Data scientists are always looking for ways to boost their AI application performance. Using optimized machine learning software instead of stock packages is an easy way to do this. Tuning model hyperparameters using an AutoML-based platform like SigOpt is another. I will demonstrate the performance possibilities using the PLAsTiCC Classification Challenge from Kaggle.
PLAsTiCC is an open data challenge to classify objects in the sky that vary in brightness. It uses simulated astronomical time-series data in preparation for observations that will come from the Large Synoptic Survey Telescope being set up in northern Chile. The challenge is to determine the probability that each object belongs to one of 14 classes of astronomical filters, scaling from a small training set (1.4 million rows) to a very large test set (189 million rows).
The code can be divided into three distinct phases:
- Readcsv: Loading the CSV-format training and testing data and their corresponding metadata into pandas dataframes.
- ETL: Manipulating, transforming, and processing the dataframes for input to the training algorithm.
- ML: Using the histogram tree method from the XGBoost library to train the classification model. The model is cross-validated, and the trained model is used to classify objects in the massive test set.
The chart below shows stock and optimized software that is used for each of these phases plus SigOpt for hyperparameter tuning:

The Intel® Distribution for Modin* is used to improve Readcsv and ETL performance. This parallel and distributed dataframe library uses the pandas API. It allows you to significantly improve the performance of dataframe operations just by changing a single line of code. To improve PLAsTiCC ML performance, the XGBoost Optimized for Intel® Architecture package is upstreamed to the main branch. This can be obtained by simply installing the latest version of XGBoost. (See Distributed XGBoost with Modin on Ray.)
The bar chart below shows the speed-ups obtained using the optimized software stack (shown in blue) over the stock software (shown in orange) in each PLAsTiCC phase. A massive 18x end-to-end speedup is achieved by using the optimized software. Intel Distribution for Modin performs lightweight, robust dataframe and Readcsv operations and scales efficiently with the number of cores, unlike pandas. The XGBoost kernels are optimized for cache efficiency, remote memory latency, memory access patterns on Intel® architectures, and optimally uses its higher processor frequencies, cache size, and cache bandwidth.
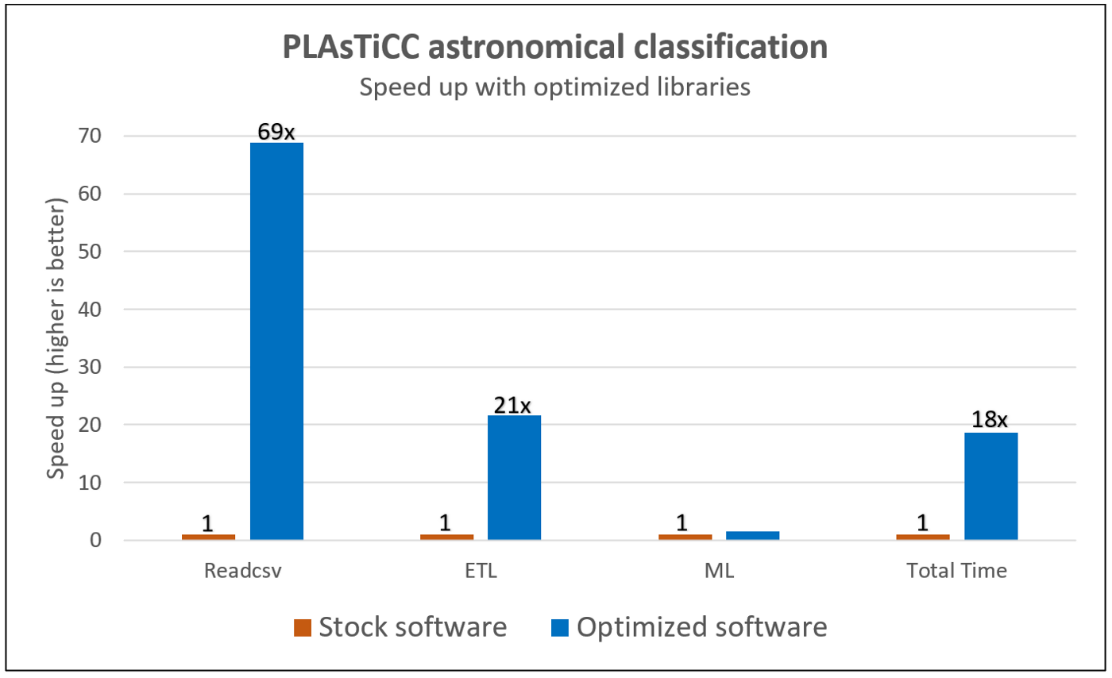
We can improve the end-to-end workload performance even further by tuning the hyperparameters in the machine learning model. SigOpt is a model-development platform that provides an easy way to do this. It tracks training experiments, provides tools to visualize the training, and scales hyperparameter optimization for any type of model.
SigOpt finds the best parameter values for the model and provides the global optimum for the defined metric within the optimization loop. In the case of PLAsTiCC, accuracy and timing are the metrics to be optimized, while the model hyperparameters (like the number of parallel threads for XGBoost, number of trees, learning rate, max depth, L1/L2 normalization, etc.) are the parameters that need to be computed in order to achieve the objective. A minimum number of observations need to be run to find the global maximum or minimum of the objective function, and convergence mostly occurs when the number of experiments is set to 10–20 times the number of parameters in the experiment.
This following table shows the default model parameters and the tuned parameters as computed by the SigOpt autoML experiments:
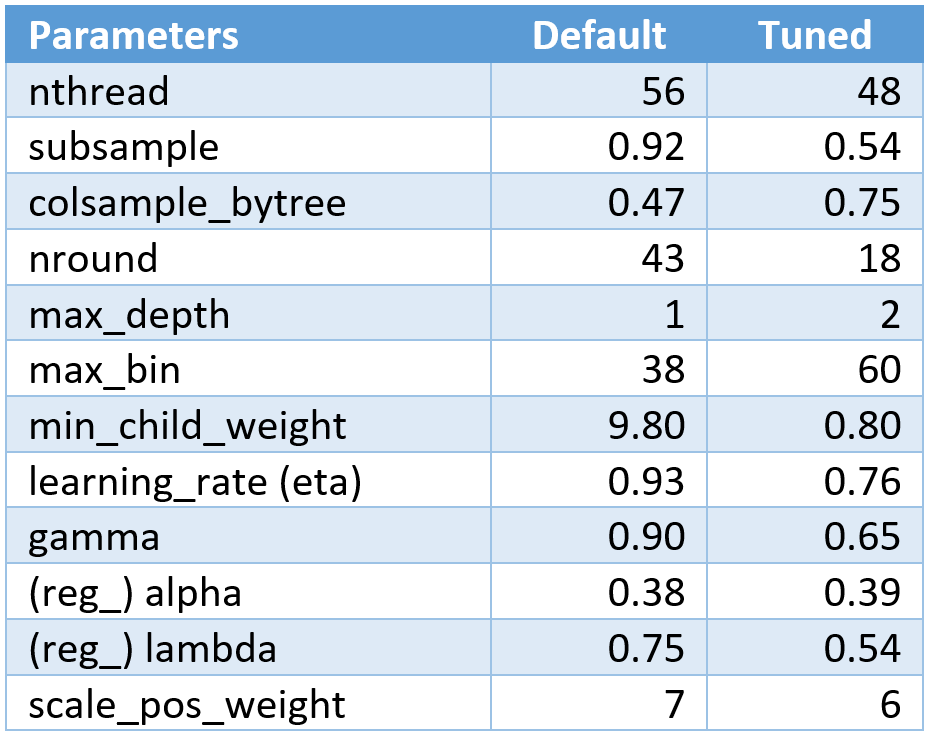
It’s easy to see that manually tuning and running through all these permutations would be almost impossible, whereas SigOpt can do it in a few hours. The log loss and validation loss for the model does not increase, which means that these improvements were achieved without compromising or affecting model accuracy.
The previous chart is replotted below to show the additional 5.4x ML performance improvement due to SigOpt hyperparameter tuning, which gives a 1.5x overall improvement.
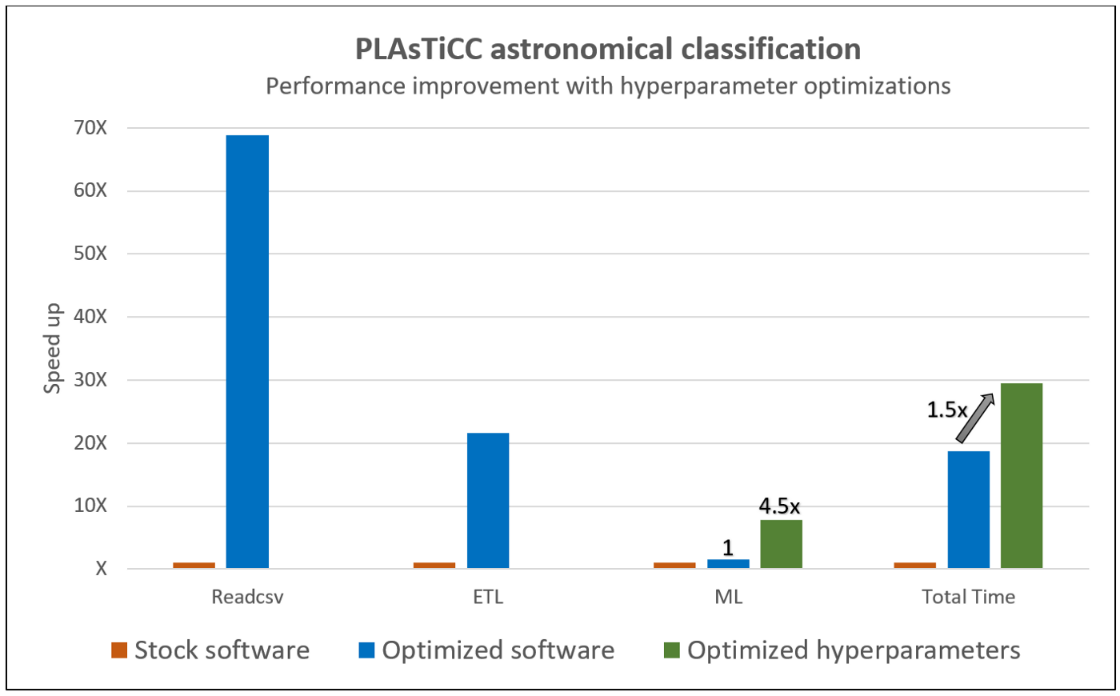
These steps performed over a typical end-to-end pipeline show the significant performance improvement that can be achieved on an AI workload using a variety of Intel-optimized software packages, libraries, and optimization tools. (See Performance Optimizations for End-to-End AI Pipelines.)
Hardware and Software Configurations
Hardware: 2 Intel® Xeon® Platinum 8280L processors (28 cores), OS: Ubuntu 20.04.1 LTS Mitigated, 384 GB RAM (384 GB RAM: 12 x 32 GB 2933 MHz), kernel: 5.4.0–65-generic, microcode: 0x4003003, CPU governor: performance. Software: scikit-learn 0.24.1, pandas 1.2.2, XGBoost 1.3.3, Python 3.9.7, scikitlearn-intelex 2021.2, modin 0.8.3, omniscidbe v5.4.1.
Five Outstanding Additions Found in SYCL 2020
Read
Winning the NeurIPS BillionScale Approximate Nearest Neighbor Search Challenge
Read
Accelerating the 2D Fourier Correlation Algorithm with ArrayFire and oneAPI
Read
The Maxloc Reduction in oneAPI
Read
More Productive and Performant C++ Programming with oneDPL
Read
Optimizing End-to-End Artificial Intelligence Pipelines
Read