Similarity search, also known as approximate nearest neighbor (ANN) search, is the backbone of many AI applications that require search, recommendation, and ranking operations on web-scale databases. Accuracy, speed, scale, cost, and quality-of-service constraints are critical. In this article, we describe a solution that advances these dimensions by leveraging the computational capabilities of Intel® Xeon® processors and Intel® Optane™ memory. To showcase these advances, we participated in the NeurIPS’21 Billion-Scale ANN Search Challenge, winning the Custom Hardware Track. Our results offer an 8x to 19x reduction in CAPEX and five-year OPEX at iso-performance over the next-best solution. This promises to drastically lower the entry barrier and democratizes similarity search in the modern, large-scale, high accuracy and high-performance scenario.
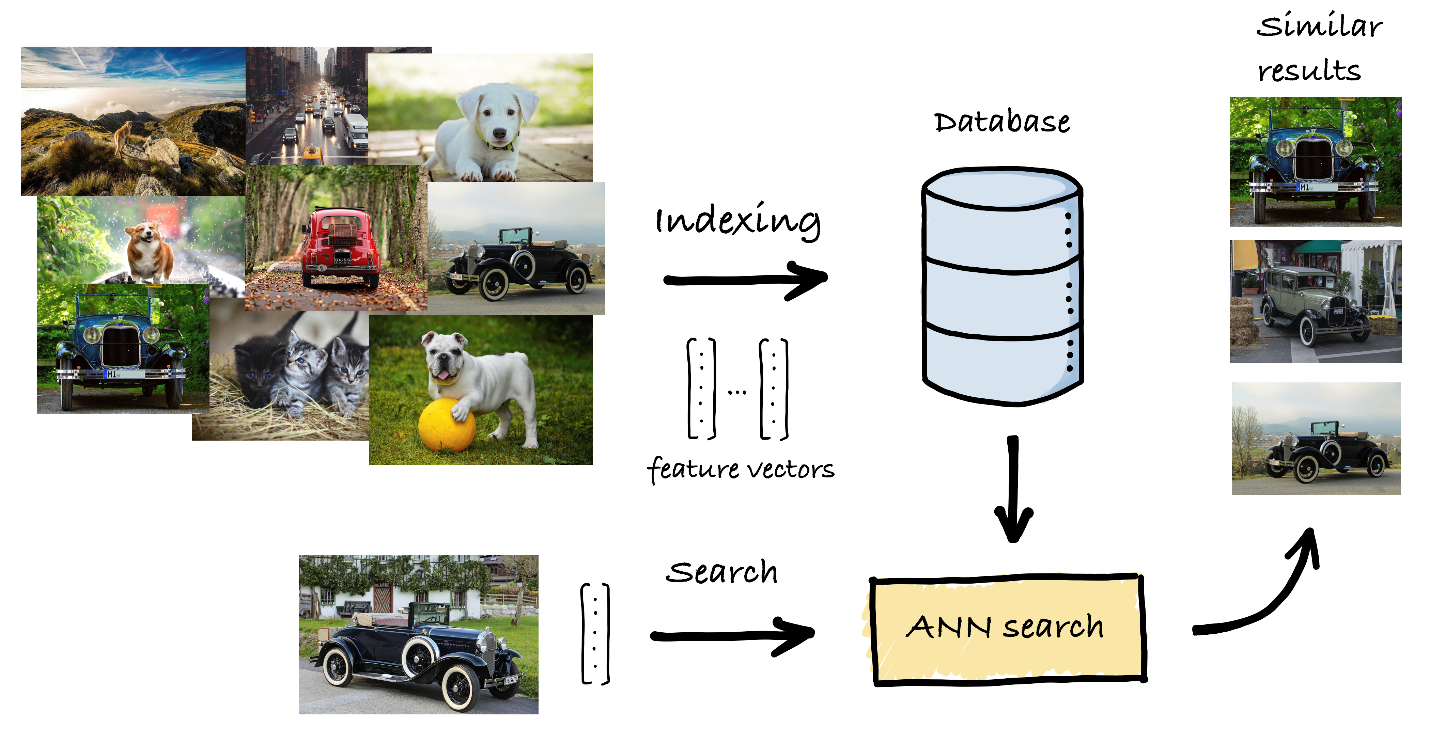
Figure 1. Schematic representation of an ANN search pipeline.
Approximate Nearest Neighbor Search
Given a database of high-dimensional feature vectors and a query vector of the same dimension, the objective of similarity search is to retrieve the database vectors that are most similar to the query, based on some similarity function (Figure 1). In modern applications, these vectors represent the content of data (images, sounds, text, etc.), extracted and summarized using deep learning systems such that similar vectors correspond to items that are semantically related. To be useful in practice, a similarity search solution needs to provide value across different dimensions:
- Accuracy: The search results need to be of sufficient quality to be actionable (that is, the retrieved items need to be similar to the query).
- Performance: The search needs to be fast, often meeting strict quality-of-service constraints.
- Scalability: Databases continue to get larger in terms of the number of items they contain and the dimensionality of those items.
- Cost: Being deployed in production and data center scenarios, the solution needs to minimize the total cost of ownership (TCO), often measured as a combination of capital expenditures (CAPEX) and operating expenses (OPEX).
A natural solution is to linearly scan over each vector in the database, compare it with the query, rank the results in descending order of similarity, and then return the most similar vectors. However, the sheer volume and richness of data preclude this approach and make large-scale similarity search an extremely challenging problem that is both compute- and memory-intensive. Better solutions are needed, which commonly involve two phases:
- During indexing, each element in the database is converted into a high-dimensional vector, and then an index is created so that only a fraction of the database is accessed during the search.
- At search time, given a query vector, an algorithm sifts through the database using the index. Its results are used to take different informed actions depending on the final application and based on these semantically relevant results.
The NeurIPS’21 Billion-Scale Approximate Nearest Neighbor Search Challenge
In December 2021, the first billion-scale similarity search competition was organized as part of the NeurIPS conference. The goal of the competition was to provide a comparative understanding of a state-of-the-art similarity search across a curated collection of real-world datasets and to promote the development of new solutions. We participated in the competition’s Custom Hardware Track, where we could take full advantage of Intel’s hardware offerings. We developed a solution that fully leveraged the capabilities of Intel Xeon processors and Intel Optane persistent memory (PMem), creating a one-two approach that eventually won the competition.
The fundamental metric compared across datasets was TCO, defined as CAPEX + five-year OPEX of the solutions at 90% recall and 100,000 queries-per-second (QPS) throughput. The CAPEX and OPEX are defined by the competition organizers as follows:
- CAPEX = (MSRP of all the hardware components) x (minimum number of systems needed to scale to support 100,000 QPS)
- OPEX = (maximum QPS at or greater than the baseline recall @10 threshold) x (kilowatt-hour/query) x (seconds/hour) x (hours/year) x (five years) x (dollars/kilowatt-hour) x (minimum number of systems needed to scale to support 100,000 QPS).
These metrics balance the energy efficiency (through OPEX) and raw performance (through CAPEX) for each solution.
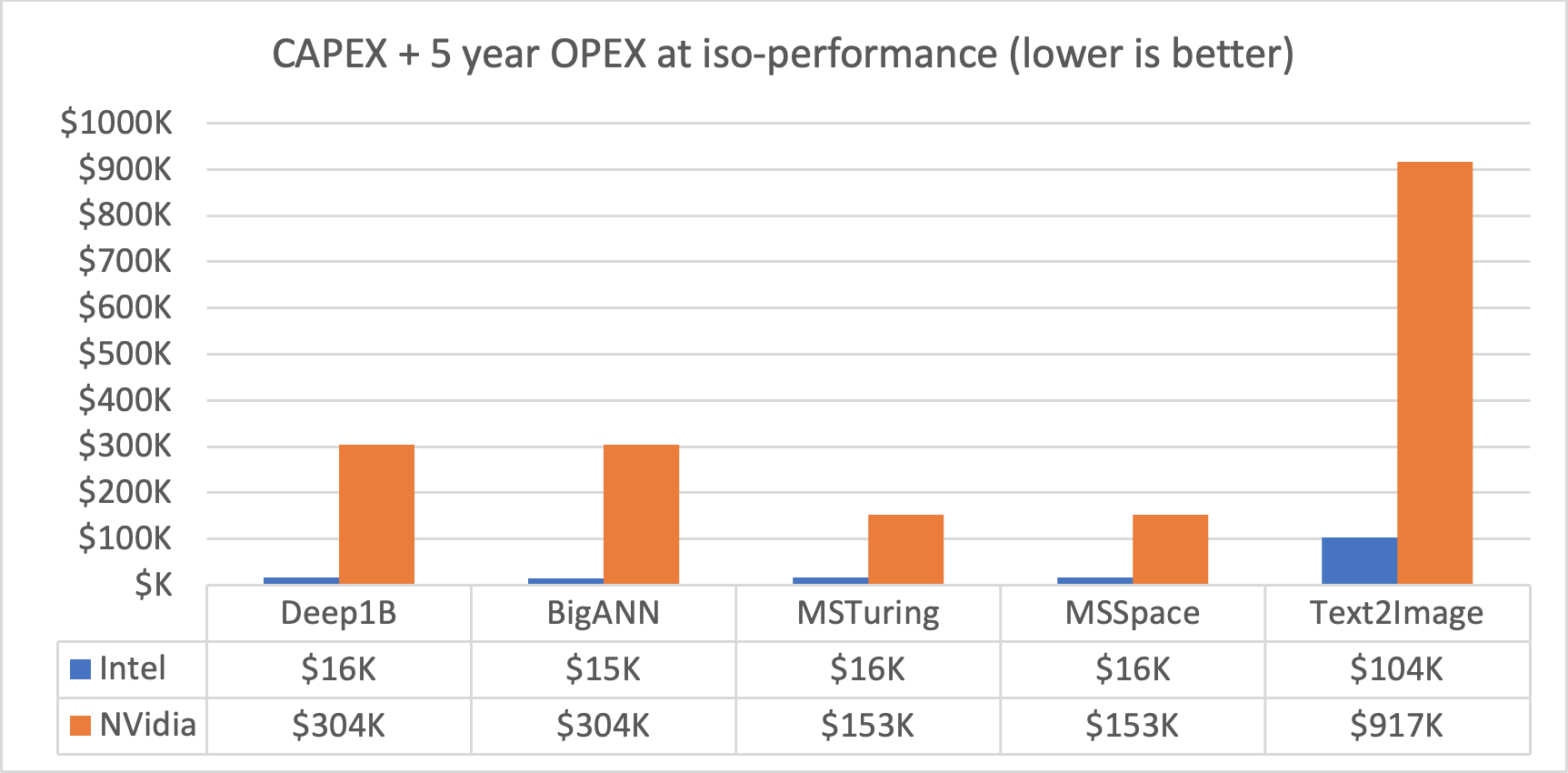
Figure 2. TCO difference between the winning Intel solution and the second place NVIDIA solution, showing up to 20x improvement across five different datasets (x-axis).
Our solution offers a breakthrough improvement in TCO and is between 8.85x and 19.7x better than the second-best solution, NVIDIA's cuanns_multigpu that uses a DGX A100 GPU system across multiple datasets (Figure 2). The stark difference in efficiency of our solution is apparent when comparing the hardware configurations of our first-place entry and NVIDIA’s second-place entry (Table 1). A single inexpensive 1U 2S Intel Xeon server with Intel Optane PMem can achieve the same performance as two of NVIDIA’s flagship DGX A100 servers with eight A100 GPUs and two 64-core CPUs for ANN search workloads.
| Intel® Xeon® processor + Intel® Optane™ memory | NVIDIA DGX A100 | |
|---|---|---|
| CPU | Dual Intel Xeon Gold 6330N processors 56 cores total |
Dual AMD Rome 7742 128 cores total |
| System memory | 512GB DDR4 2TB Intel Optane DCPMM 200 Series |
2TB DDR4 |
| GPU | None | 8x NVIDIA A100 80 GB GPUs |
| GPU memory | None | 640 GB |
| Power | Up to 1.2 kW | Up to 6.5 kW |
| Total cost | $14,664 | $150,000+ |
Table 1. Comparing Intel and NVIDIA hardware configurations for the BigANN competition. These configurations achieve similar performance
In addition to the significantly low CAPEX of the Intel solution at iso-performance, the power efficiency is also significantly better, as shown by the energy per query (in Joules), measured by standard IPMI interface on all machines in the competition. The energy per query of the Intel solution is up to 5x better than the NVIDIA solution (Figure 3). This translates to much better OPEX over a long period, as well as a much more sustainable solution to the ANN search problem.
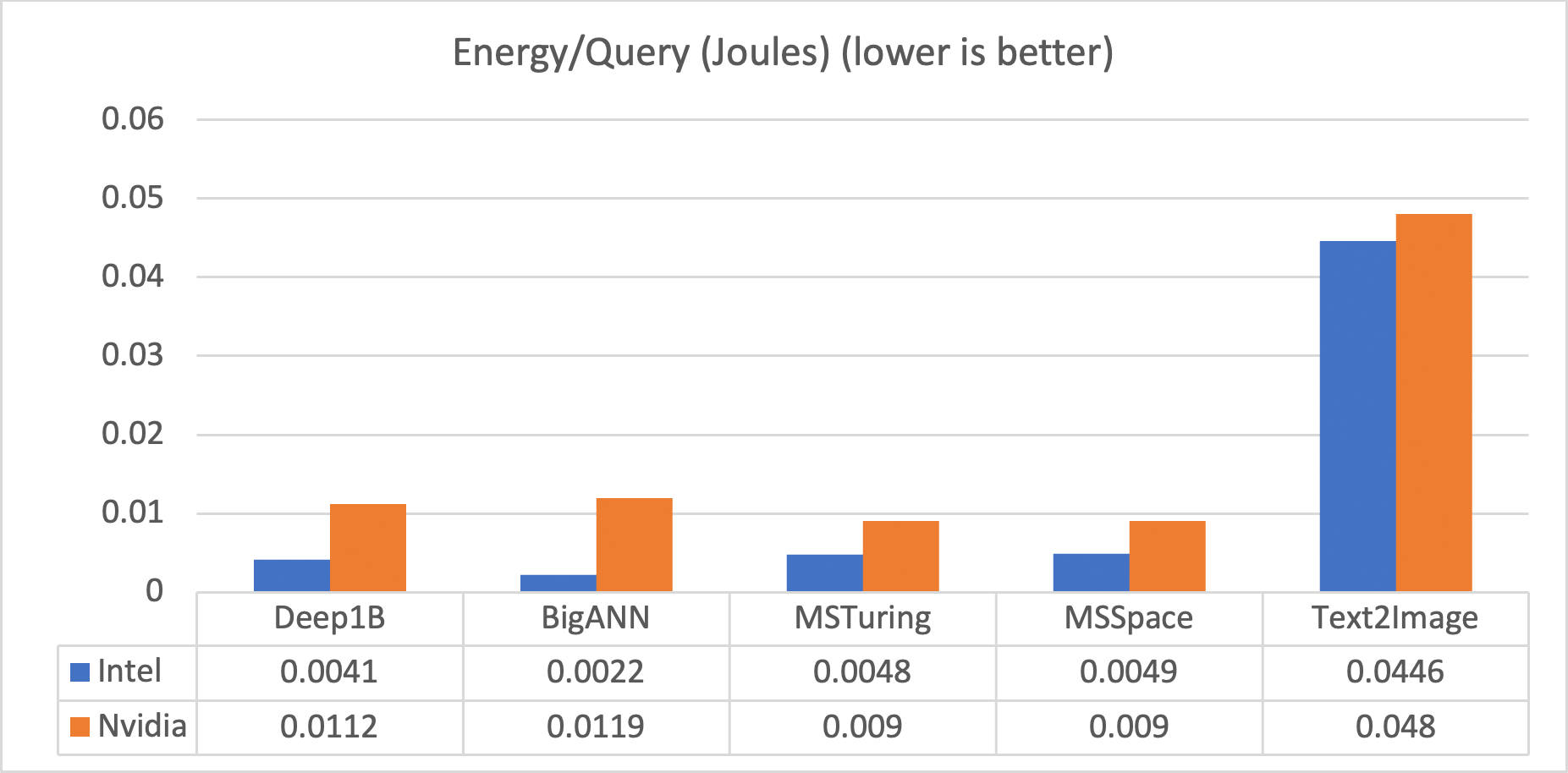
Figure 3. Energy efficiency of the Intel® solution is up to 5x better than the NVIDIA solution across all datasets.
These drastic improvements in TCO are enabled by unique advantages of Intel Xeon processors and the capacity and throughput of Intel Optane PMem, as well as the algorithmic innovation that enables optimal utilization of the hardware resources. In the following sections, we provide the details of how this combined hardware/software approach helped us win this competition by such huge margins.
Algorithmic Approach
We showcase the performance of Intel Xeon processors with Intel Optane PMem for ANN search algorithm, GraphANN. GraphANN is an extension of the graph-based Vamana algorithm that is highly optimized for Intel Optane PMem. It builds a directed graph to index the data points and follows a greedy search to navigate the graph and locate the nearest neighbors of a new query. Throughout the search, two main data structures are used: the graph and the feature vectors. In our solution, we store the graph in Intel Optane PMem and keep the feature vectors in DRAM, when possible. This combination yields impressive throughput and performance per dollar. Moreover, Intel Optane PMem comes in much higher capacities than traditional DRAM, thus providing the necessary scaling for larger datasets. Finally, persistence has the bonus of eliminating the need to load the index into memory, which is quite time-consuming for billion-scale datasets.
Intel® Optane™ Persistent Memory (PMem)
Intel Optane PMem is a storage class memory that can be used in SSDs and persistent memory applications. Historically, there has always been a gap between the memory and storage performance. Intel Optane memory technology is designed to bridge this gap (Figure 4). It allows memory cells to be addressed individually, in a dense, transistor-less, stackable 3D design. These features provide a unique combination of affordable capacity and support for data persistence. With innovative technology offering distinctive operating modes, it adapts to different needs across workloads. For example, Intel Optane technology has been used to accelerate storage of logs and caching tier of large-scale applications with storage bottlenecks.
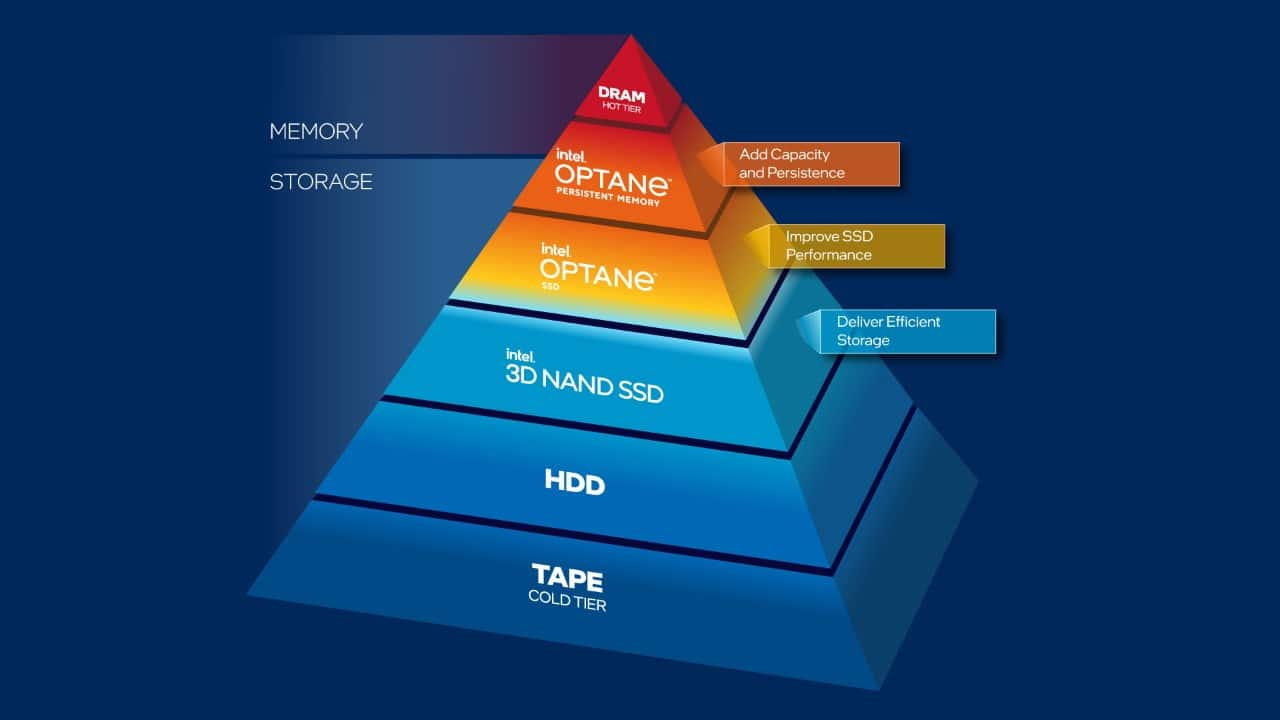
Figure 4. Memory and storage hierarchy and Intel® Optane™ technology's place in it.
Intel Optane PMem has some similarities with DRAM: It is packaged in DIMMs, it resides on the same bus/channels as DRAM, and it can act in the same way as DRAM storing volatile data. It differs from DRAM in the following ways:
- Intel Optane PMem comes in much higher capacities than traditional DRAM. Its modules come in 128GB, 256GB, and 512GB capacities, vastly larger than DRAM modules that typically range from 16GB to 64GB, though larger DRAM capacities exist.
- Intel Optane PMem can also operate in a persistent mode, storing data even without power applied to the module and comes with built-in hardware encryption to help keep data at rest secure. The TCO is greatly improved compared to DRAM on a cost-per-GB basis and the ability to increase the capacity to beyond DRAM’s capabilities.
Intel Optane PMem has two operational modes for additional flexibility: Memory Mode and App Direct Mode. Memory Mode expands main memory capacity without persistence. It combines an Intel Optane PMem with a conventional DRAM that serves as a direct-mapped cache for PMem. In App Direct Mode, Intel Optane PMem appears as a persistent memory device that can be addressed separately from DRAM.
ANN with Intel® Optane™ Persistent Memory (PMem)
By studying the access patterns of the Vamana algorithm, we found that data reuse across queries is limited. This discourages the use of Intel Optane Memory Mode, as a cache would provide limited value. Therefore, we used App Direct Mode for this work.
To maximize performance, we organize the data by storing the graph in Intel Optane PMem while keeping the feature vectors in DRAM. The graph accesses follow a highly random and non-local pattern. Here, Intel Optane PMem has a 64-byte block size, which allows us to surgically access the graph elements while retaining performance. We limit the maximum out-degree of each node to 127, as this ensures that exactly four accesses are needed to retrieve the neighbors of any given node. (We use 4B per neighbor and 4B for the number of neighbors.) Storing the data contiguously allows pipelining of these four accesses.
Our optimized version of the Vamana algorithm is written in the Julia programming language. The optimizations can be divided into general (purely software-based) and specific to Intel Optane technology. The general optimizations relate to optimized graph and data representations, use of VNNI instructions for distance computation, static sizing of data vectors, and memory alignment, among others. One such important optimization is “prefetch hoisting,” which decouples the distance computation loop from the vector-fetching loop. In this approach, we use x86 intrinsics to prefetch as much data as possible from memory before beginning the distance computation step. This ensures that memory latency has minimal impact on the queries. The other important optimization results from partitioning the vectors between DRAM and PMem. This is because fetching the vectors for distance computation is the slowest step in the search, and we keep as many vectors as possible in DRAM, which reduces the PMem traffic and provides a significant performance improvement.
Our multithreaded architecture creates small batches of queries that are dynamically load-balanced across worker threads. Each thread processes one query at a time in its batch. Furthermore, all intermediate scratch-space data structures required to process a query are pre-allocated, with each thread owning its own private scratch space. This eliminates dynamic memory allocation during the query processing and minimizes the amount of synchronization among threads.
These optimizations allow us to deliver orders of more than10 to100X improvement in ANN search performance over the previous known best solution (the FAISS algorithm running on GPUs). Figure 5 shows the improvement achieved by our optimized approach across five different datasets. These datasets encompass different encodings (Int8, UInt8, and Float32), as well as different distance metrics (Euclidean and Inner Product). We can see that across these datasets, GraphANN running on an Intel Xeon processor with Intel Optane memory drastically improves the baseline performance.
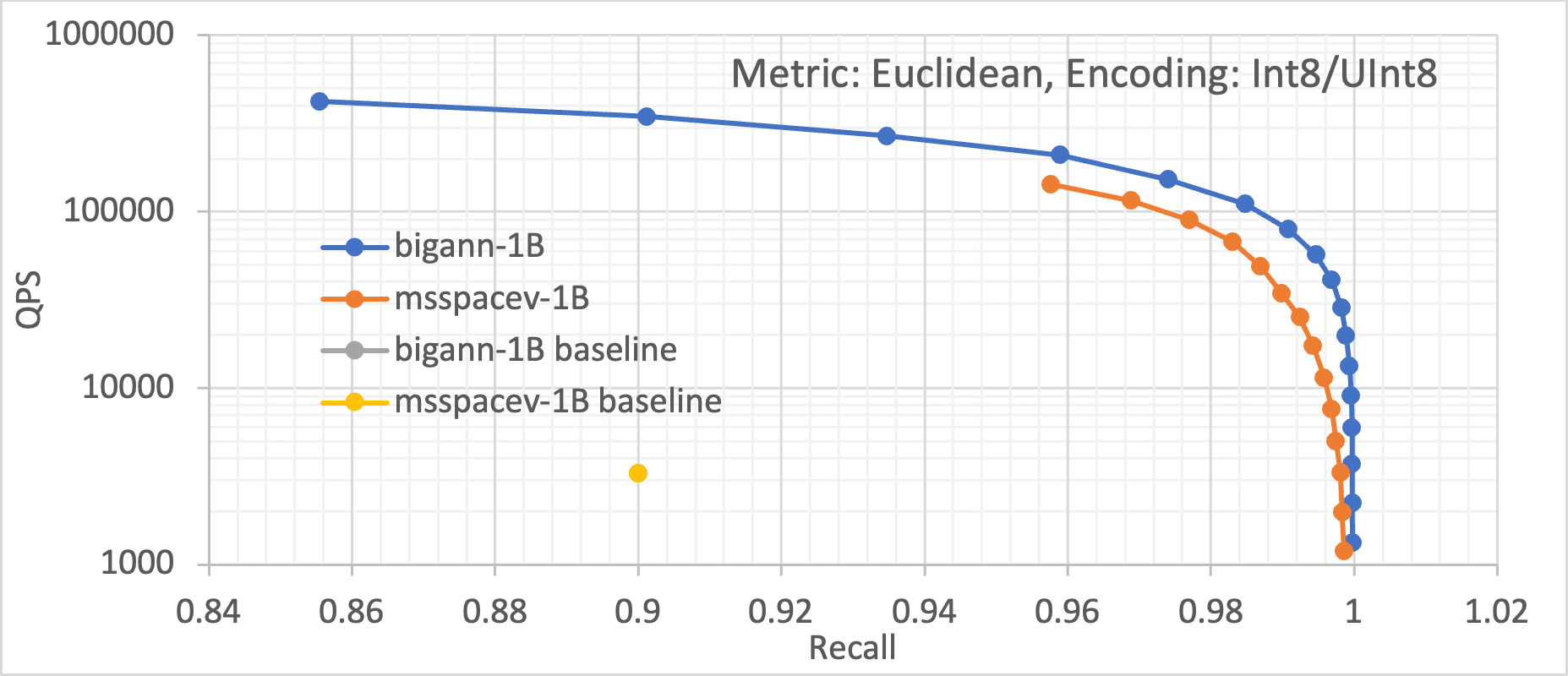
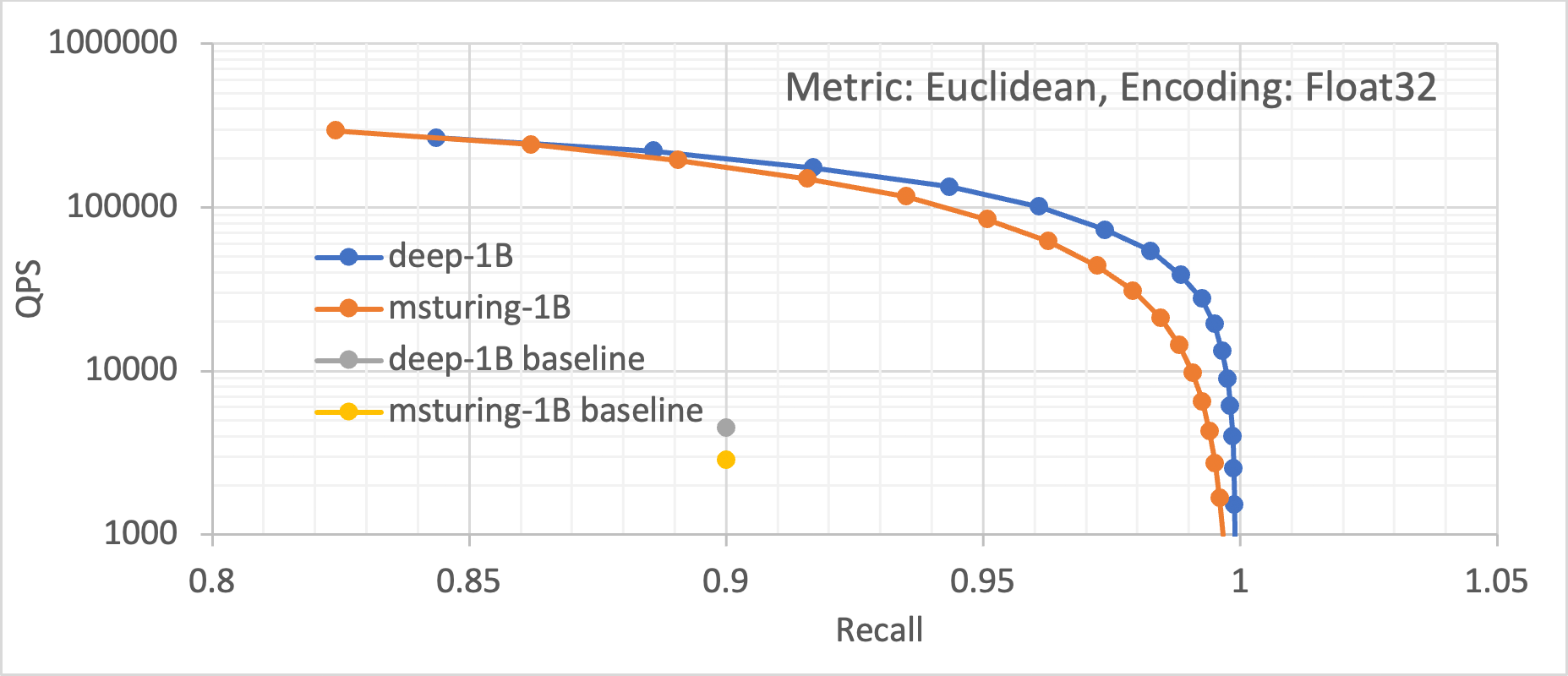
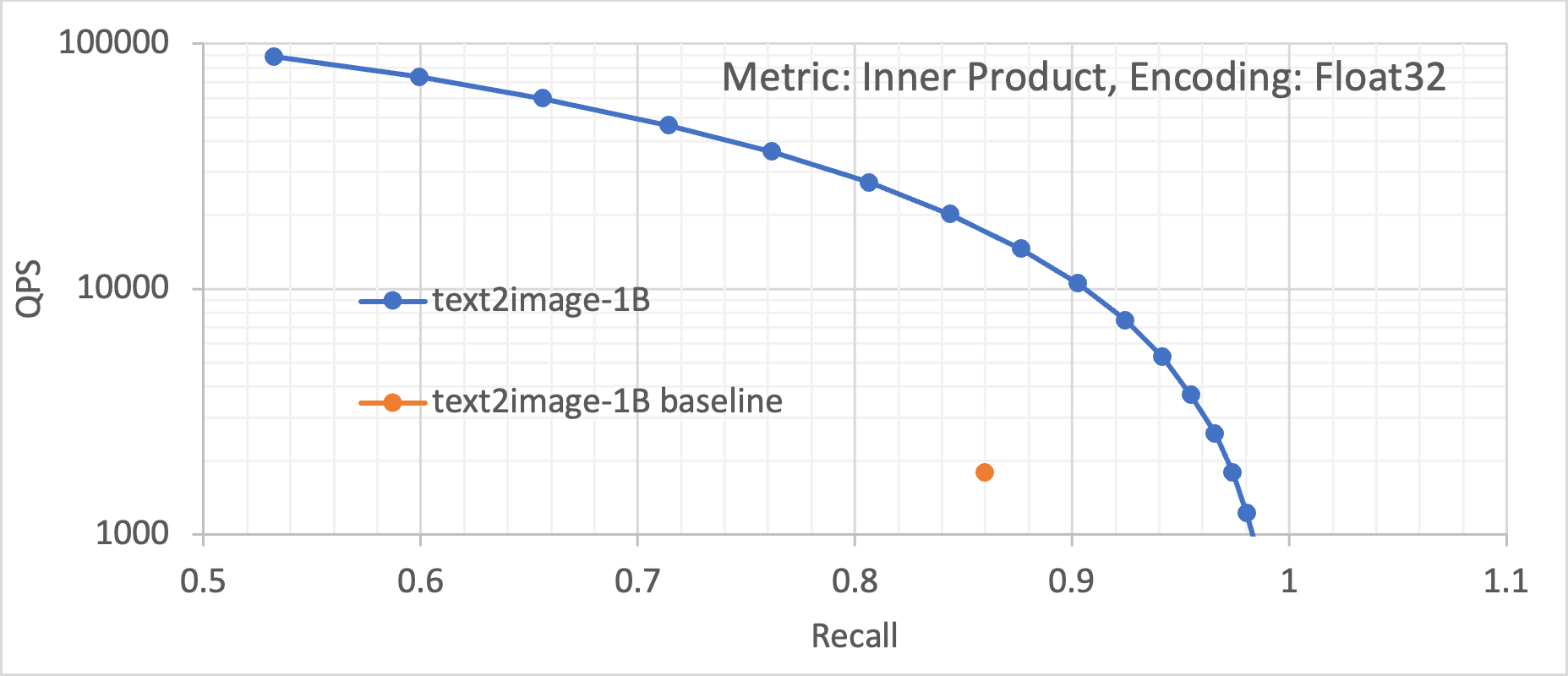
Figure 5. Queries per second (throughput) vs recall plots for the five different datasets, showing the magnitude of improvement of the Intel® Optane™ solution over the previously best software (FAISS) and hardware (GPUs).
Conclusion
In this article, we described the winning algorithm, design choices, and associated hardware setup in the Billion-Scale Approximate Nearest Neighbor Search Challenge in the NeurIPS 2021 (see the public leaderboard). We also showed that Intel Optane PMem can significantly improve the performance of similarity search algorithms across a range of design points, starting from only upgrading the hardware without any associated code changes to a full-blown custom rewrite of code.
Five Outstanding Additions Found in SYCL 2020
Read
Accelerating the 2D Fourier Correlation Algorithm with ArrayFire and oneAPI
Read
The Maxloc Reduction in oneAPI
Read
More Productive and Performant C++ Programming with oneDPL
Read
Optimizing Artificial Intelligence Applications
Read
Optimizing End-to-End Artificial Intelligence Pipelines
Read