Linear Regression Has Never Been Faster
Victoriya Fedotova, machine learning engineer, Intel Corporation
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
If you have ever used Python* and scikit-learn* to build machine-learning models from large datasets, you would have also wanted these computations to become faster. This article shows that altering a single line of code could accelerate your machine-learning computations, and that getting faster results does not require specialized hardware.
In this article, Victoriya Fedotova explains how to train ridge regression models using a version of scikit-learn that is optimized for Intel® CPUs, and then compares the performance and accuracy of these models trained with the vanilla scikit-learn library. This article continues the series on accelerated machine learning algorithms.
- Fast Gradient-Boosting Tree Inference for Intel® Xeon® Processors
- K-means Acceleration with 2nd Generation Intel® Xeon® Scalable Processors
A Practical Example of Linear Regression
Linear regression, a special case of ridge regression, has many real-world applications. For comparisons, use the well-known House Sales in King County, USA dataset from Kaggle*. This dataset is used to predict house prices based on one year of sales data from King County.
This dataset has 21,613 rows and 21 columns. Each row represents a house that was sold in King County between May 2014 and May 2015. The first column contains a unique identifier for the sale, the second column contains the date the house was sold, and the third column contains the sale price, which is also the target variable. Columns 4 to 21 contain various numerical characteristics of the house, such as the number of bedrooms, square footage, the year when the house was built, and zip code. This article shows how to build a ridge regression model that predicts the price of the house based on the data in columns 4 to 21.
In theory, the coefficients of the linear regression model should have the lowest residual sum of squares (RSS). In practice, the model with the lowest RSS is not always the best. Linear regression can produce inaccurate models if input data suffers from multicollinearity. Ridge regression can give more reliable estimates in this case.
Solve a Regression Problem with scikit-learn*
Let's build a model with sklearn.linear_model.Ridge. The following program trains a ridge regression model on 80 percent of the rows from the House Sales dataset, and then uses the other 20 percent to test the model’s accuracy.

The resulting R2 equals 0.69, which means that the model describes 69 percent of variance in the data. See the Appendix for details on the quality of the trained models.
Intel®-Optimized scikit-learn
Even though ridge regression is fast in terms of training and prediction time, you need to perform multiple training experiments to tune the hyperparameters. You might also want to experiment with feature selection (that is, evaluate the model on various subsets of features) to get better prediction accuracy. The performance of linear model training is critical because one round of training can take several minutes on large datasets. This can quickly add up if your task requires multiple rounds of training.
Intel®-optimized scikit-learn is made available through Intel® oneAPI AI Analytics Toolkit that provides optimized Python libraries and frameworks to accelerate end-to-end data science and machine-learning pipelines on Intel® architectures. The Intel® Distribution for Python* component of the toolkit includes scikit-learn and has the same set of algorithms and APIs as the Continuum or Stock scikit-learn. Therefore, no code changes are required to get a performance boost for machine learning algorithms.
The toolkit also provides daal4py, a Python interface to the Intel® oneAPI Data Analytics Library, through which you can improve the scikit-learn performance even further. Use the configurable machine-learning kernels in daal4py, some of which support streaming input data and can simply be scaled out to clusters of workstations.
Select and download the Intel oneAPI AI Analytics toolkit. Choose from several distribution packages, including YUM, APT, and conda*, and follow the provided installation instructions.
How to Configure scikit-learn with daal4py
Intel-optimized scikit-learn is ready for use after you install the Intel oneAPI AI Analytics toolkit and run the postinstallation script.
Dynamic patching of scikit-learn is required to use daal4py as the underlying solver. You can enable patching without modifying your application by loading the daal4py module before your application.
python -m daal4py my_app.py
Alternatively, you can patch sklearn within your application.
import daal4py.sklearn
daal4py.sklearn.patch_sklearn()
To undo the patch, run:
daal4py.sklearn.unpatch_sklearn()
Applying the patch impacts the following scikit-learn algorithms:
- sklearn.linear_model.LinearRegression
- sklearn.linear_model.Ridge (solver=’auto’)
- sklearn.linear_model.LogisticRegression and
sklearn.linear_model.LogisticRegressionCV (solver in [‘lbfgs’, ‘newton-cg’]) - sklearn.decomposition.PCA (svd_solver=’full’ and introduces svd_solver=’daal’)
- sklearn.cluster.KMeans (algo=’full’)
- sklearn.metric.pairwise_distance with metric=’cosine’ or metric=’correlation’
- sklearn.svm.SVC
This list may grow in future releases of the Intel oneAPI AI Analytics toolkit.
Performance Comparison
To compare performance of the vanilla scikit-learn and Intel-optimized scikit-learn, we used the King County dataset and six artificially generated datasets with varying numbers of samples and features. The latter were generated using the scikit-learn make_regression function.

Figure 1 shows the wall-clock time spent on training a ridge regression model with two different configurations:
- Scikit-learn version 0.22 installed from the default set of conda channels
- Scikit-learn version 0.21.3 from Intel Distribution for Python optimized with daal4py
Amazon states that “C5 instances offer the lowest price per vCPU in the Amazon EC2 family and are ideal for running advanced compute-intensive workloads.” The c5.metal instance has the most CPU cores and the latest CPUs among all C5 instances.
To enable Intel optimizations in scikit-learn, we used the -m daal4py command-line option. For performance measurements, use the Amazon Elastic Compute Cloud (Amazon EC2)*. Choose the instance that gives the best performance:
CPU: c5.metal (2nd generation Intel Xeon Scalable processors, two sockets, 24 cores per socket)
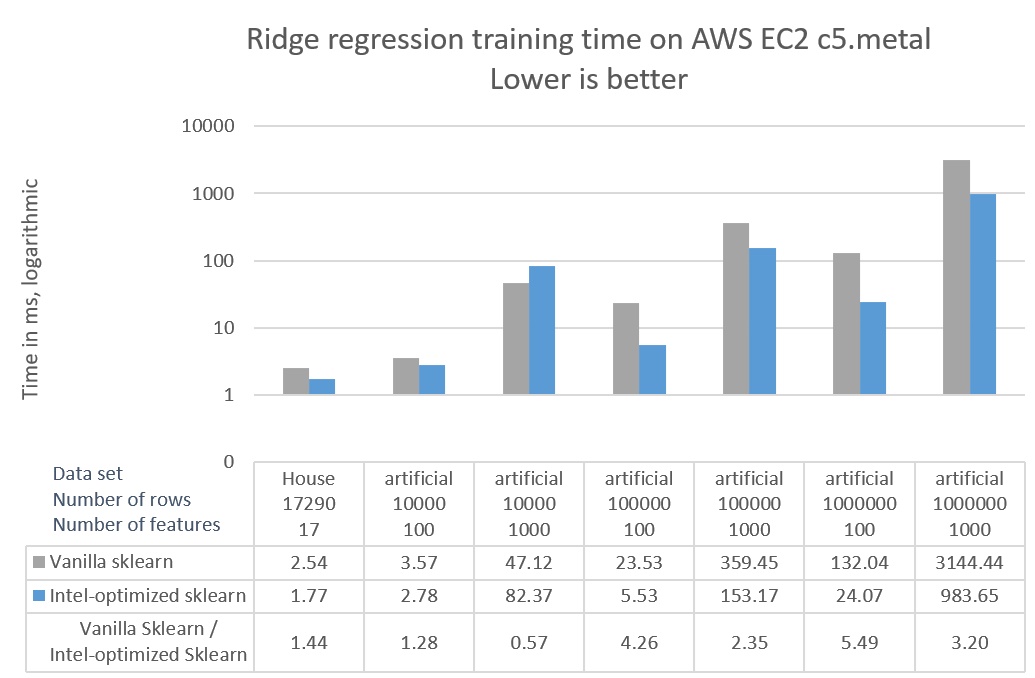
Figure 1. Ridge regression training time
For hardware details, see the following Configuration section. For details on the quality of trained models, see the Appendix.
Figure 1 shows that:
- Ridge regression training is up to 5.49x faster with the Intel-optimized scikit-learn than with vanilla scikit-learn.
- The performance improvement from the Intel-optimized scikit-learn increases with the size of the dataset.
What Makes scikit-learn in the Intel oneAPI AI Analytics Toolkit Faster?
For large datasets, ridge regression spends most of its compute time on matrix multiplication. Intel optimizations of ridge regression relies on the Intel® Math Kernel Library (Intel® MKL), which is highly optimized for Intel CPUs. Intel MKL uses single instruction, multiple data (SIMD) vector instructions from the Intel® Advanced Vector Extensions 512 available on the 2nd generation Intel Xeon Scalable processors. Compute-intensive kernels like matrix multiplication benefit significantly from the data parallelism that these instructions provide. Another level of parallelism for matrix multiplication is achieved by splitting matrices into blocks and processing them in parallel using Threading Building Blocks (TBB).
The Intel-optimized version of scikit-learn gives significantly better performance for ridge regression with no loss of model accuracy and little to no code modification. The performance advantages are not limited to just this algorithm. As mentioned previously, the list of optimized machine learning algorithms continues to grow.
Resources
Configuration
Hardware
c5.metal Amazon EC2 instance: Intel® Xeon® 8275CL processor, two sockets with 24 cores per socket, 192 GB RAM Operating System: Ubuntu* 18.04.3 LTS
Software
Vanilla scikit-learn: Python 3.8.0, scikit-learn 0.22, pandas 0.25.3
Intel oneAPI AI Analytics Toolkit with scikit-learn: Python 3.7.4, scikit-learn 0.21.3 optimized with daal4py 2020.0 build py37ha68da19_8, pandas 0.25.1
Python and accompanying libraries are the default versions installed by the conda package manager when configuring the respective environments.
Appendix
Table 1. Root mean squared deviation (RMSD) and the coefficient of determination (R2) for ridge regression models
| Ridge Regression Model Accuracy | ||||||
|---|---|---|---|---|---|---|
| Data Set | Number of rows | Number of columns | RMSD | R2 | ||
| Vanilla scikit-learn | Intel-optimized scikit-learn | Vanilla scikit-learn | Intel-optimized scikit-learn | |||
| King County | 17,290 | 17 | 200,221.014 | 200,221.014 | 0.69414 | 0.69414 |
| make_regression | 10,000 | 100 | 10.018 | 10.018 | 0.99969 | 0.99969 |
| make_regression | 10,000 | 1,000 | 9.609 | 9.609 | 0.99997 | 0.99997 |
| make_regression | 100,000 | 100 | 9.996 | 9.996 | 0.99970 | 0.99970 |
| make_regression | 100,000 | 1,000 | 9.987 | 9.987 | 0.99997 | 0.99997 |
| make_regression | 1,000,000 | 100 | 10.014 | 10.014 | 0.99969 | 0.99969 |
| make_regression | 1,000,000 | 1,000 | 9.995 | 9.995 | 0.99997 | 0.99997 |
______
You May Also Like
| Explore GPU Acceleration in the Intel® DevCloud Watch |
Intel® oneAPI AI Analytics Toolkit
Accelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python* libraries.
Get It Now