What Is the Maxloc Operation?
Finding the location of the maximum value (maxloc) is a common search operation performed on arrays. It’s such a common operation that many programming languages and libraries provide intrinsic maxloc functions: the NumPy argmax, Fortran maxloc, BLAS amax, and C++ max_element functions. The recent article, Optimize the Maxloc Operation Using Intel® AVX-512 Instructions (The Parallel Universe, Issue 46), explained how to vectorize maxloc searches for best performance. Obviously, it’s an important operation in many algorithms, including cross-correlation (Figure 1).
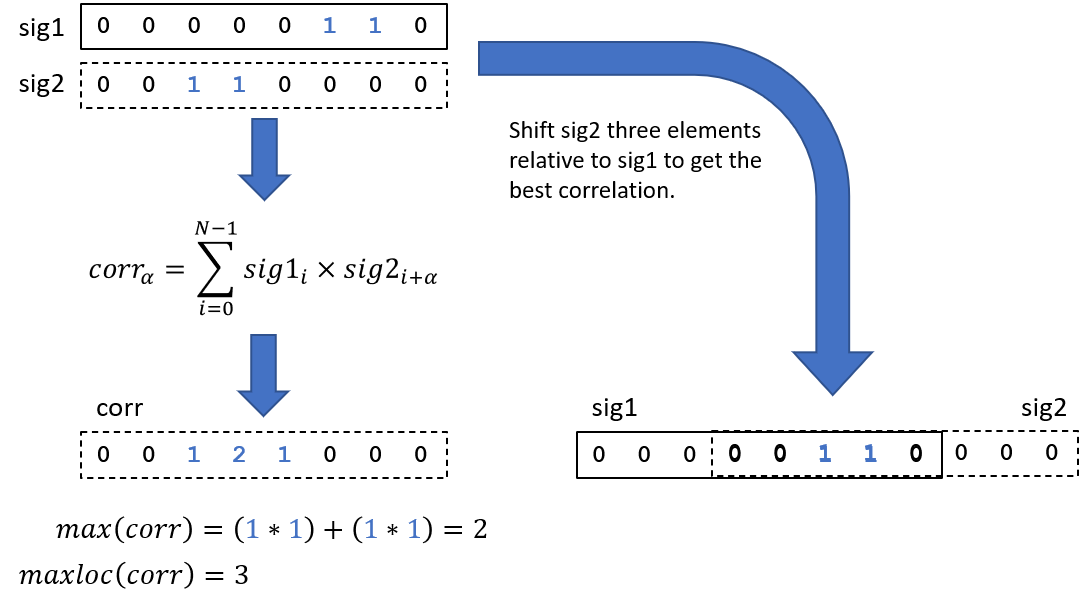
Figure 1. Finding the displacement that gives the maximum overlap of two discrete signals (represented as binary arrays), where α is the number of elements by which sig2 is shifted relative to sig1. Note that the second signal is circularly shifted when computing the correlation.
The previous article, Implement the Fourier Correlation Algorithm Using oneAPI (The Parallel Universe, Issue 44), showed how to compute the 1D cross-correlation of two signals using a combination of SYCL and oneMKL functions, but the final maxloc step was ommitted (Figure 2). Steps 1 through 3 were offloaded to the accelerator device, but step 4 was computed on the host CPU. This means that the final correlation array had to be transferred back to the host. Ideally, the entire computation should be performed on the device once the signals are loaded into the device memory. Only the final displacement (a single scalar in the 1D correlation) is needed by the host. Any other host-device data transfer is unnecessary and could hurt performance. Therefore, we've been experimenting with different ways to perform maxloc on the device, which is the subject of the present article.

Figure 2. The maxloc reduction is the last step of the Fourier correlation algorithm. DFT is the discrete Fourier transform, IDFT is the inverse DFT, CONJG is the complex conjugate, and MAXLOC is the location of the maximum correlation score.
Reduction Operators in SYCL*
Reduction is a common parallel pattern that reduces several values to a single value. For example, a summation reduction adds the values in an array to get a single sum. Finding the minimum or maximum value in an array, or the locations of those values, are also reduction operations. SYCL* provides a built-in reduction operator that can be used in parallel kernels (Figure 3).

Figure 3. Example of summation reduction in SYCL.
It is possible to implement other operators, like maxloc, using the SYCL reduction class (Figure 4). This code was adapted from the minloc example in Data Parallel C++: Mastering DPC++ for Programming of Heterogeneous Systems Using C++ and SYCL (Chapter 14, Common Reduction Patterns, pp. 334–339). Note that SYCL queues are asynchronous, so the wait statement ensures that the computation is finished before proceeding.

Figure 4. Implementing maxloc as a SYCL reduction operator.
This example is a straightforward use of the SYCL reduction class, but there are ways to tune for the underlying architecture. The previous articles, Reduction Operations in Data Parallel C++ (The Parallel Universe, Issue 44) and Analyzing the Performance of Reduction Operations in DPC++ (The Parallel Universe, Issue 45), give examples of different implementations and their performance characteristics. With the built-in reduction operator, however, compiler and library developers bear the optimization burden. Application developers can reasonably expect that the built-in implementation will deliver good performance on the target CPU or accelerator.
Doing the Same Reduction with oneDPL
The Intel® oneAPI Data Parallel C++ Library (oneDPL) provides an alternative for programmers who would rather call a function than use the SYCL reduction class. From Data Parallel C++ (p. 339):
“The C++ Standard Template Library (STL) contains several algorithms which correspond to the parallel patterns... The algorithms in the STL typically apply to sequences specified by pairs of iterators and — starting with C++17 — support an execution policy argument denoting whether they should be executed sequentially or in parallel. [oneDPL] leverages this execution policy argument to provide a high-productivity approach to parallel programming that leverages kernels written in DPC++ under the hood. If an application can be expressed solely using functionality of the STL algorithms, oneDPL makes it possible to make use of the accelerators in our systems without writing a single line of DPC++ kernel code!"
There’s a lot to like in this description, but let's highlight two points:
- C++ STL: The functions will be familiar to C++ programmers.
- High productivity: The coding and performance burden is on the STL developers, where it belongs. The application developer can access an accelerator without writing lower-level SYCL kernels.
The advantages become apparent when you compare the kernel-based maxloc code (Figure 4) to the oneDPL implementation (Figure 5). The latter uses the familiar max_element function to perform the maxloc reduction. SYCL kernels are leveraged “under the hood,” as noted in the previous quote. The oneDPL default execution policy places the computation on an accelerator if one is available. Otherwise, the computation runs on the host CPU.

Figure 5. Basic maxloc reduction using the oneDPL max_element and distance functions and implicit host-device data transfer.
Notice that host-device data transfer is being handled implicitly in Figure 5. The oneDPL runtime automatically wraps the data in a temporary buffer if the computation is being offloaded to an accelerator. In a larger oneAPI program, it’s possible that the data are already in SYCL buffers, so oneDPL functions accept buffers and can iterate over them (Figure 6). Whether the buffered data are transferred to the device implicitly or explicitly (i.e., via SYCL buffers), the buffers don’t need to be transferred back to the host unless they are modified, thus avoiding unnecessary overhead.

Figure 6. Maxloc reduction using oneDPL and SYCL buffering for explicit host-device data transfer.
The oneDPL functions also accept pointers to unified shared memory (USM) to handle host-device data transfer (Figure 7). In this example, space is allocated in the appropriate USM, using the SYCL malloc_shared function and a SYCL queue. The same queue is used to set the oneDPL execution policy. It is worth noting that oneDPL algorithms are synchronous, so there are no explicit wait statements in Figures 5–7. SYCL kernels, on the other hand, are asynchronous.

Figure 7. Maxloc reduction using oneDPL and USM for host-device data transfer.
When Should I Use a SYCL Reduction or oneDPL?
Like many programming questions, there’s no definitive answer. There are valid reasons for using one or the other approach. It depends on your requirements. If oneDPL provides an algorithm that matches your requirements, calling a standard function is simpler than writing a SYCL kernel. For example, if there’s already a big array in device memory and only the scalar output from the reduction is required by the host, calling the oneDPL function is probably best. However, the function call is synchronous, so the program blocks until the function returns, which is not always desirable. The SYCL reduction is more complicated, but it is asynchronous, more flexible, and provides more tuning opportunities. For example, if you’re transforming the data on which the reduction is being performed or performing multiple reductions simultaneously, writing a SYCL kernel might be preferable.
The separation of concerns between applications developers and compiler/library developers is a recurring theme in The Parallel Universe. The latter group is primarily concerned with performance and computing efficiency. The former group is primarily concerned with solving a problem as productively as possible. If you’re in this group, you probably prefer high-level programming abstractions that still deliver performance. The SYCL maxloc reduction operator shown in Figure 4 is complicated, low level, and may require some architecture-specific tuning (e.g., of work-group sizes) to achieve best performance. The oneDPL examples shown in Figures 5–7 are simpler, familiar to C++ STL users, and versatile in terms of host-device data transfer. More importantly, they shift the tuning burden to oneDPL product developers who are mainly concerned about performance. Consequently, oneDPL functions should deliver good performance regardless of the underlying architecture. This is the promise of the oneAPI software abstraction for heterogeneous computing.
Five Outstanding Additions Found in SYCL 2020
Read
Winning the NeurIPS BillionScale Approximate Nearest Neighbor Search Challenge
Read
Accelerating the 2D Fourier Correlation Algorithm with ArrayFire and oneAPI
Read
More Productive and Performant C++ Programming with oneDPL
Read
Optimizing Artificial Intelligence Applications
Read
Optimizing End-to-End Artificial Intelligence Pipelines
Read