End-to-end (E2E) artificial intelligence (AI) pipelines are made up of one or more machine learning (ML) deep learning (DL) models that solve a problem on a specific dataset and modality, accompanied by multiple preprocessing and postprocessing stages. We apply comprehensive optimization strategies on a variety of modern AI pipelines for ML, natural language processing (NLP), recommendation systems, video analytics, anomaly detection, and face recognition, along with DL/ML model training and inference, optimized data ingestion, feature engineering, media codecs, tokenization, etc. for higher E2E performance. The results across all our candidate pipelines, mostly inference-based, show that for optimal E2E throughput performance, all phases must be optimized. Large memory capacities, AI acceleration (e.g., Intel® Deep Learning Boost [Intel® DL Boost]), and the ability to run general-purpose code make Intel® Xeon® processors well-suited for these pipelines.
Our optimizations fall broadly into application, framework, and library software; model hyperparameters; model optimization; system-level tuning; and workload partitioning. Tools such as Intel® Neural Compressor offer quantization, distillation, pruning, and other techniques that benefit from Intel DL Boost and other AI acceleration built into Intel Xeon processors. As a result, we see a 1.8x to 81.7x improvement across different E2E pipelines. In addition, we can host multiple parallel streams or instances of these pipelines with the high number of cores and memory capacity available on Intel Xeon processors compared to some memory-limited accelerators that can only host one or a very limited number of parallel streams. In many cases, workload consolidation to CPUs is possible, which also has TCO and power advantages.
E2E AI Applications
We showcase many E2E AI use cases and workloads, each comprising unique pre- and post-processing steps and implemented using a variety of different ML/DL approaches on video, image, tabular, text, and other data types (Table 1).
| Workload | Application Name | Model | Pre-/Post-processing Stages | Dataset |
|---|---|---|---|---|
| ML | Census | Ridge Regression | Load data to data frame, drop columns, remove rows, arithmetic ops, type conversion, train/test split | IPUMs Census Data |
| PLAsTiCC | Gradient Boosting Tree | Load data, drop columns, groupby aggregation, arithmetic ops, type conversion, train/test split | LSST Simulated Data | |
| Predictive Analytics in Industrial IoT | Random Forest Classifier | Load data to data frame, drop inessential columns, train/test split | Bosch Production Line | |
| NLP | Document Level Sentiment Analysis | BERT-Large | Load data, initialize tokenizer, data encoding, load mode | IMDb |
| SST-2 | ||||
| Recommendation System | E2E Deep Interest Evolution Network | DIEN | Data ingestion, label encoding, get history sequence, native sampling, data split, load model | Amazon Books |
| Video Analytics | Video Streamer | SSD Resnet-34 | Video decode, image normalization and resizing, bounding box and labeling, data uploading | Mall video |
| Anomaly Detection | Anomaly Detection | ResNet50v1.5 | Load data, image resizing, image transformations, evaluating feature reconstruction error | MVTec AD |
| Face Recognition | Face Detection and Recognition | SSD MobileNet, Resnet50v1.5 | Load video, frame splitting, resizing, output generation | Soccer celebration |
Table 1. E2E AI Applications
E2E AI applications typically involve two broad categories of operations: pre-/post-processing and AI. In Figure 1, we see the breakdown range from 4% to 98% pre-/post-processing to 2% to 96% AI as a fraction of the total E2E run-time.
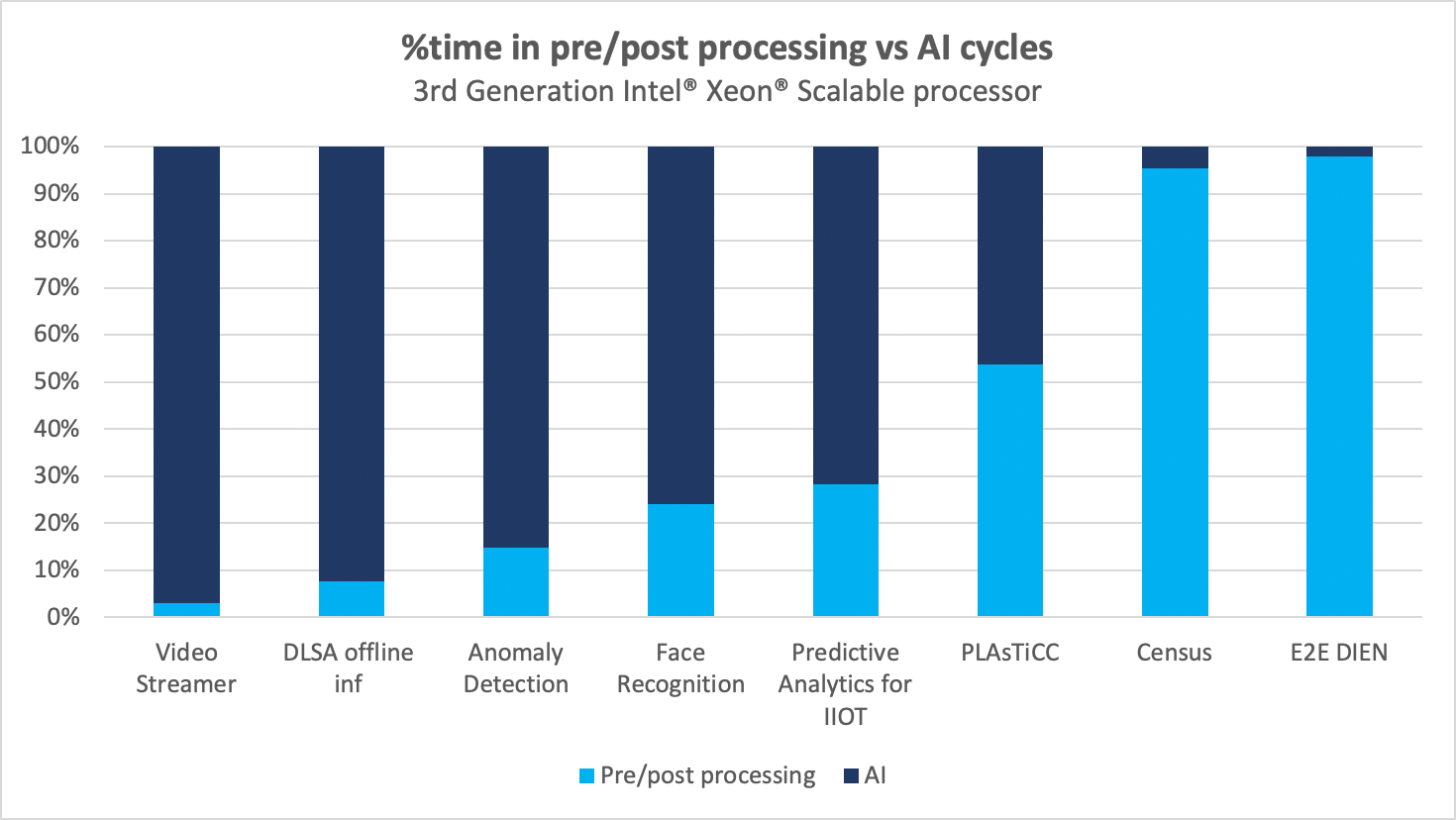
Figure 1. Percent time in pre-/post-processing vs AI
Census
The Census workload trains a ridge-regression model using the U.S. Census data from the years 1970 to 2010, and predicts the correlation between personal education level and income (Figure 2). Prior to ML, it ingests the data, performs data frame operations to prepare the input for model training, and creates a feature set and its subsequent output set1.
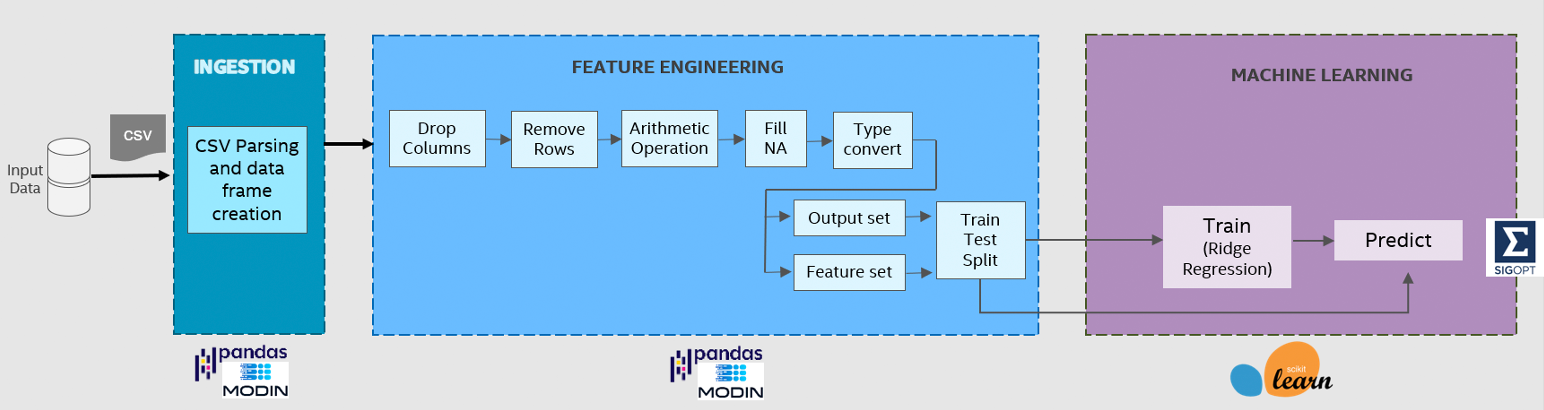
Figure 2. Census application pipeline.
PLAsTiCC
PLAsTiCC is an open data challenge that uses simulated astronomical time-series data to classify objects in the night sky that vary in brightness (Figure 3). The pipeline loads the data; manipulates, transforms, and processes the data frames; and uses the histogram tree method from the XGBoost library to train a classifier and perform model inference.

Figure 3. PLAsTiCC application pipeline.
Predictive Analytics in Industrial IoT
This is an E2E unsupervised learning use case in industrial IoT that predicts internal failures during manufacturing, thereby helping maintain the quality and performance of the production line (Figure 4). The workflow consists of reading measurements from a CSV file and cleaning them to include only the necessary features. The highly optimized Intel® Distribution of Modin2 is used for this step. The random forest classifier from Intel® Extension for Scikit-learn3 is used to generate the model.
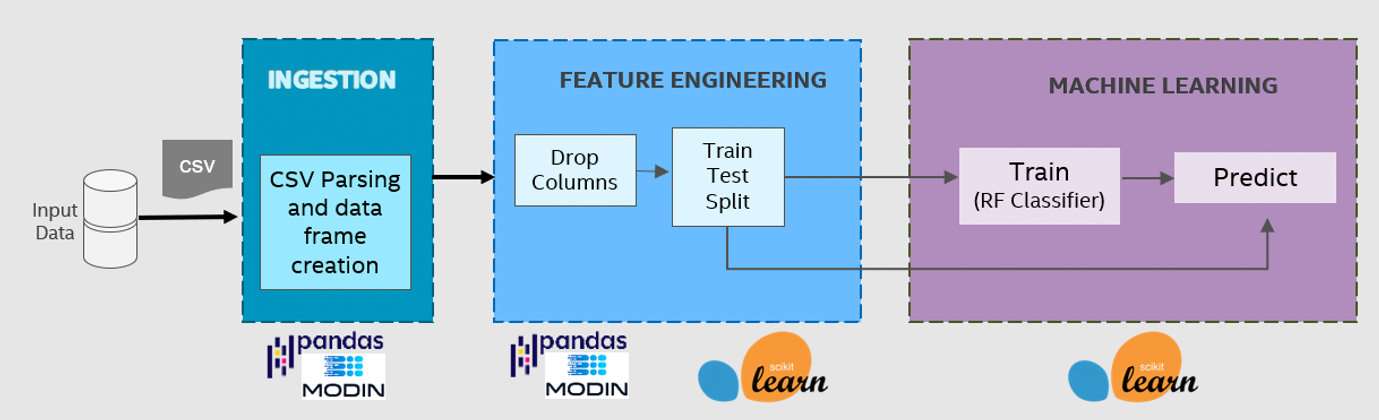
Figure 4. Pipeline for predictive analytics in industrial IoT.
Document Level Sentiment Analysis (DLSA)
The DLSA workflow shown in Figure 5 is a reference NLP pipeline built using the Hugging Face transformer API to perform document-level sentiment analysis. It uses language models such as BERTLARGE (uncased), pretrained on a large English text corpus.
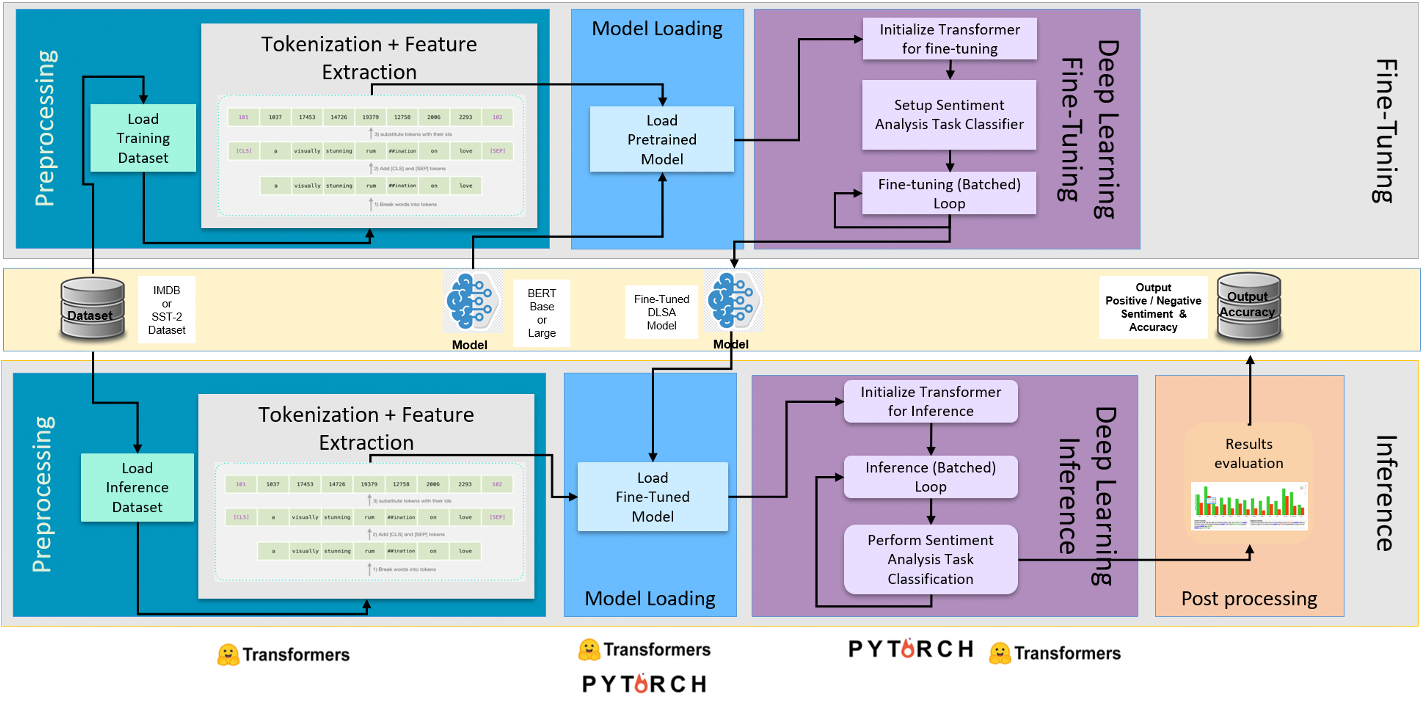
Figure 5. Document level sentiment analysis pipeline.
E2E Deep Interest Evolution Network (DIEN) Recommendation System
The DIEN workflow shown in Figure 6 is a recommendation inference pipeline that estimates the probability of user clicks at scale.
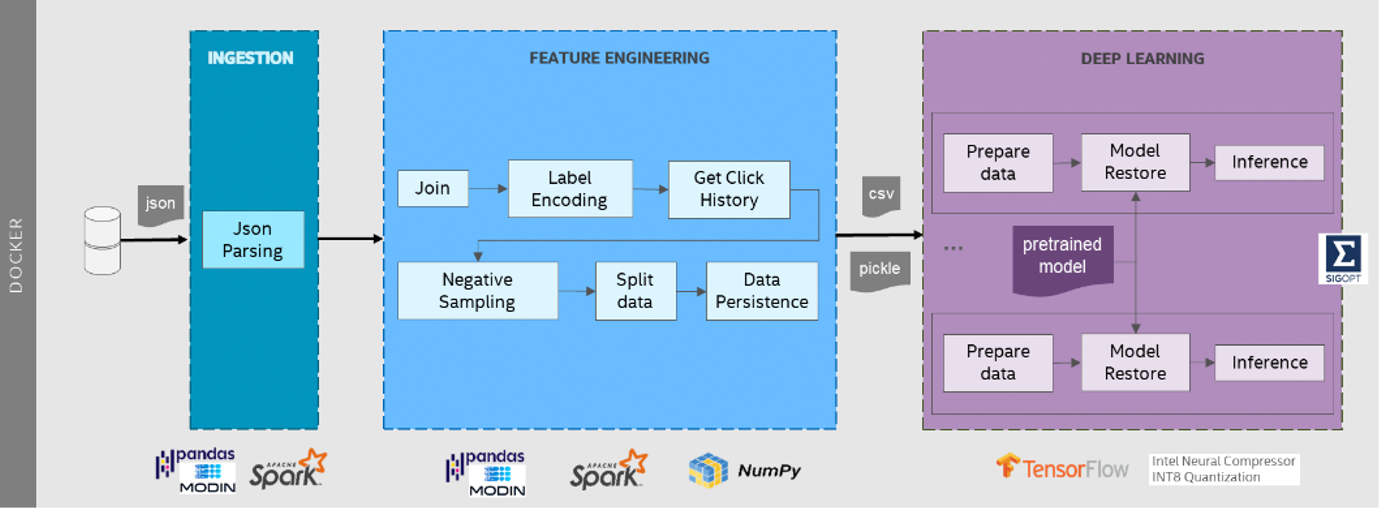
Figure 6. E2E DIEN recommendation system pipeline.
Video Streamer
The video streamer pipeline (Figure 7) is designed to mimic real-time video analytics. Real-time data is provided to an inference endpoint that executes single-shot object detection. The metadata created during inference is then uploaded to a database for curation. The pipeline is built upon GStreamer, TensorFlow, and OpenCV. The input video is decoded by GStreamer into images on a frame-by-frame basis. Then, the GStreamer buffer is converted into a NumPy array. TensorFlow does image normalization and resizing, followed by object detection with a pretrained SSD-ResNet34 model. Finally, the results of bounding-box coordinates and class labels are uploaded to a database.
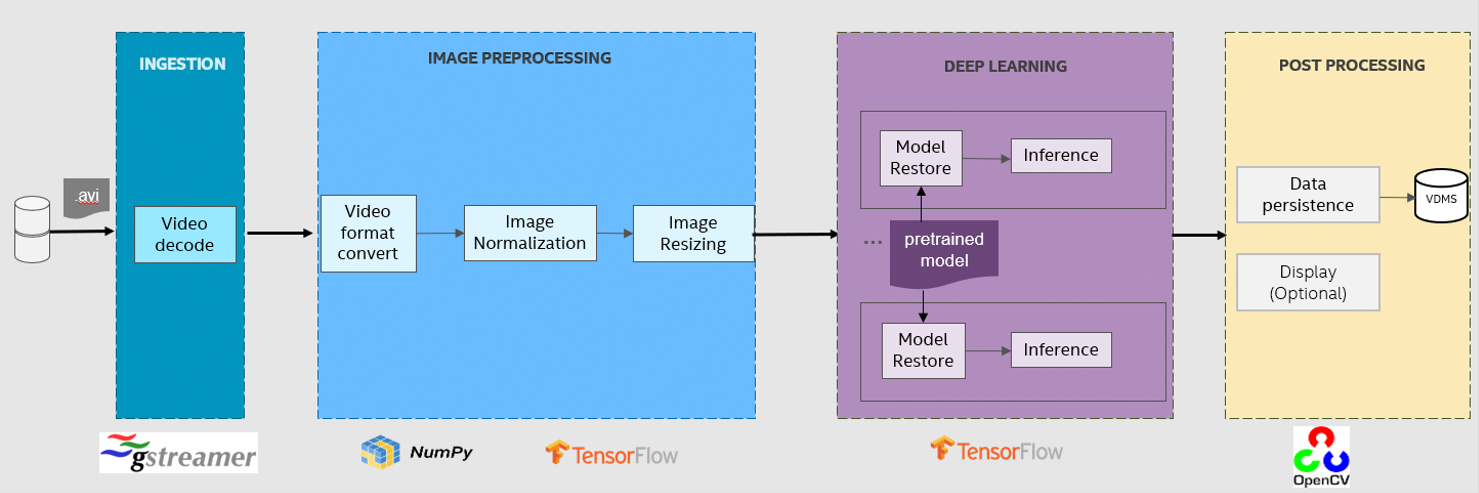
Figure 7. Video Streamer Application Pipeline.
Anomaly Detection
The objective of anomaly detection is to analyze images of parts being manufactured on an industrial production line, using deep neural network and probabilistic modeling to identify rare defects (Figure 8). As an out-of-distribution solution, a model of normality is learned over feature maps of the final few layers from normal data in an unsupervised manner. Deviations from the models are flagged as anomalies. Prior to learning distribution, the dimension of the feature space is reduced by using PCA to prevent matrix singularities and rank deficiencies from arising while estimating the parameters of the distribution.
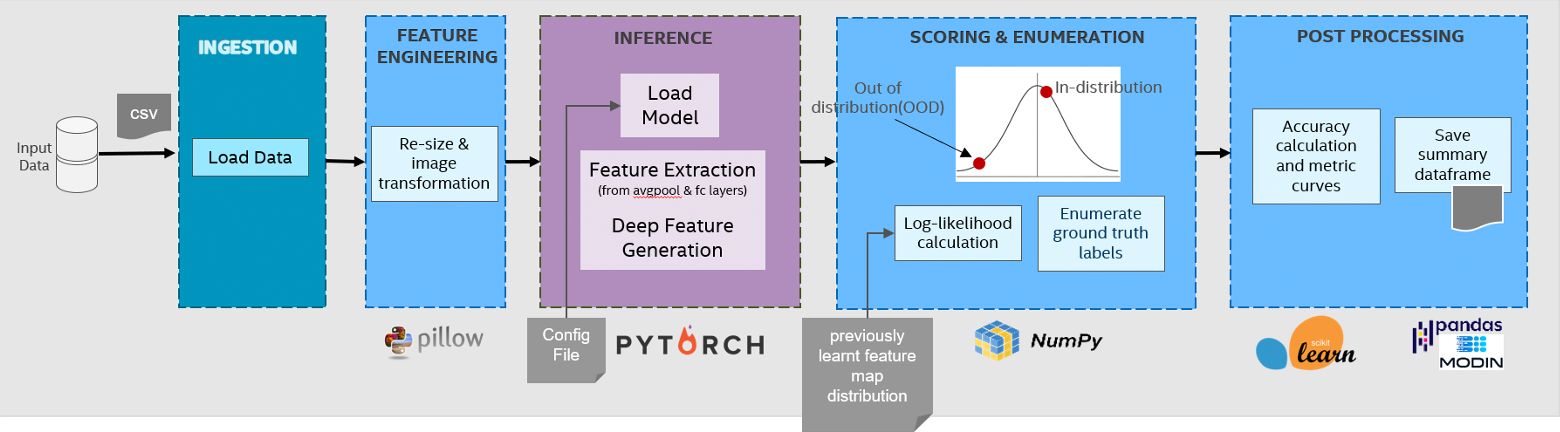
Figure 8. Anomaly detection pipeline.
Face Recognition
This E2E pipeline performs real-time face recognition by cascading two, out-of-the-box, pretrained models: SSD MobileNet and ResNet50v1.5 (Figure 9). The input from the camera, as compressed or uncompressed video, undergoes frame splitting and resizing. Each frame is then fed to the detection model (SSD MobileNet), which performs object detection. The NMS bounding boxes are then fed to the recognition model (ResNet50v1.5) to recognize the faces. The output frames with the facial recognitions can either be displayed or saved in databases.
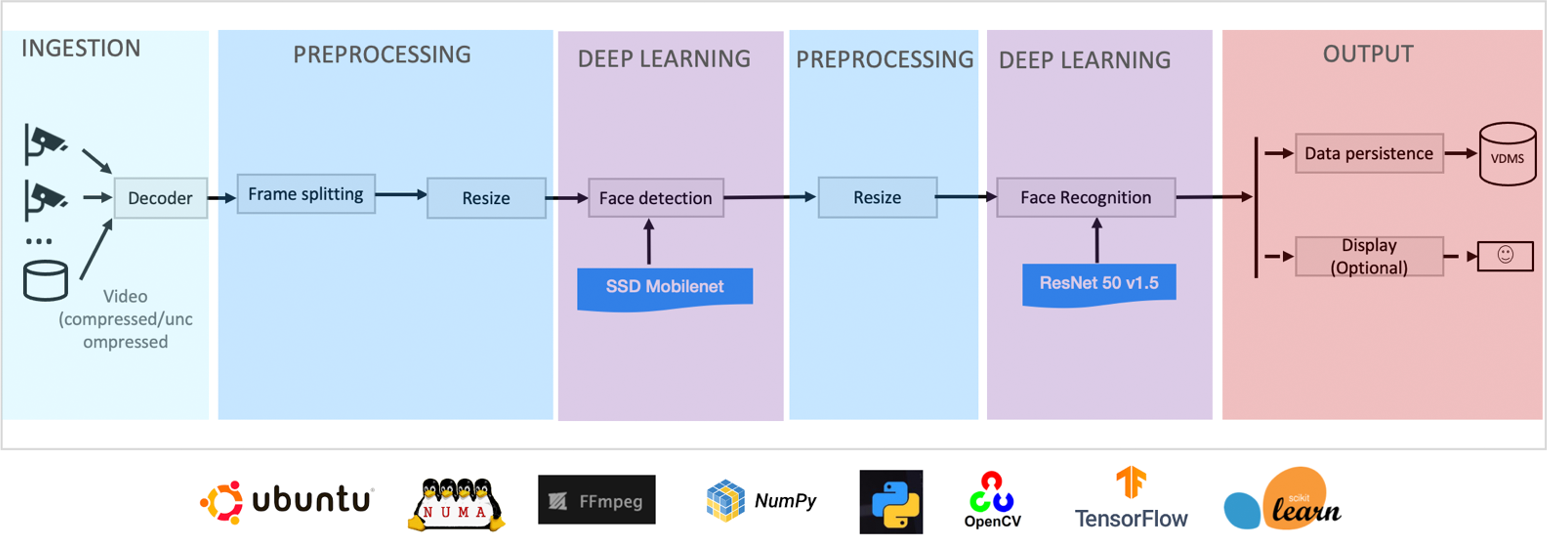
Figure 9. Face recognition pipeline.
How To Do “Efficient-AI”: E2E Optimization Strategies
E2E performance-efficient AI requires a coherent optimization strategy consisting of AI software acceleration, system-level tuning, hyperparameter and runtime parameter optimizations, and workflow scaling. All phases (data ingestion, data preprocessing, feature engineering, and model building) need to be holistically addressed to improve user productivity as well as workload performance efficiency (Figure 10).
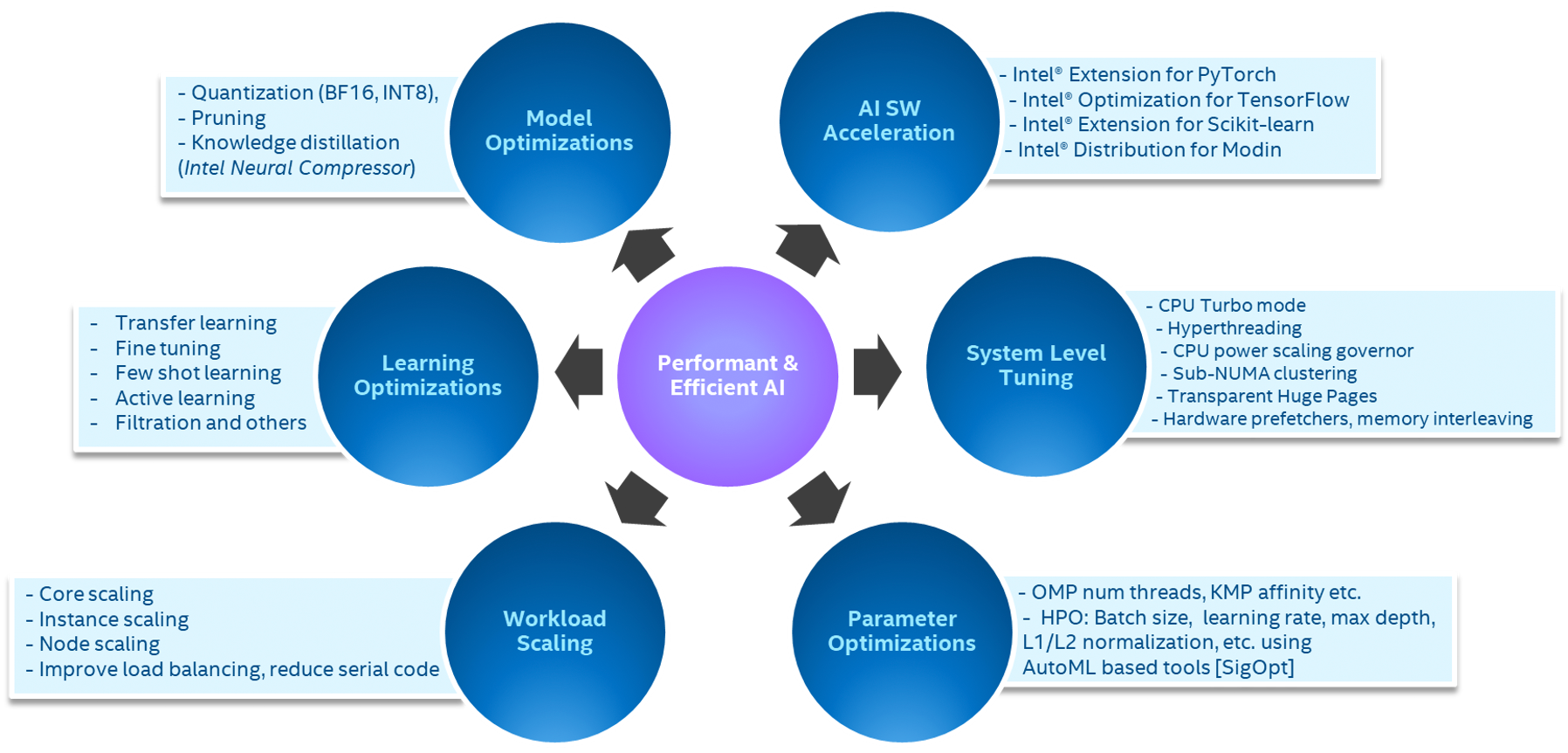
Figure 10. Efficient AI.
AI Software Acceleration
Intel Distribution of Modin is a multithreaded, parallel, and performant data frame library compatible with the pandas API. It performs lightweight, robust data frame and CSV operations, and it scales efficiently with the number of cores, unlike pandas, providing a significant speedup just by changing a couple of lines of code. Data frame operations across different phases speed up from 1.12x to 30x.
Intel Extension for Scikit-learn accelerates common estimators, transformers, and clustering algorithms in classical ML. Ridge regression training and inference in the Census workload is a DGEMM-based memorybound algorithm that takes advantage of Intel Extension for Scikit-learn’s vectorization, cache-friendly blocking, and multithreading to efficiently use multiple CPU cores. Intel-optimized XGBoost and CatBoost libraries provide efficient parallel tree boosting. The XGBoost kernels are optimized for cache efficiency, remote memory latency, and memory access patterns on Intel processors.
Intel® Extension for PyTorch4 improves PyTorch performance on Intel processors. With Intel Extension for PyTorch, the Anomaly Detection and DLSA pipelines take advantage of Intel DL Boost. Intel® Optimization for TensorFlow5 is powered by Intel® oneAPI Deep Neural Network Library (oneDNN), which includes convolution, normalization, activation, inner product, and other primitives vectorized using Intel® AVX- 512 instructions. The DIEN, face recognition, and video streamer applications use Intel Optimization for TensorFlow to enable scalable performance on Intel processors through vectorization and optimized graph operations (e.g., ops fusion, batch normalization).
Model Optimizations
Quantization facilitates conversion of high-precision data (32-bit floating point, FP32) to lower precision (8-bit integer, INT8), which enables critical operations such as convolution and matrix multiplication to be performed significantly faster with little to no loss in accuracy. Intel Neural Compressor automatically optimizes low-precision recipes for DL models and calibrates them to achieve optimal performance and memory usage with expected accuracy criteria. DLSA and video streamer applications achieved up to 4x speedup from INT8 quantization alone (Table 2).
Parameter Optimizations
The SigOpt model development platform makes it easy to track runs, visualize training, and scale hyperparameter optimization for any pipeline, while also tuning for objectives like maximum throughput at threshold accuracy and/or latency levels. With SigOpt’s multi-objective optimization, we can easily obtain insights on the best configurations of the AI pipeline, showing the optimal performance summary and analysis. In the case of PLAsTiCC, “accuracy” and “timing” metrics were optimized, while the model hyperparameters (like the number of parallel threads for XGBoost, number of trees, learning rate, max depth, L1/L2 normalization, etc.) were computed in order to achieve the objective6. In DLSA, the number of inference instances and batch size are tuned to achieve high E2E throughput.
Run-time options in TensorFlow also make a big performance impact. It is recommended to control the parallelism within an operation like matrix multiplication or reduction so as to schedule the tasks within a threadpool by setting intra_op_parallelism_threads equal to the number of available physical cores and, in contrast, running operations that are independent in the TensorFlow graph concurrently by setting inter_op_parallelism_threads equal to the number of sockets. Data layout, OpenMP, and NUMA controls are also available to tune the performance even further5.
Workload Scaling
Multi-instance execution allows parallel streams of the application to be executed on a single Intel® Xeon® Scalable server. The advantage is demonstrated during anomaly detection, where several cameras can be deployed to detect defects at different stages of the manufacturing pipeline; 10 such streams processing over the standard 30 FPS on a ResNet50 model can be serviced by a single 3rd Gen Intel Xeon Scalable processor. Similarly, E2E DIEN runs with one core/instance with 40 inference instances per socket, while DLSA and DL pipelines run four cores/instance to eight cores/instance with 10 inference streams to five inference streams per socket. This is a unique advantage of CPUs with their large memory capacity.
System-level tuning is available in the BIOS to improve efficiency. Tuning knobs controlling hyperthreading, CPU power scaling governors, NUMA optimizations, hardware prefetchers, and more can be explored to obtain best performance.
| Intel Distribution for Modin | Intel Extension for Scikit-learn | XGBoost | Intel Extension for PyTorch | Intel-optimized TensorFlow | INT8 quantization | |
|---|---|---|---|---|---|---|
| Census | 6x | 59x | - | - | - | - |
| PLAsTiCC | 30x | 8x | 1x | - | - | - |
| Predictive Analytics for Industrial IoT | 4.8x | 113x | - | - | - | - |
| Document Level Sentiment Analysis | - | - | - | 4.15x | - | 3.90x |
| E2E Deep Interest Evolution Network | 23.2x | - | - | - | 9.82x | - |
| Video Streamer | - | - | - | - | 1.36x | 3.64x |
| Anomaly Detection | 1.12x | 3.4x | - | 1.8x | - | - |
| Face Recognition | - | - | - | - | 1.7x | - |
Table 2. Performance improvement from software optimizations and quantization for E2E AI applications.
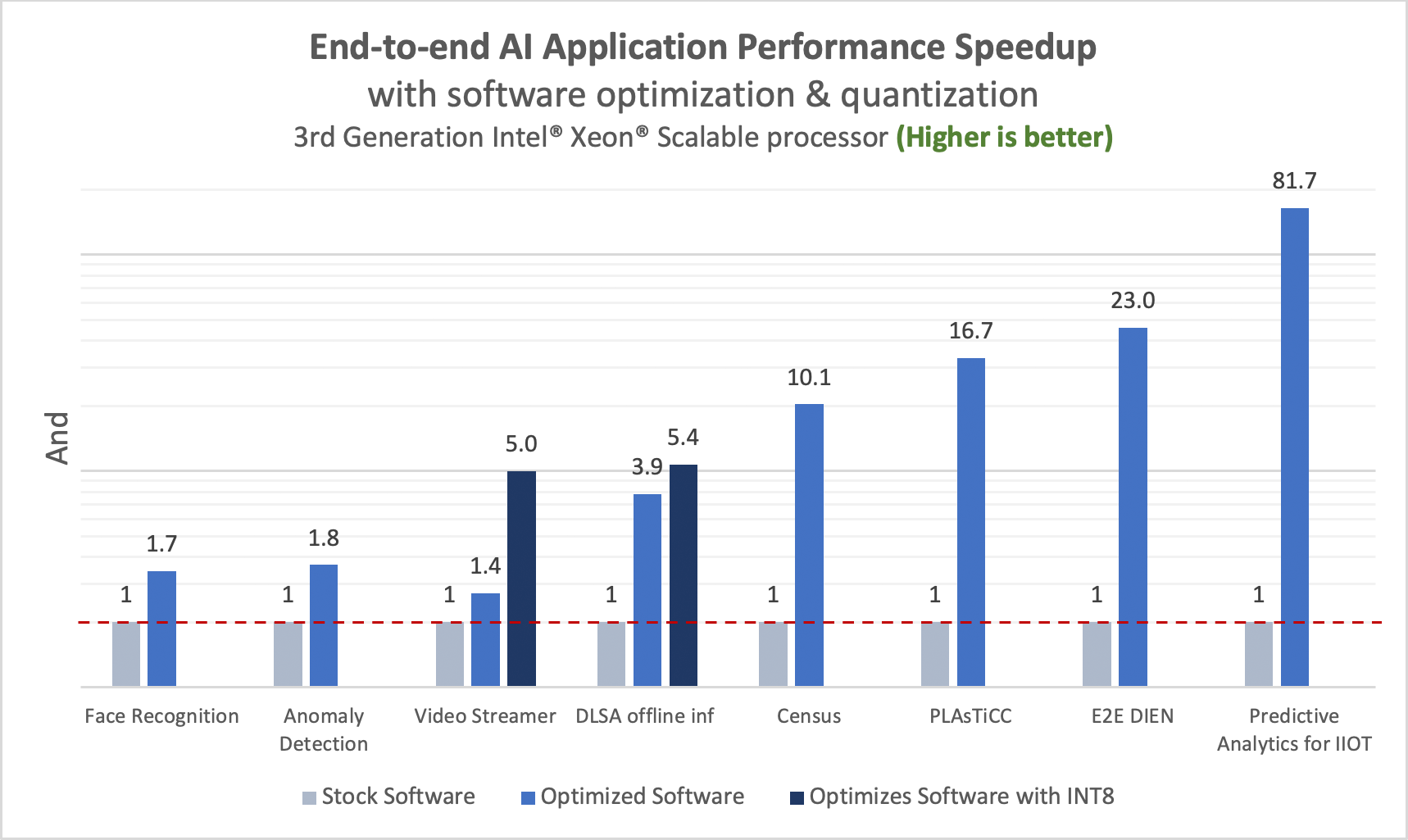
Figure 11. E2E AI application performance speedup.
Configuration: Performance measured on a single-node, dual-socket 3rd Generation Intel Xeon Scalable 8380 processor (except DIEN and DLSA), 40 cores per socket. DIEN and DLSA were measured on 3rd Generation Intel Xeon Scalable 6348 processors, turbo mode enabled, hyperthreading disabled, BIOS: SE5C620.86B.01.01.0003.2104260124, kernel: 5.13.0-28-generic, OS: Ubuntu 21.10, 512GB memory (16 slots/32GB DIMMs/3200MHz), Intel 480GB SSD OS Drive.
Anomaly Detection: Python 3.7.11, torch 1.11.0, torchvision 0.11.3, PyTorch 1.10, numpy 1.22.1, pandas 1.3.5, scikit-learn-intelex 2021.4.0; Face Recognition: Python 3.7.9, TensorFlow 2.8.0, numpy 1.22.2, opencv-python 4.5.3.56, ffmpy 0.3.0; Video Streamer: Python 3.8.12, TensorFlow 2.8.0, opencv-python 4.5.2.54, pillow 8.3.1, gstreamer1.0, vdms 0.0.16; DLSA offline Inf: Python 3.7.11, PyTorch 1.10, HuggingFace Transformer:4.6.1; E2E DIEN: Python 3.8.10, Modin 0.12.0, TensorFlow 2.8.0, numpy 1.22.2; Census: Python 3.9.7, Modin 0.12.0, scikit-learnintelex 2021.4.0; PLAsTiCC: Python 3.9.7, Modin 0.12.0, scikit-learn-intelex 2021.4.0, XGBoost 1.5.0; Predictive Analytics for Industrial IoT:
Python 3.9.7, Modin 0.12.0, scikit-learn-intelex 2021.4.0.
In conclusion, as a result of cumulative optimization strategies across software, system, hardware, model-building, and hyperparameters, we achieve 1.8x to 81.7x speedup in E2E performance on Intel Xeon processors.
References
- Census workload oneAPI sample code, Intel® oneAPI AI Analytics Toolkit: https://github.com/oneapi-src/oneAPI-samples/tree/master/AI-and-Analytics/End-to-end-Workloads/Census
- Intel Distribution of Modin: https://www.intel.com/content/www/us/en/developer/tools/oneapi/distribution-of-modin.html
- Getting Started with Intel Extension for Scikit-learn: /content/www/us/en/developer/articles/guide/intel-extension-for-scikit-learn-getting-started.html
- Intel Extension for PyTorch: https://www.intel.com/content/www/us/en/developer/articles/guide/gettingstarted-with-intel-optimization-of-pytorch.html
- Maximize TensorFlow Performance on CPU: https://www.intel.com/content/www/us/en/developer/articles/technical/maximize-tensorflow-performance-on-cpu-considerations-and-recommendations-forinference.html
- Optimizing Artificial Intelligence Applications: Better AI Performance with Hyperparameter Tuning and Optimized Software: https://medium.com/intel-analytics-software/optimizing-artificial-intelligenceapplications-1bc22b5d707b
Five Outstanding Additions Found in SYCL 2020
Read
Winning the NeurIPS BillionScale Approximate Nearest Neighbor Search Challenge
Read
Accelerating the 2D Fourier Correlation Algorithm with ArrayFire and oneAPI
Read
The Maxloc Reduction in oneAPI
Read
More Productive and Performant C++ Programming with oneDPL
Read
Optimizing Artificial Intelligence Applications
Read