i.e., launch a kernel that does nothing) and therefore tkernel ~= 0, the latency is still tlaunch + tfinish. In other words, the lower bound on kernel latency is the time needed for the start signal to go from the host to the device and for the finished signal to go from the device to the host.
In the Setting the chunk_size section above, you learned how gaps between kernel invocations can degrade throughput. In the Figure 2, there appears to be a minimum tlaunch + tfinish gap between kernel invocations. This is illustrated as the Naive Relaunch timeline in the following figure:
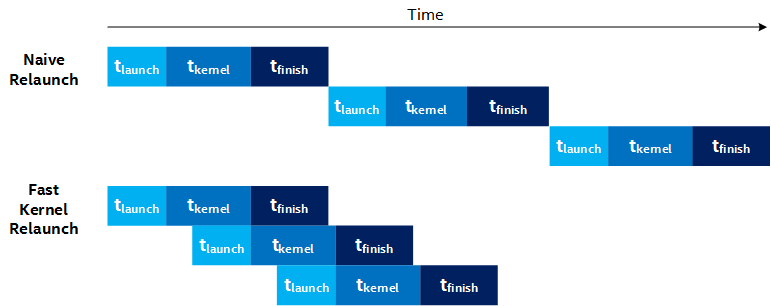
Fortunately, this overhead is circumvented by an automatic runtime kernel launch scheme that buffers kernel arguments on the device before the previous kernel finishes. This enables kernels to queue on the device and to begin execution without waiting for the previous kernel's finished to propagate back to the host. You can refer to this as Fast Kernel Relaunch, and it is also illustrated in the Figure 3. Fast kernel relaunch reduces the gap between kernel invocations and allows you to achieve lower latency while maintaining throughput.
Multiple Kernel Pipeline
More complicated FPGA designs often instantiate multiple kernels connected by SYCL pipes (for examples, see FPGA Reference Designs). Suppose you have a kernel system of N kernels connected by pipes, as shown in the following figure:
With the goal of achieving lower latency, you use the Host-device Streaming Processing technique to launch multiple invocations of your N kernels to process chunks of data. This gives you a timeline as shown in the following figure:
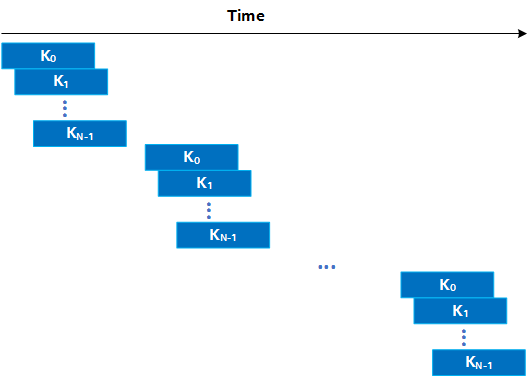
Notice the gaps between the start times of the N kernels for a single chunk. This is the tlaunch time discussed in the Host-device Streaming Processing. However, the multi-kernel design introduces a potential new lower bound on the latency for a single chunk because processing a single chunk of data requires launching N kernels, which takes N x tlaunch. If N (the number of kernels in your system) is sufficiently large, this limits your achievable latency.
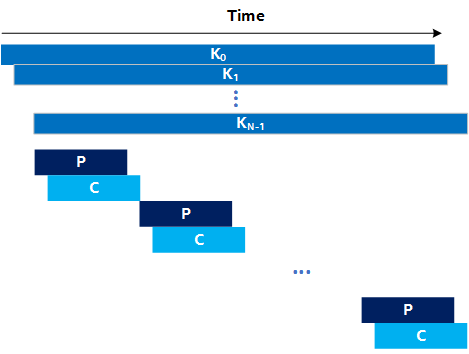
For designs with N > 2, Intel recommends a different approach. The idea is to enqueue your system of N kernels once, and to introduce Producer (P) and Consumer (C) kernels to handle the production and consumption of data from and to the host, respectively. This method is illustrated in the following figure:

The Producer streams data from the host and presents it to the kernel system through a SYCL pipe. The output of the kernel system is consumed by the Consumer and written back into host memory. To achieve low latency, you still process the data in chunks, but instead of having to enqueue N kernels for each chunk, you must only enqueue a single Producer and Consumer kernel per chunk. This enables you to reduce the lower bound on the latency to MAX(2 x tlaunch, tlaunch + tfinish). Observe that this lower bound does not depend on the number of kernels in your system (N).
Use this method only when N > 2. FPGA area is sacrificed to implement the Producer, Consumer, and their pipes to achieve lower overall processing latency.
Limitations
Fundamentally, the ability to stream data between the host and device is built around SYCL USM host allocations. The underlying problem is how to efficiently synchronize between the host and device to signal that some data is ready to be processed, or has been processed. In other words, how does the host signal to the device that some data is ready to be processed? Conversely, how does the device signal to the host that some data is done being processed?
One method to achieve this signaling is to use the start of a kernel to signal to the device that data is ready to be processed, and the end of a kernel to signal to the host that data has been processed. This is the approach taken in the examples discussed above. However, this method has two notable drawbacks. First, the latency to start and end kernels is high. To maintain high throughput, you must size the chunk_size sufficiently large to hide the inter-kernel latency, resulting in a latency increase. Second, the programming model to achieve this performance is non-trivial as you must intelligently manage the SYCL device queue.