Introduction
Dynamic memory allocation is a primary consideration when developing and optimizing any software application. It is an even tougher task in parallel applications, which have challenging demands, including:
- Moderate memory consumption
- Faster memory allocation and deallocation among threads
- Keeping allocated memory hot in the CPU cache
- Avoiding the reaching of cache-associativity limits
- Preventing false sharing and thread contention
Numerous memory managers exhibit different efficiencies for different applications.
This blog focuses on one such memory allocator provided by the Intel® oneAPI Threading Building Blocks (oneTBB) library.
oneTBB's approach maintains and expands on the API of the Standard Template Library (STL) template class std::allocator. It introduces two similar templates, scalable_allocator<T> and cache_aligned_allocator<T>, to address the critical issues in parallel programming listed above.
oneTBB Overview
oneTBB is a flexible yet performant threading library that simplifies parallel programming in C++ across accelerated hardware. Supported for Windows*, Linux*, macOS*, and Android* applications, oneTBB can handle several tedious tasks such as adding parallelism to complex loop structures, memory allocation, and task scheduling.
General architecture of oneTBB memory allocator
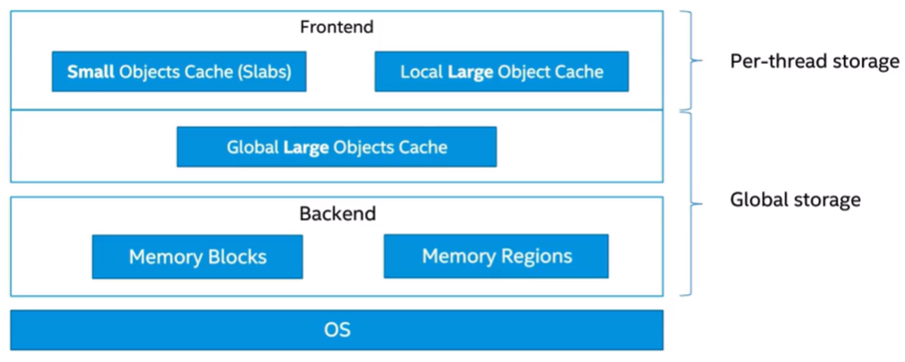
Figure 1. Structure of oneTBB allocator
oneTBB memory allocator consists of two distinct layers: frontend and backend (Figure 1).
The frontend acts as a caching layer, holding objects inside two storage types viz. per-thread heap and global heap. It requests memory from the backend. The backend reduces the number of expensive calls to the OS, serving the needs of the frontend while simultaneously avoiding significant fragmentation.
oneTBB memory allocator defines two types of objects: small (<=8kB size) and large (>8kB size); each has a different structure and allocation strategy. Let’s understand how frontend and backend handle memory allocation of these objects.
Frontend: handling small objects
oneTBB allocator uses a thread-private heap to cut down the amount of code that requires synchronization, reduce false sharing, and provide better scalability. Each thread allocates its own copy of the heap structure:
- A thread-local storage (TLS) mainly serves as a storage for small objects, but it can hold a moderately-sized pool of large objects for the same purpose, i.e., to reduce synchronization.
- Small-object heap is segregated—it uses different storage bins to allocate objects of different sizes. A memory request is rounded up to the nearest object size. This technique provides better locality for similar-sized objects that are often used together.
Bin storage is a widely used technique in oneTBB allocator. A bin only holds objects of a particular size, and it is organized as a doubly linked list of so-called slabs. At each moment, there is at most one active slab used to fulfill allocation request for a given object size. Once the active slab has no more free objects, the bin is switched to use the next partially empty slab (if available), otherwise an entirely empty slab. If nothing is available, a new slab is acquired. The slab with all its objects freed returns to the backend.

Figure 2. Slab structure for small objects
Slab data structure
Let’s look further at what a slab data structure is and how it stacks small objects (Figure 2).
Each slab block is a 16KB aligned structure accommodating objects of the same size. It is a free list allocator that connects unallocated regions of memory together into a Last-In First-Out (LIFO) linked list and makes malloc-free operations very simple.
To free an object, the library only has to link it to the top of the list.
To allocate an object, it simply needs to remove one from the top of the list and use it.
A foreign thread can interfere with the operations of the owning thread with cross-deallocation, possibly leading to slow down of the operation. To avoid that, two separate free lists are used for objects returned by the owner and by the foreign thread: public and private.
Public free list merges into the private list when the private free list cannot serve the memory request. This is a slow operation because the former has to acquire the lock in order to merge with the latter, so it is better to avoid such situations.
Frontend: handling large objects
Large objects are mainly cached in the global heap that is segregated similarly to the small objects' storage, using different storage bins to allocate objects of different sizes. This approach enables working with different bins in parallel. However, concurrent access to the same bin is protected by internal mutual exclusion primitive. To keep the size of an allocated data structure and an internal fragmentation in check, two types of cache exist – large and huge, which only differ in size of bins. Each bin holds a LIFO list of cached objects in order to keep the object that is hot in cache on the top. By default, this cache is not limitless and to keep the memory consumption decent, the library cleans up the cache from time to time.
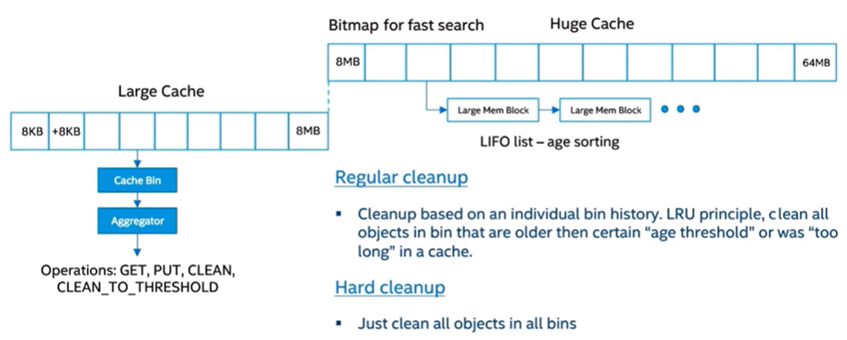
Figure 3. Memory allocation for large objects
Backend: overall structure
The goal of the backend is to reduce the number of expensive calls to the OS serving the needs of the frontend while also avoiding significant fragmentation.
How is this achieved? On each memory request, the backend maps a bigger memory region than requested with a certain granularity, no less than a memory page. Then it splits the needed memory block according to the requested size, which may become a slab or a large object as shown in Figure 4. The last remaining block can be split for another request from the frontend and so on. Fragmentation here is controlled by three blocks coalescing: a block itself, its left neighbor, and its right neighbor. Each memory block has a lock containing its size.
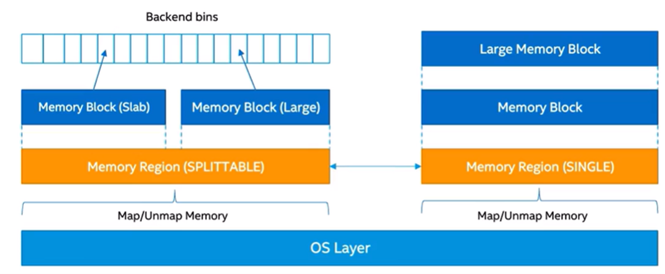
Figure 4. Backend structure
There is no shared state between a region and a block—they are unaware of each other, which improves scalability. We can thus split and coalesce memory chunks with no caching. However, very large objects are mapped and unmapped directly from the OS so as not to split them into pieces. There are two types of memory region: splittable and single as shown in Figure 4.
oneTBB memory allocator templates
Among several oneTBB memory allocator templates resembling the STL class std::allocator, scalable_allocator<T>, and cache_aligned_allocator<T> resolve the critical issues of scalability and false sharing (i.e., two threads attempting to access different words that share the same cache line), respectively, in a concurrent environment.
The scalable_allocator<T> requires only the oneTBB scalable memory std::allocator and can be leveraged independently in absence of any other components of oneTBB.
The tbb_allocator<T> and cache_aligned_allocator<T> templates use the scalable memory allocator by default but if it is unavailable, they use the standard C memory allocation methods: malloc and free.
oneTBB memory allocator configuration
oneTBB memory allocator is a general-purpose allocator, but you can alter its behavior using the following API functions:
- scalable_allocation_mode(): You can set certain memory allocator parameters such as a heap size using this function. The defined parameters remain in effect until another call is made to the function.
- scalable_allocation_command(): This function enables performing cleaning operations of the per-thread as well as the global memory buffers.
You can also configure the allocator using a few environment variables as follows. However, scalable_allocation_mode() always gets priority over the environment variables.
- TBB_MALLOC_USE_HUGE_PAGES instructs the allocator to use huge pages if enabled by OS.
- TBB_MALLOC_USE_HUGE_OBJECT_THRESHOLD defines the lower bound threshold (size in bytes) for allocations that are not released back to OS unless a cleanup is explicitly requested.
Scalable memory-pool feature
The memory-pool feature of oneTBB allocator allows users to provide their own memory for thread-safe management by the allocator and group different memory objects under specific pool instances. It enables quick deallocation of all the memory, less memory fragmentation, and synchronization between independent groups of memory objects.
The memory pool mainly consists of two classes for thread-safe memory management: tbb::fixed_pool and tbb::memory_pool. Both utilize a user-specified memory provider. However, the first one is for allocating memory block(s) to small objects while the second one can grow on-demand and relinquish. A class called tbb::memory_pool_allocator allows memory-pool usage inside an STL container. See detailed information on scalable memory pools.
Memory API replacement library
The easiest way of using the oneTBB allocator without even explicit usage of C/C++ API interface is to link your application with the memory-replacement API library called tbbmalloc_proxy. Using this, you can automatically replace all calls with the standard functions for dynamic memory allocation with a oneTBB scalable equivalent. Here is a detailed description of using dynamic memory allocation on Windows and Linux.
Wrap-up
With oneTBB memory allocator, you can efficiently handle memory allocation in your C++ applications, be it in a concurrent or a non-concurrent environment. Get started with oneTBB to leverage its memory allocator and several other amazing features such as concurrent containers for performant threading experience. Get oneTBB as a part of the Intel® oneAPI Base Toolkit or download the stand-alone version of the library today!
Useful resources
Acknowledgements
We would like to thank Chandan Damannagari, Rob Mueller-Albrecht, Alexandr Konovalov, Piotr Balcer, Krzysztof Filipek, Ekaterina Semenova and Lukasz Plewa for their contributions to this blog.