Finding the index of a target element (minimum, maximum, or their absolute values) is used in many applications. In this article, I use the Intel® Advanced Vector Extensions 512 (Intel AVX-512) compiler intrinsics to accelerate this operation (henceforth referred to as “Maxloc”) and benchmark the performance on Intel® Xeon® Scalable processors. Intel AVX-512 provides a broad set of instructions that facilitates single instruction, multiple data (SIMD) execution. It is available on all Intel Xeon Scalable processors and uses 512-bit vector registers to operate on wider execution units for maximum efficiency. By careful application of Intel AVX-512, the number of instructions and comparisons needed to identify the index of the target element is minimized, resulting in a significant speed-up.
Maxloc is a common search operation performed on arrays (e.g., the NumPy argmax function, TensorFlow GlobalMaxPool1D, and oneMKL amax functions). I will be using the Intel AVX-512 SIMD API (popularly known as vector intrinsics) provided by the Intel® C/C++ Compiler Classic. (Readers are also referred to my previous article, Optimization of Scan Operations Using Explicit Vectorization.) The following sections will illustrate the implementation of Intel AVX-512 Maxloc using Intel AVX-512 vector intrinsics.
Baseline Implementation
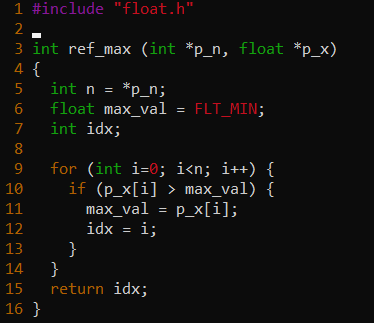
Code listing 1: Maxloc baseline implementation
Code listing 1 shows a baseline implementation consisting of a single pass, scalar version of Maxloc. As can be seen from the code, a vector containing n elements requires n comparison operations. We visit the input vector only once, and store the index location corresponding to the maximum value. The instructions generated in the baseline implementation are shown in Table 2 and will be discussed in the performance evaluation section.
AVX-512 SIMD Implementation
Table 1 lists the Intel AVX-512 SIMD instructions used in my approach. Figure 1 shows a visual representation of the operations performed by vmaxpd, vcmpps, and vblendmps instructions for a sample register state.
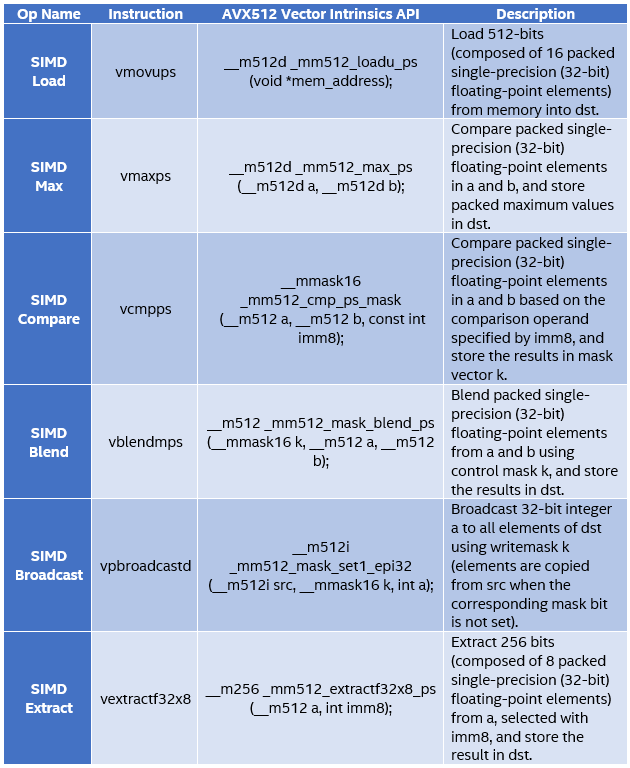
Table 1. AVX-512 SIMD instructions used in Maxloc
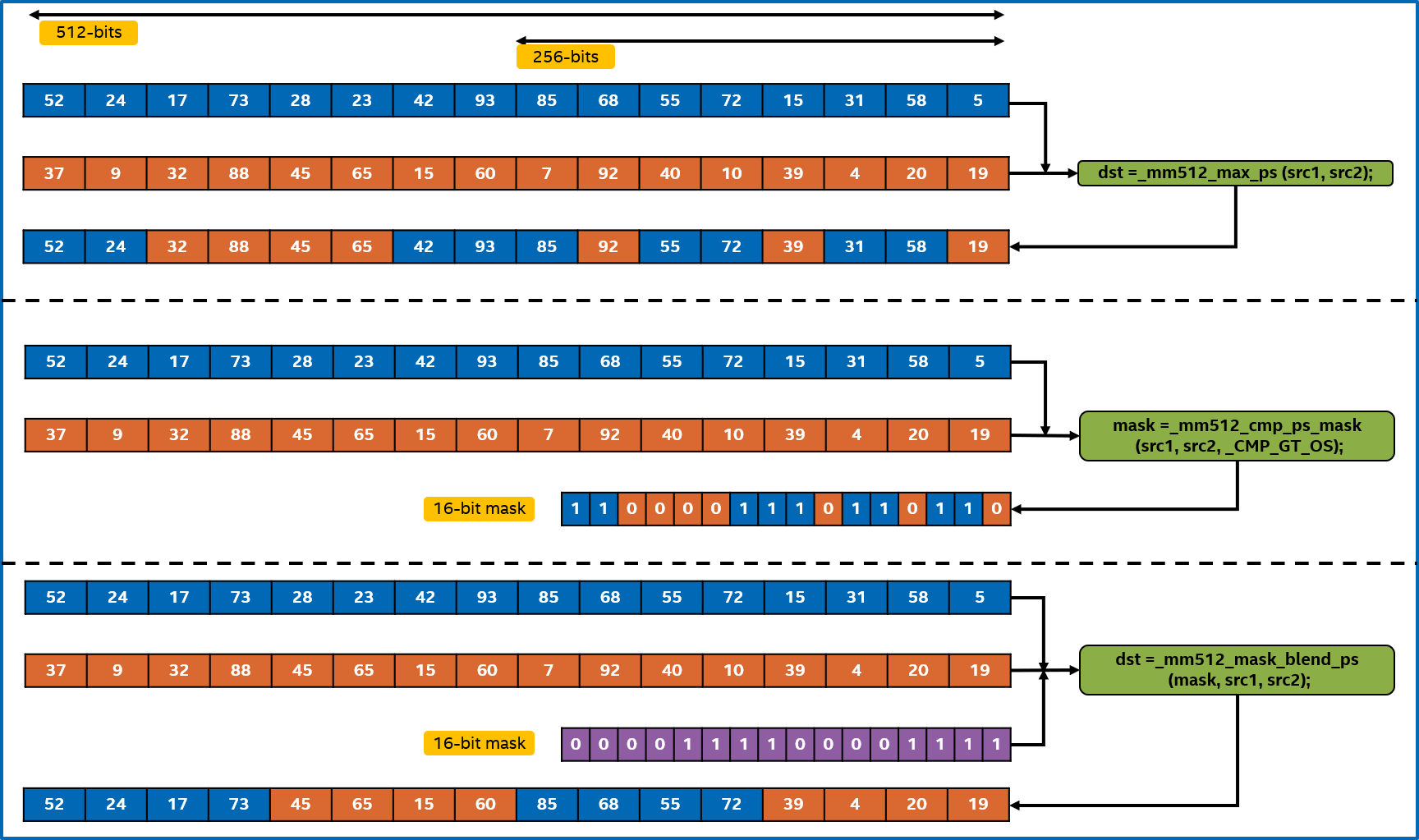
Figure 1. Visual representation of operations performed by AVX-512 vmaxps, vcmpps, and vblendmps
For Maxloc, I unroll the loop and apply a series of vmaxpd instructions to obtain a sequence of 16 FP32 (32-bit floating-point) maximum values, represented as 512-bit Intel AVX-512 registers. In addition to that, I keep track of the indices of the maximum values as the input data is processed. This is achieved by doing an additional comparison operation (between the current and previous iteration maximum values) and using the results to blend the latest maximum values and their corresponding unrolled block ID. The key steps of the algorithm are as follows:
- Main block:
- Each iteration loads 64 input elements into four Intel AVX-512 vector registers and does pairwise comparison to identify the maximum value in each quadruplet to form a current max register representing the max values in offsets of 16.
- The previously populated max values are compared to form a 16-bit mask (with each bit representing a FP32 element in an Intel AVX-512 register). The mask bit is set if the quadruplet maximum value found in the current iteration is greater than the previous quadruplet max value.
- Once this mask is calculated, it is used to blend the values from both the current and previous max Intel AVX-512 registers to form the new quadruplet of max values in the register for use in future iterations.
- To track the indices, the same mask is reused to set the current loop index (unrolled block ID) to a register of indices representing the block at which the corresponding maximum value is located.
- The previous steps form the main loop and are repeated for all input elements to find the 16 max values among quadruplets (at indices {0,16,32,48}, {1,17,33,49}, ...) and their corresponding loop/ block IDs (0, 64, 128, 192, ...).
- Reduction and target block: After the main loop, a single reduction on an Intel AVX-512 register finds the maximum among the 16 values from the main block. The maximum value found from the reduction step is used to identify (in the form of a 16-bit mask) where among the 16 locations in the Intel AVX-512 register the maximum value is encountered. Each bit of the 16-bit result mask represents a selection of int32 elements into the Intel AVX-512 block-indices register. This int32 value represents the iteration ID where the maximum value is encountered. Now, depending on whether the maximum value is encountered at one or more locations, the following two methods identify the first block containing the maximum value.
- Single instance: In this case, the maximum value is found only once in the dataset, which implies a single set bit in the 16b result mask. This identifies the corresponding int32 value from the Intel AVX- 512 block-indices register. For example, when the mask is 0000 0000 1000 0000, the value at the seventh int32 element in the Intel AVX-512 indices register represents the block ID where the maximum value is found.
Offset into block: One of the unique features of this implementation is that we can use the inherent pattern of the vmaxps instruction to identify the target index without reading the whole block (size of N_UNROLL). Let’s denote Blkid as the int32 value from the Intel AVX-512 indices register corresponding to the 1-bit set in the 16-bit result mask, Mx as the bit location (0 to 15) where 1-bit is set in in 16-bit result mask. From Figure 2, we observe that vmaxps compares values that are at offsets of 16 elements. Hence, we can conclude that index of maximum value has occurred at one of the following four locations: (Blkid + Mx), (Blkid + Mx + 16), (Blkid + Mx + 32), (Blkid + Mx + 48) when N_UNROLL is 64.
- Duplicates: If the number of 1-bits in the result mask is greater than one, then the maximum value is encountered at more than one location in the dataset. So, we find the minimum of all the int32 values corresponding to the 1-bits set in the mask from the Intel AVX-512 indices register. We again compare the minimum index against the Intel AVX-512 indices register to know if the maximum value is encountered more than once within an unrolled block. If true, we read the whole block in chunks of 16 elements to identify the first index where the maximum value is encountered. Otherwise, we use the approach described in Step 3.
Figures 2 and 3 show the visual representation of main block computations and reduction sequence on Intel AVX-512 registers. Code listing 2 shows the implementation of this algorithm.
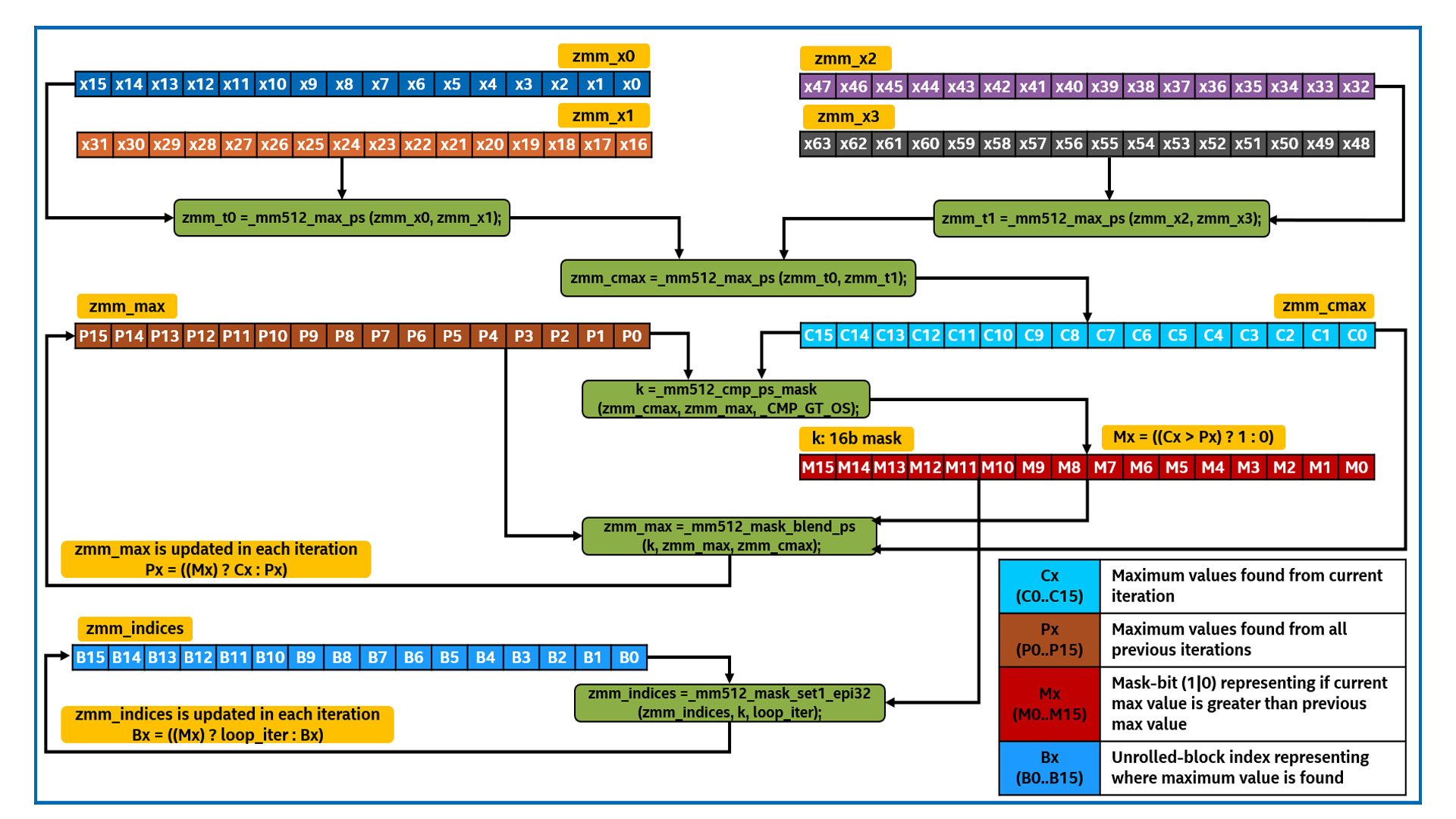
Figure 2. Visual representation of the main block of AVX512 + Index Tracking implementation of Maxloc
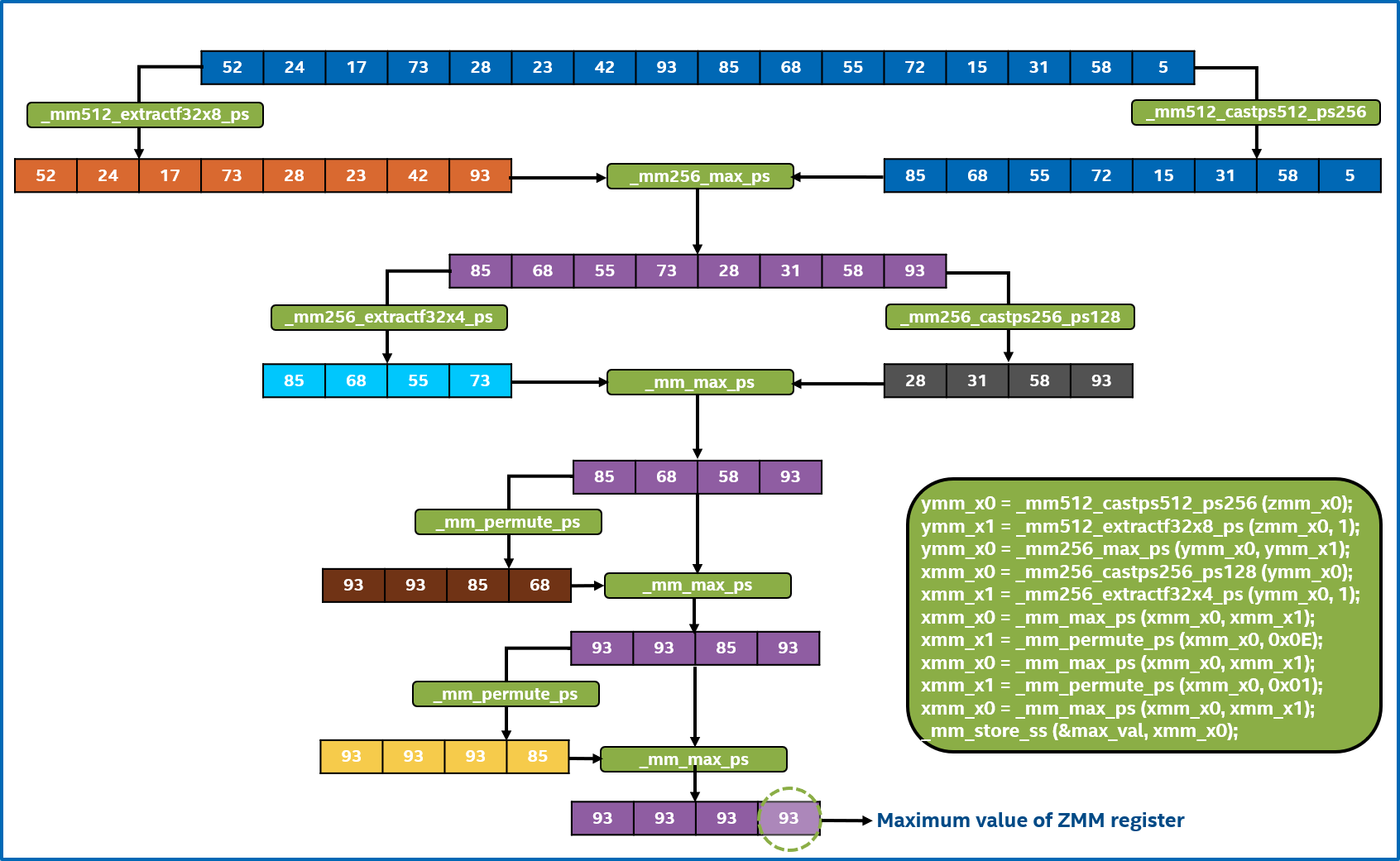
Figure 3. Instruction sequence to reduce AVX-512/ZMM register to find the maximum value
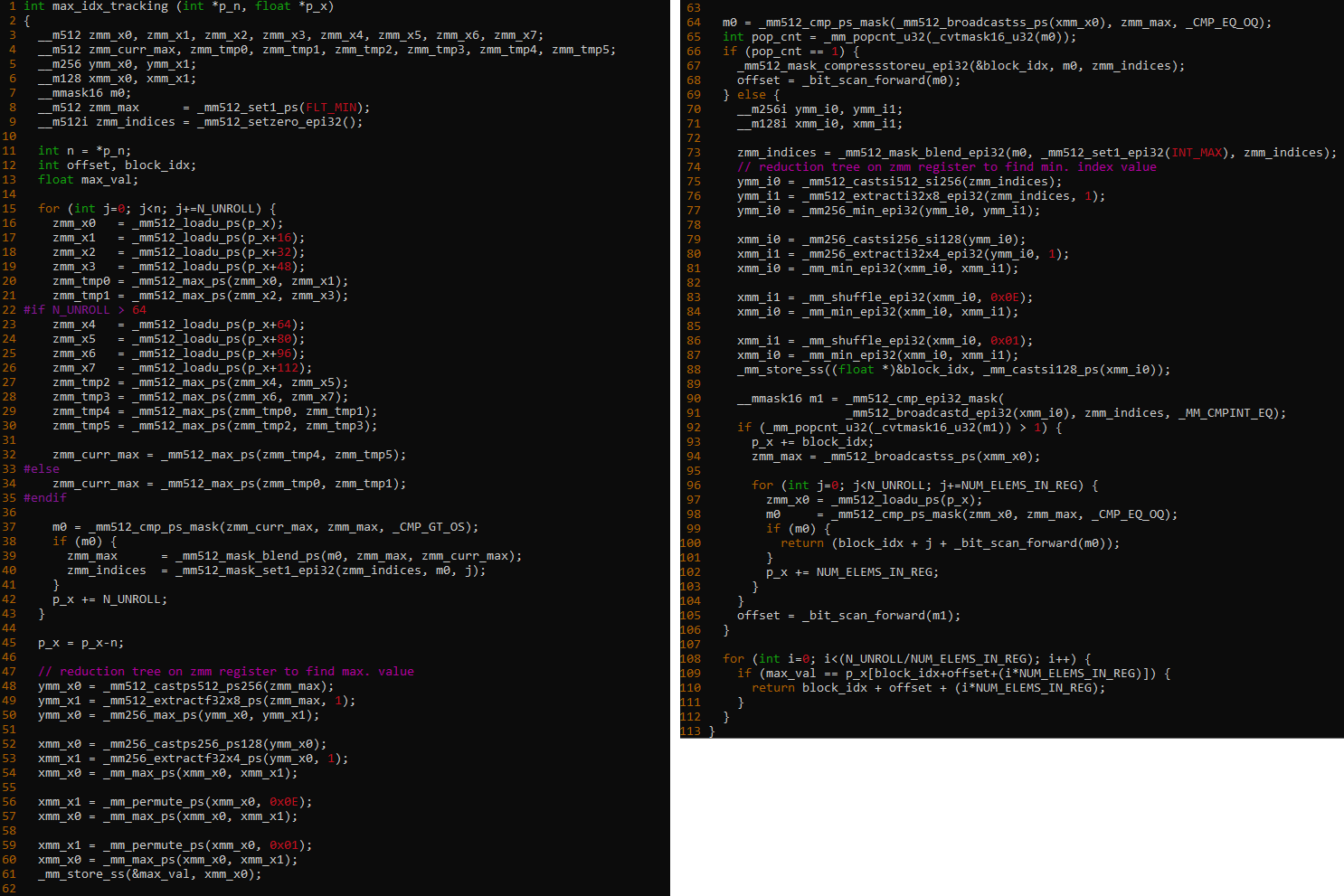
Code listing 2. Implementation of Maxloc using AVX-512
Performance Evaluation
The Intel AVX-512 Maxloc implementation is compared to the baseline implementation shown in Code listing 1 using the following experimental protocol:
- GCC (8.4.1) and Clang (11.0.0) are used with the -O3 -march=icelake-server -mprefer-vector-width=512 flags to compile the baseline implementation. ICC (v19.1.3.304) is used to compile the AVX-512 implementation.
- The same input data is used in all benchmarks. The input data consists of values in ascending order (i.e., the maximum value is in the last index location). No performance differences were observed when random values were used.
- The input size is varied from 1,024 to 4,194,304 elements (16 MB with FP32 elements). This allows us to evaluate performance when the data fits into different cache hierarchies (L1D, L2, and L3).
- An Intel Xeon Platinum 8368 processor (3rd Gen Intel Xeon Scalable processor) is used for benchmarking. It has 38 cores per socket, 48 KB L1D cache, 1280 KB L2, and 57 MB L3 per socket.
- Performance is measured for one thread pinned to a single core. The average time elapsed for 100 iterations of each problem size is reported. Memory is allocated on 64B aligned boundaries.
- In the AVX-512 implementation, the main block is explicitly unrolled by 128 elements.
Table 2 shows the instruction sequence generated by GCC, Clang, and explicit Intel AVX-512 implementation compiled with ICC (main block only due to space constraints). Figure 4 shows the performance of Maxloc with GCC, Clang, and explicit Intel AVX-512 methods. Figure 5 shows the speed- up of the AVX-512 implementation over GCC. From the performance charts, we can make the following observations:
- In the baseline implementation, performance is determined by the automatic vectorization ability of the compilers (GCC, Clang). As observed in the disassembly of object code generated in Table 2, neither GCC nor Clang is able to vectorize the computations, instead relying on scalar instructions (vmovss, vucomiss, vmaxss, cmov) that operate on a single FP32 element; hence, the “ss” suffix (stands for “single, single-precision”) in the instruction name. Interestingly, even though Clang unrolls the loop by eight elements, it still processes the eight elements in serial order by emitting the same single, scalar instructions as GCC.
- In contrast, the Intel AVX-512 implementation works on 16 FP32 elements stored in 512-bit wide ZMM registers using Intel AVX-512 instructions (as seen in the third column of Table 2). The Intel AVX-512 instructions map to the intrinsics in Code listing 2.
- The Intel AVX-512 implementation of Maxloc delivers superior performance (Figure 5). The average speed-up for sizes that fit in L1, L2, and L3 caches are 18x, 40x, and 13x, respectively. As we hit L3 cache, the latency to load data into registers increases, so performance gains from Intel AVX-512 vectorization diminishes. For GCC and Clang, the lack of SIMD is reflected in the poor performance for all the problem sizes across caches. Even though Clang does unroll by eight elements, its performance is identical to GCC.

Table 2. Disassembly of Maxloc with GCC, Clang, and ICC
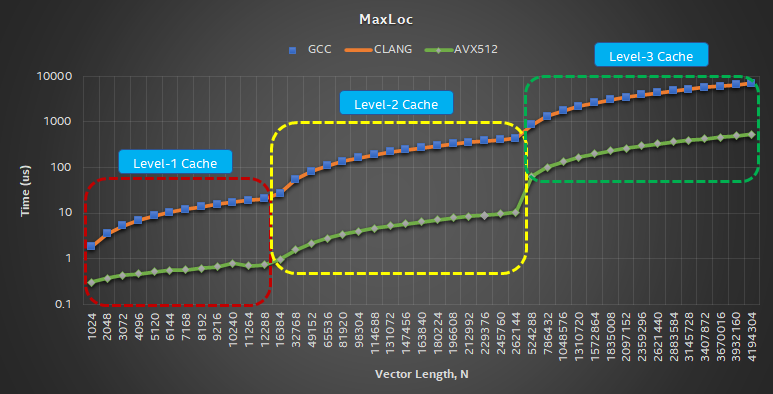
Figure 4. Performance of Maxloc with GCC, Clang, and ICC with explicit AVX-512 vectorization
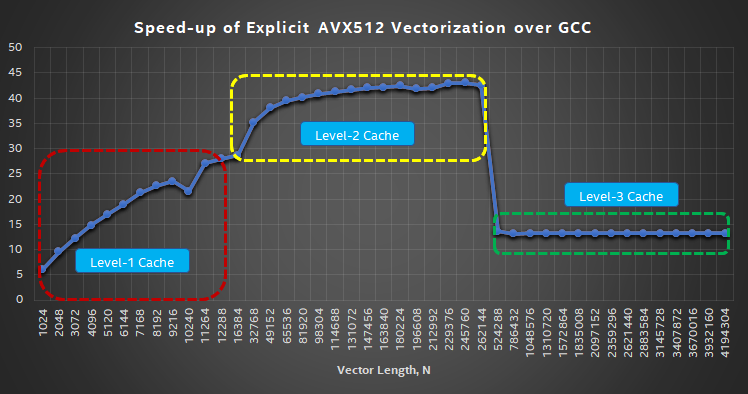
Figure 5. Speedup of explicit AVX-512 vectorization over GCC
Conclusion
These results demonstrate the performance advantage of Intel AVX-512 instructions when applied to the Maxloc operation. Explicit AVX-512 vectorization delivers superior performance to GCC and Clang. I hope this demonstration will motivate you to explore Intel AVX-512 opportunities in your compute- intensive code.
Read
Intel® oneAPI AI Analytics Toolkit
Accelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python* libraries.