Increasingly, today’s software workloads—from simple video streaming and image processing to complex data analytics and science applications—are designed to be executed across multicore, heterogeneous hardware architectures. The modern concept of accelerated computing helps with expedited and efficient multiarchitecture programming across these devices by assigning the data-intensive and compute-intensive parts of the application to the best available computation unit in a given hardware configuration.
In practice, accelerated computing is the combination of software that is optimized for its target hardware. But in a multiarchitecture environment, there are multiple hardware components. So software applications must be coded in such a way as to utilize the processing power of each—multi-core architecture, advanced memory management, built-in accelerators, extended instruction sets of modern CPUs, and GPUs’ highly parallel compute power.
To ensure code portability across different hardware configurations and reduce the cost of migrating software from one platform to another, accelerated compute programming models provide a hardware abstraction layer and common framework.
Several well-known frameworks, such as SYCL*, OpenMP*, and OpenCL™ are available to assist you in accomplishing this. They eliminate the need to write and rewrite the same code in different programming languages to execute it on different devices and operating systems with distinct APIs, libraries, and SDKs. Instead of sticking to the hardware from a specific vendor (for instance, CUDA* is limited to NVIDIA GPUs), these frameworks let you take advantage of various accelerators.
UXL Foundation towards the Future
The open oneAPI initiative and specification evolved into a cornerstone for the newly formed Unified Acceleration (UXL) Foundation. As a cross-industry group committed to delivering an open standard accelerator programming model that simplifies development of performant, cross-platform applications and hosted by the Linux Foundation's Joint Development Foundation (JDF), the Unified Acceleration Foundation brings together ecosystem participants to establish an open standard for developing applications that deliver performance across a wide range of architectures.
With its distinguished list of participating organizations and partners, including Arm, Fujitsu, Google Cloud, Imagination Technologies, Intel, Qualcomm Technologies, Inc. and Samsung, the UXL Foundation is poised to take the adoption momentum the oneAPI Initiative enjoyed to the next level. Together they are dedicated to promoting open source collaboration and development of a cross architecture unified programming model.
oneAPI at a Glance
oneAPI is the open source, open standards-based, unified programming model for accelerated computing that started it all. Leveraging SYCL, LLVM and a range of tools, libraries, and parallel programming C++ language extensions, it is a comprehensive standard for accelerated computing. With the major advantages of code reusability and portability, oneAPI helps you attain productivity across heterogeneous architectures from different manufacturers.
The bold vision behind oneAPI and behind the UXL Foundation and its members is to achieve multiarchitecture, multi-vendor software portability while utilizing all the hardware capabilities and providing you with maximum performance yield.
By “multiarchitecture” we mean that a single source code can be compiled and run across diverse hardware, including but not limited to CPUs, GPUs, and FPGAs. The term “multi-vendor” signifies the ability to compile and execute a common code on devices from different manufacturers such as the new foundation’s founding partners.
The exciting vision to enable targeting multiple hardware architectures with a common codebase adds flexibility when deploying your applications and helps to future-proof them.
The oneAPI Industry Adoption page provides a sense of the significant number of hardware and software companies supporting and benefiting from it expanding day by day!
oneAPI Specification and Its Intel Implementation
The oneAPI specification is open source and based on industry standards. It consists of a set of calling conventions and interfaces based on both direct programming and library API-based programming paradigms.
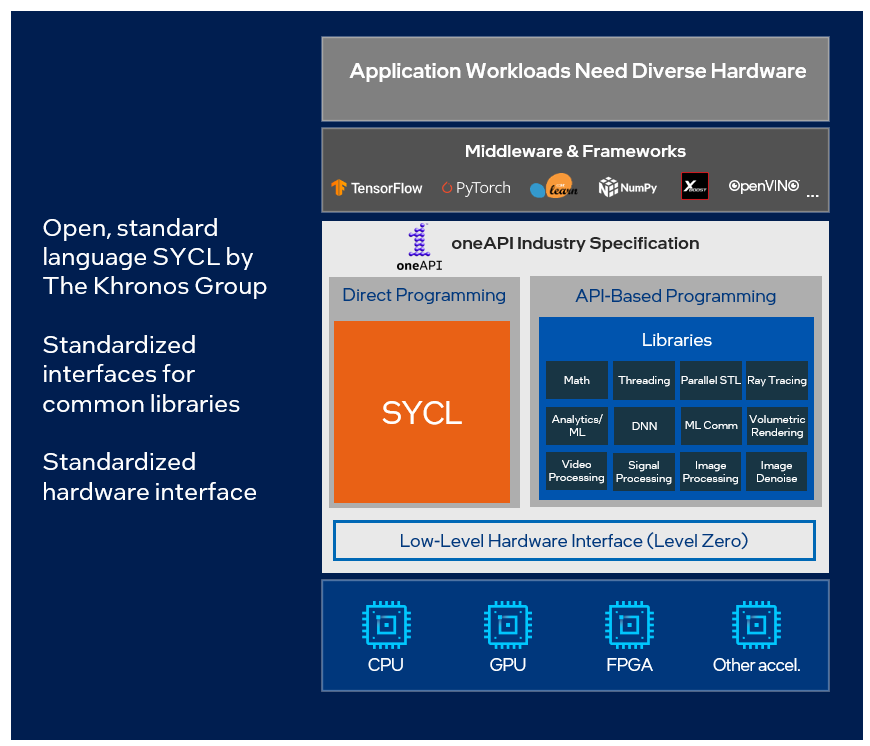
To efficiently leverage all specification elements in their software, developers need an implementation built in compliance with it.
Intel® has its own highly optimized high-performance reference implementation of the oneAPI specification. Its core component tools and libraries are included in the Intel® oneAPI Base Toolkit, also known simply as the Base Kit.
So let’s dive into the major Base Kit constituents, including their benefits to all developers.
Base Kit: oneAPI Spec Components and More in One Place!
The Base Kit is a comprehensive collection of Intel implemented and optimized versions of the core oneAPI spec components. It also provides add-ons such as a C++ with SYCL-enabled Intel® oneAPI DPC++/C++ Compiler, The Intel® DPC++ Compatibility Tool for CUDA-to-SYCL migration, and a couple of tools for performance analysis and optimization like the Intel® VTune™ Profiler and Intel® Advisor.
Various components of the Base Kit can assist you at different stages of the software design life cycle like application design, development, debugging, testing, and performance tuning.
Using the comprehensive collection of development tools and libraries the toolkit provides, you can develop performant, data-centric applications and achieve compute acceleration across heterogenous architectures and accelerators.
See the complete list of all the Intel oneAPI Base Toolkit components.
Let us briefly discuss the four key Base Kit components that help developers (1) create high-performance applications and (2) realize the value of underlying hardware:
- Code generation
- Debugging & performance optimization
- AI & analytics
- CUDA-to-SYCL migration
1. Code Generation
oneAPI supports C++ with SYCL, a direct-programming model that allows you to get the combined advantages of standard C++ and SYCL. The Base Kit includes the following:
Clang* Frontend-Compatible Intel oneAPI DPC++/C++ Compiler
Based on open source LLVM compiler technology, the compiler enables multi-platform compilation of standard C++ code with support for the latest accelerated-compute frameworks, including SYCL and OpenMP. Its capability to generate optimized host and accelerator codes and its compatibility with optimized Intel libraries lets you take full advantage of your hardware potential. The SYCL-compatible, Clang-based compiler easily integrates with third-party libraries and build environments.
→ Check out our blog and the documentation for detailed information on the Intel oneAPI DPC++/C++ Compiler.
Intel® oneAPI DPC++ Library (oneDPL)
This Base Kit component lets you benefit from the direct-programming paradigm of oneAPI. An extension of the C++ Standard Template Library (STL), oneDPL complements the core C++ STL API with parallelized C++17 algorithms and accelerated SYCL kernels, resulting in performance speed-up and high productivity on CPUs, GPUs, and FPGAs.
Its seamless integration with the Intel® DPC++ Compatibility Tool (also part of the Base Kit) eases the CUDA-to-SYCL migration process, helping you perform cross-device programming with the help of custom iterators and algorithm extensions of Parallel STL (PSTL) and Boost.Compute* libraries.
→ Go through our blog and the oneDPL documentation - delve deeper into the library!
Intel® oneAPI Threading Building Blocks (oneTBB)
oneTBB uses C++ standard-compliant classes and augments the capabilities of oneDPL by simplifying the process of adding parallelism to complex C++ applications. Instead of breaking a program into multiple functional blocks with a separate thread handling each of them, oneTBB allows multiple threads to work on different parts of a collection of threads simultaneously.
The division of a collection into smaller pieces makes it possible to utilize the potential of a larger number of processors. Thus, oneTBB enables scalable data-parallel programming with no prerequisite of being a threading expert.
This C++ standard-based mechanism for achieving code and data parallelism makes the library compatible and composable with other threading packages, resulting in its easy integration with oneAPI as well as legacy code.
→ Understand the features of oneTBB in more details through our concurrent containers blog and scalable memory allocation blog.
→ Check out oneTBB and learn how to turbocharge your C++ application in a concurrent environment.
Intel® oneAPI Math Kernel Library (oneMKL)
Mathematical computations are integral to many applications in high-performance computing, finance, science, data analysis, machine learning, artificial intelligence, and beyond.
oneMKL is a feature-rich solution to deal with simple and complex numerical calculations on Intel® architectures.
It is an updated version of its predecessor, the Intel® Math Kernel Library, with the latest SYCL API support. The fastest and most-used math library for Intel-based systems1 has been continuously enhanced and optimized since its initial release 20 years ago.
This library accelerates a wide spectrum of math processing routines, including linear algebra, random number generation (RNG), Fast Fourier Transforms (FFT), summary statistics, and vector math.
In addition to supporting C, C++, and Fortran languages, it enables GPU offloading of math routines and, hence, supports heterogeneous compute with OpenMP and SYCL. It reduces the development time and enhances the performance of math-heavy applications on the latest generations of Intel hardware such as the 4th Gen Intel® Xeon® Scalable Processors and Intel® Data Center GPU Max Series, with support for built-in accelerators such as Intel® Advanced Matrix Extensions (Intel® AMX) and SIMD vector instruction and register sets like the Intel® Advanced Vector Extensions 512 (Intel® AVX-512).
→ Read our oneMKL blog and check out its documentation for more details.
2. Debugging and Performance Optimization
Two design and analysis tools are available in the Base Kit that can assist you with achieving the desired performance outcomes from your application. Let’s have a quick look at each of them!
Intel VTune Profiler assists with analyzing and fixing performance bottlenecks and optimizing application performance, system performance, and system configuration for all application domains, including IoT, cloud, and HPC. With it, you can:
- Fine-tune the performance of your entire application with awareness of platform hardware properties like number of cores, available GPUs, memory latency, and cache management.
- Uncover and fix various aspects such as anomaly detection, hotspot analysis for CPU utilization issues, Python* performance analysis, GPU offload analysis, memory performance analysis, threading efficiency analysis, and much more.
- Analyze performance across several programming languages and frameworks, including Fortran, C, C++, SYCL, JAVA*, Python, and OpenCL.
→ Read our blog and check out the documentation to explore various ways to analyze and optimize application performance with Intel VTune Profiler.
Intel Advisor assists with designing high-performance parallel applications with Fortran, C, C++, SYCL, OpenMP, and OpenCL code. With it, you can:
- Analyze the measured performance of the application against the actual potential of the hardware by using roofline analysis for CPUs and GPUs.
- Tap into features such as vectorization insights, thread prototyping, and GPU offload modeling to make critical decisions such as which loops should be vectorized, which threading model should be implemented, and which code sections should be offloaded respectively, for the best performance results.
→ Here are the links to our blog and the documentation for exploring the Intel Advisor tool.
We encourage you to rely on Intel Advisor for application design and parallel execution flow decisions. The performance results can then be intricately analyzed and optimized using Intel VTune Profiler.
3. AI and Analytics
AI/ML and Data Science are the cutting-edge technologies in the modern software industry. The latest developments and advancements in these fields demand optimized implementations of algorithms as well as accelerated data processing. The Base Kit provides two of the extensively used oneAPI libraries for machine learning and data analytics applications. Let’s briefly look at them.
Intel® oneAPI Data Analytics Library (oneDAL) is a powerful component of the Base Kit for deploying high-performance ML and data science applications on Intel CPUs and GPUs. With it, you can:
- Accelerate all the stages of a data analytics pipeline—data preprocessing, transformation, analysis, modeling, validation, and decision making.
- Implement a wide range of classical ML algorithms such as linear regression, logistics regression, decision forest, naïve bayes classifier, and more!
- Leverage its provided SYCL interfaces and GPU usage support for algorithms such as k-means clustering, k-Nearest Neighbors (kNN), Support Vector Machine (SVM), and Principal Component Analysis (PCA).
Intel® oneAPI Deep Neural Network Library (oneDNN) enhances the performance of deep learning workloads on Intel CPUs and GPUs. With it, you can:
- Develop platform-independent deep learning applications faster by using its provided, optimized building blocks such as convolutions, pooling, batch normalization, Recurrent Neural Network (RNN) cells, and more.
- Further improve the performance of some state-of-the-art frameworks such as the OpenVINO™ toolkit, PyTorch* and TensorFlow*.
→ Check out oneDAL documentation and oneDNN documentation for more information on these AI libraries of oneAPI.
→ NOTE: For those interested in developing accelerated end-to-end AI/ML and data science workloads powered by oneAPI on Intel architectures, Intel® AI Analytics Toolkit (AI Kit) is a great resource. It helps you obtain high performance through optimized deep learning frameworks such as Intel® Extension for TensorFlow, Intel® Extension for PyTorch, and Intel® Neural Compressor; data analytics libraries such as Intel® Distribution of Modin*, and ML libraries such as Intel® Optimization for XGBoost and Intel® Extension for Scikit-learn*.
The AI Kit also provides Intel® Distribution for Python, a direct-programming paradigm for high-performance numerical and scientific Python computations. It includes Python wrappers for oneDAL.
Last but not least, the Intel® oneAPI Collective Communications Library (oneCCL) provides optimized implementation of collective communication patterns (such as AllReduce, ReduceScatter, Broadcast, etc.) occurring in deep learning applications.
With it, you can delivery scalable and efficient training of deep neural networks in a distributed environment.
→ Read our oneCCL blog and check out its documentation for more details.
4. CUDA-to-SYCL Migration
The vision of the oneAPI initiative is to provide an open-source, standards-based, cross-vendor, unified programming model.
SYCL plays a vital role in achieving this aim by forming a cross-platform standard abstraction layer with the benefits of code reusability, portability, and high performance across diverse architectures. Hence, easy-to-use and effective ways of migrating proprietary vendor-locked application to SYCL are required.
The Intel DPC++ Compatibility Tool is available for easy automated migration of CUDA code to portable, multi-architecture SYCL code. With it, you can:
- Migrate most of the CUDA files, including CUDA language kernels and library API calls, to SYCL. (Typically, 90%-95% of CUDA code automatically migrates to SYCL.)2
- Ensure completeness and functional correctness of the migration results by using its comprehensive and detailed hints and inline comments.
A detailed diagnostic message reference maintained by the oneAPI community can help you interpret and resolve the inline comments provided by the tool.
→ We also have a counterpart of the Intel DPC++ Compatibility Tool called SYCLomatic, an open-source project for assisted migration of CUDA GPU code to SYCL code.
→ Check out our blog and the official documentation of the Intel DPC++ Compatibility Tool.
→ If you’re targeting NVIDIA or AMD GPUs, be sure to use the Codeplay oneAPI Plugin for NVIDIA GPUs and Codeplay oneAPI Plugin for AMD GPUs with your SYCL codebase.
Wrap Up
The vision of the UXL Foundation and of oneAPI is to provide a multi-architecture and multi-vendor unified programming model for high-performance results. The Intel oneAPI Base Toolkit provides a convenient binary implementation and distribution based on oneAPI that represents a comprehensive one-stop-shop collection for your x86 and Intel architecture host development needs when developing for a wide and diverse range of compute acceleration offload devices. Unleash the full potential of your hardware by leveraging the Intel oneAPI Base Toolkit—our set of core oneAPI tools and libraries.
The oneAPI specification and the oneAPI initiative that the Base Kit is built on is not a single-handed effort. It is a joint community effort backed by the spirit of the Linux Foundation's Joint Development Foundation (JDF) and our new partners in the Unified Acceleration Foundation.
Additional Resources
Here are some useful resources for you to plunge into oneAPI:
- Unified Acceleration (UXL) Foundation
- oneAPI Specification
- Intel oneAPI webpage
- Intel® oneAPI Toolkits
- oneAPI Code Samples
We also encourage you to learn about other AI, HPC, and Rendering tools in Intel’s oneAPI-powered software portfolio.
Get The Software
Visit this link to download the Intel oneAPI Base Toolkit.