AI Tools
Achieve End-to-End Performance for AI Workloads, Powered by oneAPI
Discontinuation Notice
Intel® Developer Cloud for oneAPI will be discontinued effective October 31, 2024. This includes all features and services associated with the platform.
Accelerate Data Science & AI Pipelines
AI Tools from Intel (formerly referred to as the Intel® AI Analytics Toolkit) give data scientists, AI developers, and researchers familiar Python* tools and frameworks to accelerate end-to-end data science and analytics pipelines on Intel® architecture. The components are built using oneAPI libraries for low-level compute optimizations. The AI Tools maximize performance from preprocessing through machine learning, and provides interoperability for efficient model development.
Using the AI Tools, you can:
- Train on Intel® CPUs and GPUs and integrate fast inference into your AI development workflow with Intel®-optimized, deep learning frameworks for TensorFlow* and PyTorch*, pretrained models, and model optimization tools.
- Achieve drop-in acceleration for data preprocessing and machine learning workflows with compute-intensive Python packages, Modin*, scikit-learn*, and XGBoost.
- Gain direct access to analytics and AI optimizations from Intel to ensure that your software works together seamlessly.
Download the AI Tools
Accelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python* libraries.
{kind=link}
Features
Optimized Deep Learning
- Leverage popular, Intel-optimized frameworks—including TensorFlow and PyTorch—to use the full power of Intel® architecture and yield high performance for training and inference.
- Expedite development by using the open source, pretrained, machine learning models that are optimized by Intel for best performance.
- Take advantage of automatic accuracy-driven tuning strategies along with additional objectives like performance, model size, or memory footprint using low-precision optimizations.
Data Analytics and Machine Learning Acceleration
- Increase machine learning model accuracy and performance with algorithms in scikit-learn and XGBoost, optimized for Intel architecture.
- Scale out efficiently to clusters and perform distributed machine learning by using Intel Extension for Scikit-learn.
High-Performance Python*
- Take advantage of the most popular and fastest growing programming language for AI and data analytics with underlying instruction sets optimized for Intel architecture.
- Process larger scientific data sets more quickly using drop-in performance enhancements to existing Python code.
- Achieve highly efficient multithreading, vectorization, and memory management, and scale scientific computations efficiently across a cluster.
Simplified Scaling across Multi-node DataFrames
- Seamlessly scale and accelerate pandas workflows to multicores and multi-nodes with only one line of code change using the Modin, an extremely lightweight parallel DataFrame.
- Accelerate data analytics with high-performance compute engines, such as Ray, Dask*, or Message Passing Interface (MPI).
{kind=link}
{kind=link}
Demonstrations
Fine-Tuning the Falcon 7-Billion Parameter Model with Hugging Face* and oneAPI
Explore the challenge of optimizing the Falcon large language model (LLM) on Intel® Xeon® processors with Intel® Advanced Matrix Extensions (Intel® AMX) using Hugging Face* APIs and AI Tools from Intel.
Language Identification: Building an End-to-End AI Solution Using PyTorch*
This in-depth solution demonstrates how to train a model to perform language identification and optimize the model with quantization.
Speed Up Machine Learning Training on CPUs
See how two Intel® tools can be used as drop-in replacements for stock pandas and scikit-learn* libraries to speed up machine learning model development and deployment on CPUs instead of GPUs.
Case Studies
How Software Development Tools from Intel are Accelerating IBM Watson* NLP Library
Intel and IBM* collaborated on IBM Watson* natural language processing library (NLP), optimizing it using Intel® tools to achieve up to 165% improvements.
Video Delivery and Recommendations at Netflix*
The Netflix* Performance Engineering Team improved viewer experience while lowering cloud and streaming costs and techniques by using Intel software optimizations to exploit the full benefit of Intel hardware capabilities.
HippoScreen* Improves AI Performance by 2.4x with Intel® Tools
The Taiwan-based neurotechnology startup used AI Tools from Intel together with Intel® VTune™ Profiler to the improve efficiency and build times of deep learning models used in its Brain Waves AI system.
AI Tools Selector Options
PyTorch* Optimizations from Intel
Intel is one of the largest contributors to PyTorch, providing regular upstream optimizations to the PyTorch deep learning framework that provide superior performance on Intel architectures. The AI Tools Selector includes the latest binary version of PyTorch tested to work with the rest of the tools, along with Intel Extension for PyTorch, which adds the newest Intel optimizations and usability features.
TensorFlow* Optimizations from Intel
TensorFlow has been directly optimized for Intel architecture, in collaboration with Google*, using the primitives of Intel® oneAPI Deep Neural Network Library (oneDNN) to maximize performance. The AI Tools Selector provides the latest binary version compiled with CPU-enabled settings, along with Intel Extension for TensorFlow, which seamlessly plugs into the stock version to add support for new devices and optimizations.
Reduce model size and speed up inference for deployment on CPUs or GPUs. The open source library provides a framework-independent API to perform model compression techniques such as quantization, pruning, and knowledge distillation.
Get repeatable value with a simpler way to build, deploy, and manage models on any infrastructure. Intel Tiber AI Studio is a full-service machine learning operating system that enables you to manage all your AI projects from one place. It is an optional component and requires a separate license.
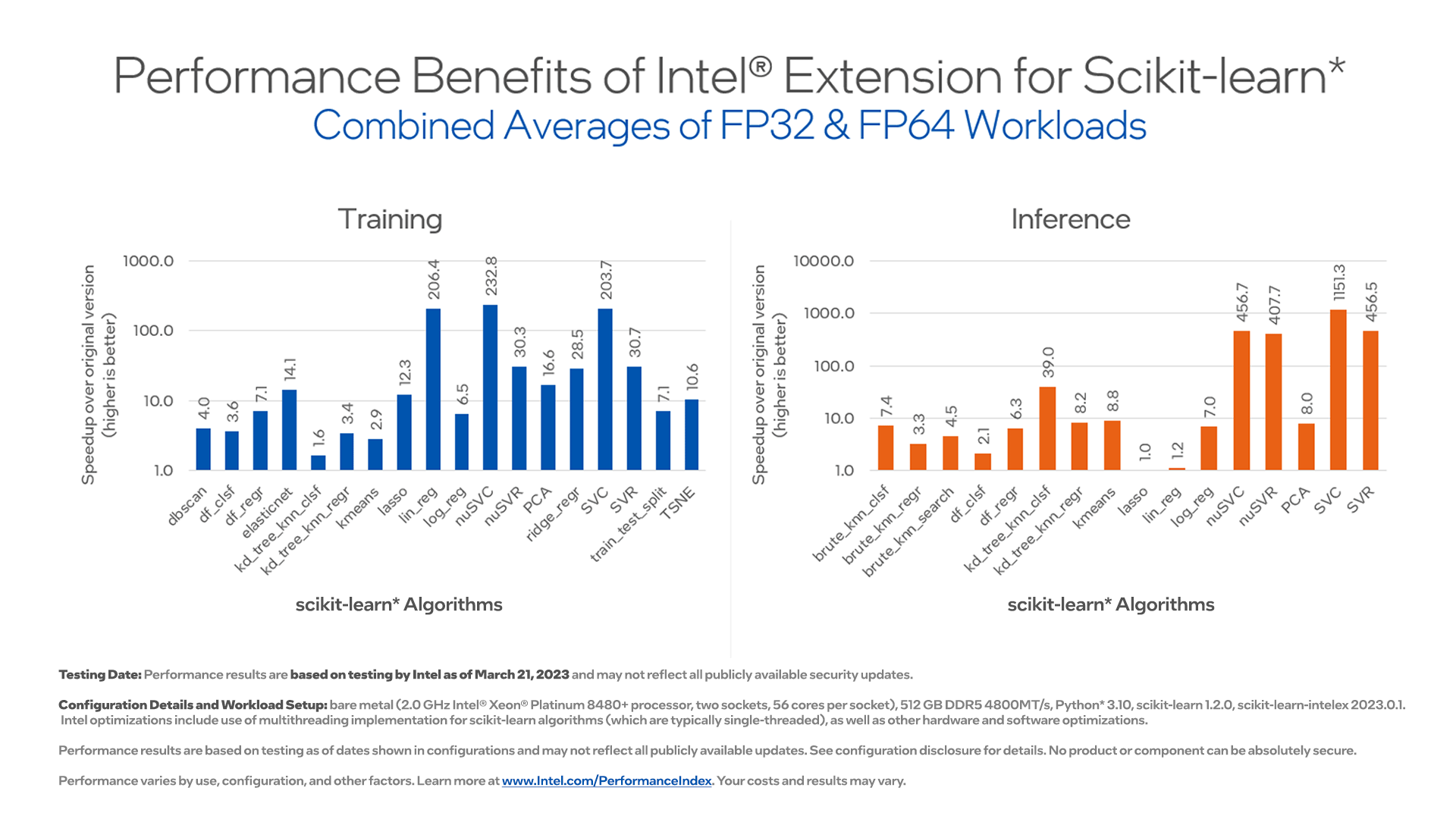
Intel® Extension for Scikit-learn*
Seamlessly speed up your scikit-learn applications on Intel® CPUs and GPUs across single nodes and multi-nodes. This extension package dynamically patches scikit-learn estimators to use oneDAL as the underlying solver, while achieving the speed up for your machine learning algorithms. The AI Tools Selector also includes stock scikit-learn to provide a comprehensive Python environment installed with all required packages. The extension supports up to the last four versions of scikit-learn, and provides flexibility to use with your existing packages.
Intel® Optimization for XGBoost*
In collaboration with the XGBoost community, Intel has been directly upstreaming many optimizations to provide superior performance on Intel CPUs. This well-known machine learning package for gradient-boosted decision trees now includes seamless, drop-in acceleration for Intel architecture to significantly speed up model training and improve accuracy for better predictions.
Accelerate your pandas workflows and scale data preprocessing across multi-nodes using this intelligent, distributed DataFrame library with an identical API to pandas. The library integrates with Ray, Dask*, and MPI compute engines to distribute the data without having to write code.
Convert and optimize models trained using popular frameworks like TensorFlow and PyTorch. Optimize and deploy with best-in-class performance across a mix of Intel CPUs, GPUs (integrated or discrete), NPUs, or FPGAs.
Efficiently map models developed using PyTorch and TensorFlow onto Intel Gaudi AI accelerators. The software suite includes a graph compiler and runtime, a Tensor Processor Core (TPC)* kernel library, firmware and drivers, and developer tools for custom kernel development and profiling.
Intel offers a full suite of AI software tools in addition to those available in the AI Tools Selector.
Documentation & Code Samples
Training
- Optimize Data Science and Machine Learning Pipelines
- Enhance Deep Learning Workloads on the Latest Intel Xeon Processors
- Get Better TensorFlow Performance on CPUs and GPUs
- Develop Efficient AI Solutions with Accelerated Machine Learning
- Optimize Transformer Models with Intel and Hugging Face Tools
- Accelerate AI Inference without Sacrificing Accuracy
Specifications
Processors:
- Intel Xeon processors
- Intel Xeon Scalable processors
- Intel® Core™ processors
- Intel® Data Center GPU Flex Series
- Intel® Data Center GPU Max Series
Language:
- Python
Operating systems:
- Linux*
- Windows*
Development environments:
- Compatible with Intel compilers and others that follow established language standards
- Linux: Eclipse* IDE
Distributed environments:
- MPI (MPICH-based, Open MPI)
Support varies by tool. For details, see the system requirements.
Get Help
Your success is our success. Access these support resources when you need assistance.
Stay Up to Date on AI Workload Optimizations
Sign up to receive hand-curated technical articles, tutorials, developer tools, training opportunities, and more to help you accelerate and optimize your end-to-end AI and data science workflows. Take a chance and subscribe. You can change your mind at any time.