We have come a long way since 2005 when Herb Sutter declared that “the free lunch is over,” referring to challenges that programmers face with emerging multicore processors. Today’s portfolio of computing architectures and accelerators is even richer and constantly growing: a development driven by fundamental limitations of semiconductors and the desire for more powerful, energy-efficient computing. The computing world is becoming more and more heterogeneous, which creates challenges for programmers.
C++ is still among the five most popular programming languages (TIOBE ranks it #4 as of January 2022). Attributes like full control over memory management and support for generic programming make it a great language to tackle heterogeneous programming challenges. Developer productivity and the cost of code maintenance are common concerns when choosing a programming language. Fortunately, previous studies show that we can expect a productivity boost by combining parallel building blocks with C++ algorithms. For example, optimized, built-in implementations of common functions and patterns (e.g., reduction) for specific architectures improve both performance and developer productivity.1, 2
Our industry-leading implementation of the Intel® oneAPI Data Parallel C++ Library (oneDPL) was contributed to the open-source LLVM project. As a result, developer effort can be significantly reduced in a multithreaded world.1, 6
Supercharged Classic STL Algorithms
Boost your code with something old and something new.
The C++ language itself is evolving, and so is its standard template library (STL). For example, five years ago execution policies were added to the algorithms library so that even existing C++ codes can benefit from the ubiquitous parallelism of modern processors. You can think of oneDPL as a supercharged C++ STL that allows different vendors to implement accelerated versions of classic algorithms in a portable way.
oneDPL implements the C++ algorithms library using SYCL*:
“SYCL (pronounced ‘sickle’) is a royalty-free, cross-platform abstraction layer that enables code for heterogeneous processors to be written using standard ISO C++ with the host and kernel code for an application contained in the same source file.” 3
There is a learning curve for direct accelerator programming in SYCL. While C++ gives programmers full control over memory management, it has no concept of separate host and device memories. oneDPL relies on SYCL’s memory abstraction as a portable way to share data between host and device(s). oneDPL algorithm functions are ready to use, familiar to C++ programmers, and optimized for a variety of accelerators. This flattens the learning curve and improves code performance and developer productivity.
Here’s a simple example to illustrate the power of oneDPL:
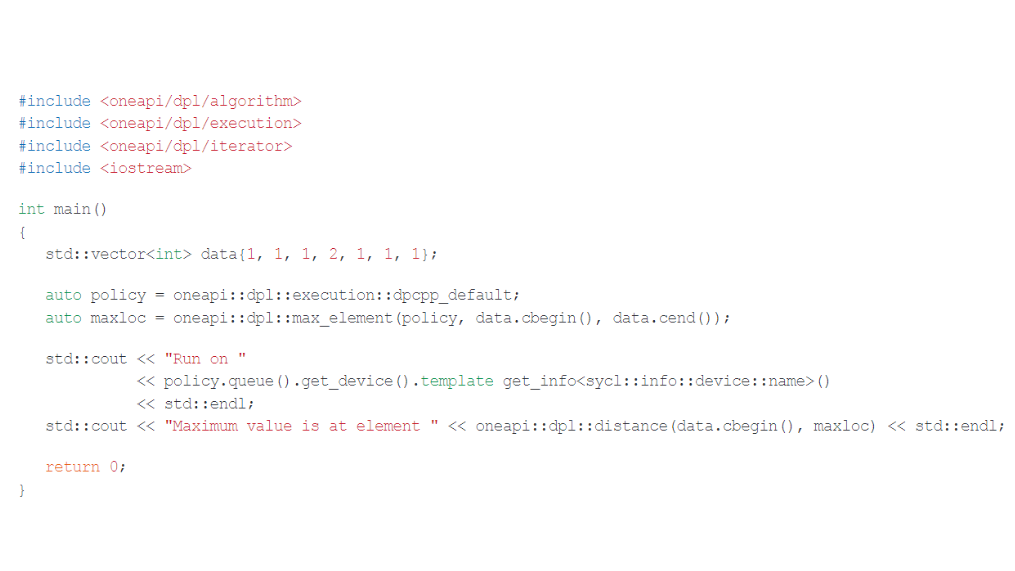
This example offloads the common maxloc reduction (i.e., finding the element in the data set with the maximum value) to the accelerator specified in the execution policy. The included headers are conformant with ISO C++, and so is the blocking behavior of max_element. Data movement is handled implicitly in this example. In other words, the runtime automatically handles host-device data transfer by wrapping the data in a SYCL buffer if the computation is offloaded to an accelerator. Other modes exist that allow the programmer to explicitly control host-device data transfer.
In addition to parallel algorithm implementations in SYCL, oneDPL is supporting essential extensions for device programming such as custom iterators. To ensure interoperability across different platforms such extensions were added to the oneDPL specification.4
What’s Next?
A Look into the Crystal Ball
Let’s focus on some powerful, experimental oneDPL features that are currently under development but have not been fully baked into ISO C++, and how to get access to them:
- C++20 introduces Ranges that can greatly improve expressiveness when using C++ STL algorithms. They extend the utility of algorithms by supporting more complex data access patterns with Views. All this with fewer lines of code. As of today, ISO C++ Ranges algorithms are not supporting execution policies, which means it lacks accelerator support. oneDPL enables Ranges for selected algorithms and provides extensions, such as custom SYCL views, to enable device programming.7
- Classic C++ algorithms are well defined, including the blocking behavior of their function calls. However, blocking the host processor is not always desirable when offloading computation to an accelerator. To allow interleaving of host-device execution and data transfer, a set of asynchronous algorithms
have been added to oneDPL. Their functionality is similar to C++ algorithms, but without the blocking behavior. To control nonblocking behavior, a C++ future-like object is returned instead of the result directly.8
There’s more to come. Other exciting features like automatic device selection4 are planned for future release, so stay tuned and follow us on GitHub.
Final Thoughts
oneDPL provides C++ building blocks that combine high performance with high productivity across CPUs, GPUs, FPGAs, and other accelerators. It is based on open standards, and its specification ensures interoperability across different platforms. Intel’s reference implementation is a permissibly licensed open-source project.5
References
- Parallel Research Kernels
- Analyzing Reduction Abstraction Capabilities
- SYCL Programming Language
- oneDPL Specification
- oneAPI DPC++ Library
- How to Boost Performance with Intel Parallel STL and C++17 Parallel Algorithms
- oneDPL Range-based API Algorithms
- oneDPL Asynchronous API Algorithms
Learn more about programming with oneAPI and oneDPL
Five Outstanding Additions Found in SYCL 2020
Read
Winning the NeurIPS BillionScale Approximate Nearest Neighbor Search Challenge
Read
Accelerating the 2D Fourier Correlation Algorithm with ArrayFire and oneAPI
Read
The Maxloc Reduction in oneAPI
Read
Optimizing Artificial Intelligence Applications
Read
Optimizing End-to-End Artificial Intelligence Pipelines
Read