SYCL 2020 is an exciting update for C++ programmers looking to take advantage of accelerators. We have both had the pleasure of contributing to the SYCL specification, a book on SYCL, and the DPC++ open source project to implement SYCL into LLVM. We would like to share our pick for our favorite new features added to SYCL in the SYCL 2020 specification. We offer these as our opinions as Intel engineers, not on behalf of Khronos.
SYCL
SYCL is a Khronos standard that brings support for heterogeneous programming to C++. The SYCL 2020 specification was finalized in late 2020, and compiler support has been growing ever since. (See the Khronos website for information on implementations.)
The case for SYCL is articulated in many places, including Considering a Heterogeneous Future for C++ and numerous other resources enumerated on sycl.tech. Put simply, SYCL addresses a key challenge: How do we enable heterogeneous programming in C++, with portability across vendors and architectures?
Thanks to strong community input, SYCL 2020 has exciting new features to serve the goal of being strongly multivendor and multiarchitecture. In this article, we discuss the functionality of and motivation for these new features.
The Outstanding Five
A key goal of SYCL 2020 is to align SYCL with ISO C++, which has two benefits. First, it ensures that SYCL feels natural to C++ programmers. Second, it allows SYCL to act as a proving ground for multivendor, multiarchitecture solutions to heterogeneous programming that may inform other C++ libraries (and perhaps ISO C++ itself).
Many of the syntactic changes in SYCL 2020 are a result of updating the base language from C++11 to C++17, enabling developers to take advantage of features such as class template argument deduction (CTAD) and deduction guides. But there are many new features, too! In this article, we choose to highlight five features new in SYCL 2020 and talk a little about why they matter.
- Backends open the door for SYCL implementations built on other languages/frameworks besides OpenCL, enabling SYCL to target a wider variety of hardware.
- Unified shared memory (USM) is a pointer-based access model, which serves as an alternative to the buffer/accessor model from SYCL 1.2.1.
- Reductions are a common programming pattern, which SYCL 2020 accelerates via a “built-in” library.
- The group library provides abstractions for cooperative work items, yielding additional application performance and programmer productivity through alignment with underlying hardware capabilities (regardless of vendor).
- Atomic references aligned with the C++20 std::atomic_ref extend the C++ memory model to heterogeneous devices.
Together, these additions help to establish the SYCL ecosystem as one that is open, multivendor, and multiarchitecture, enabling C++ programmers to fully utilize the potential of heterogeneous computing now and into the future.
1. Backends
With the introduction of backends, SYCL 2020 opens the door to implementations built on other languages/frameworks besides OpenCL. Consequently, the namespace has shortened to just sycl::, rather than cl::sycl::, and the SYCL header file has moved from <CL/sycl.hpp> to <sycl/sycl.hpp>.
The changes here are not simply cosmetic and have profound implications for SYCL. Although implementations are still free to build atop OpenCL (and many do), support for generic backends has transformed SYCL into a programming model that can target a larger variety of heterogeneous APIs and hardware. SYCL is now able to act as the “glue” between C++ applications and vendor-specific libraries, allowing developers to target a range of platforms more easily — and without having to change their code.
SYCL 2020 delivers on being truly open, cross-architecture, and cross-vendor.
The open source DPC++ compiler project, which is implementing SYCL 2020 in LLVM (clang), takes advantage of this new flexibility to support NVIDIA, AMD, and Intel® GPUs. SYCL 2020 delivers on being truly open, cross-architecture, and cross-vendor (Figure 1).
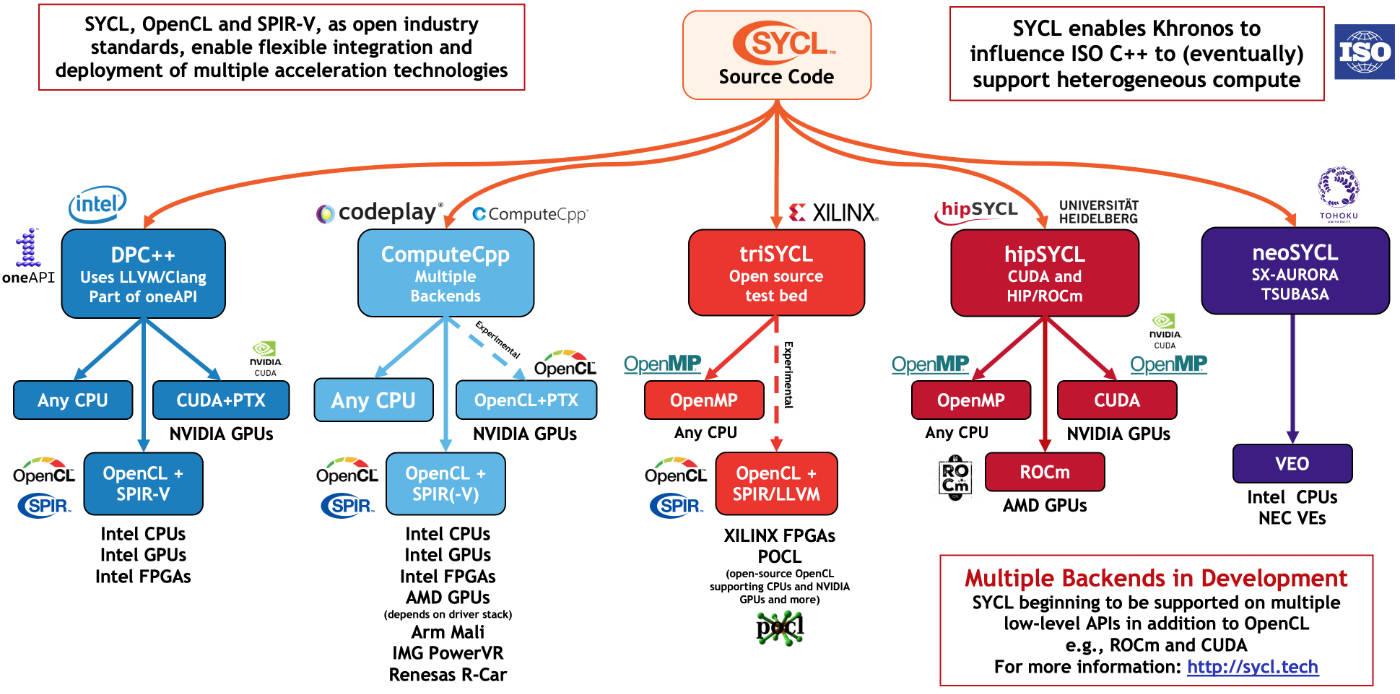
Figure 1. SYCL implementations targeting multiple backends, from https://www.khronos.org/sycl/
2. Unified Shared Memory
Some devices can support a unified view of memory with the host (CPU). SYCL 2020 calls this unified shared memory (USM), and it enables a pointer-based access model that serves as an alternative to the buffer/accessor model from SYCL 1.2.1.
Programming with USM has two key advantages. First, USM supplies a single, unified address space across host and device; pointers to USM allocations are consistent across devices and can be directly passed to kernels as arguments. This greatly simplifies the porting of existing pointer-based C++ and CUDA code to SYCL. Second, USM enables shared allocations that migrate automatically across devices, improving programmer productivity and providing compatibility with C++ containers (e.g., std::vector) and C++ algorithms (via oneDPL, Figure 2).

Figure 2. Using USM with C++ containers and algorithms, from our book examples.
The three different types of USM allocations provide programmers with as much or as little control over data movement as desired. Device allocations give programmers complete control over data movement in their applications. Host allocations are useful when data is used so infrequently that moving it is not worth the cost, or when the size of your data exceeds the memory of a device. Shared allocations are a happy medium that can automatically migrate to where they are being used, benefitting both performance and productivity.
3. Reductions
The SYCL 2020 approach to reductions was informed by other C++ reduction solutions, including the proposal in P0075 and the features implemented by the Kokkos and RAJA libraries.
Using the reducer class and the reduction function greatly simplifies the expression of variables with reduction semantics in SYCL kernels. It also gives implementations the freedom to employ compile-time specialization of reduction algorithms, providing high performance on a wide range of devices from many vendors.
For a real-life example of the improvements offered by SYCL 2020 reductions, we need look no further than the popular BabelStream benchmark, developed by the University of Bristol. BabelStream includes a simple dot product kernel that computes a floating-point summation across all work items in a kernel. The SYCL 1.2.1 version is 43 lines long, uses a specific algorithm (a tree reduction in work-group local memory), and requires the user to select the best work-group size for the device (Figure 3). Not only is the SYCL 2020 version shorter (at only 20 lines long), but it also has the potential to be more performance portable by leaving the selection of algorithm and work-group size to the implementation (Figure 4).

Figure 3. SYCL 1.2.1 version of BabelStream's dot product kernel.

Figure 4. SYCL 2020 version of BabelStream's dot product kernel.
4. Group Library
SYCL 2020 expands on the work-group abstraction from SYCL 1.2.1 with a new sub-group abstraction and a library of group-based algorithms.
The sub_group class represents the set of cooperative work items within a kernel that are running ”together,” providing a portable abstraction for the underlying hardware capabilities of different vendors. In the DPC++ compiler, sub-groups always map to an important hardware concept — SIMD vectorization on Intel® architectures, “warps” on NVIDIA architectures, and “wavefronts” on AMD architectures — and enable low-level performance tuning for SYCL applications.
In another example of close alignment with ISO C++, SYCL 2020 introduces a selection of group-based algorithms based on the C++17 algorithms: all_of, any_of, none_of, reduce, exclusive_scan and inclusive_scan. Each algorithm is supported at different scopes, enabling SYCL implementations to provide highly tuned, cooperative versions of these functions using work-group and/or sub-group parallelism.
The group library in SYCL 2020 lays the groundwork for more group types and a wider range of groupbased algorithms — watch this space!
5. Atomic References
C++20 took a big step forward with its atomics, introducing the ability to wrap types in an atomic reference (std::atomic_ref). SYCL 2020 adopts and extends this design (as sycl::atomic_ref) with support for address spaces and memory scopes, resulting in an atomic reference implementation fully prepared for the diverse world of heterogeneous computing.
SYCL does not deviate from ISO C++ lightly, and the concept of memory scopes was considered essential for enabling portable programming without sacrificing performance. Heterogeneous systems have complex memory hierarchies that shouldn't be ignored (Figure 5).
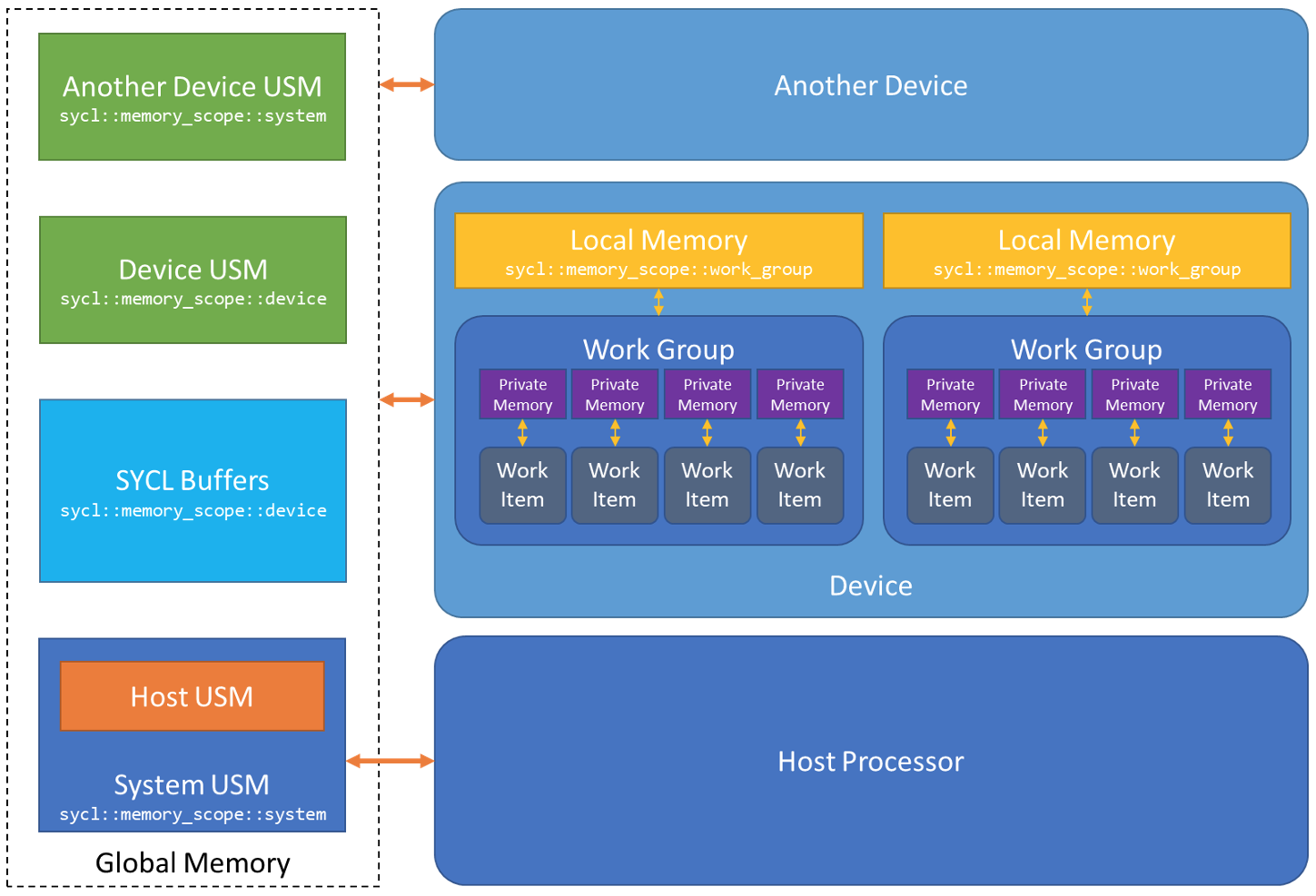
Figure 5. Using memory scopes enables atomic references to specify which memory must be made consistent, providing fine-grain control over which work-items and devices can "see" memory updates
Memory models and atomics are complex beasts and so, in order to support as many devices as possible, SYCL does not require all devices to support the full C++ memory model. Rather, SYCL provides a rich array of different device capabilities — another great example of being open to devices from any vendor.
Beyond SYCL 2020: Vendor Extensions
SYCL 2020's expanded support for more backends and hardware has encouraged the development of more vendor extensions. These extensions enable innovation that offers practical solutions today for devices that need it and informs the direction of future SYCL standards. Extensions are an important part of the standardization process — several features highlighted in this article were informed in part by extensions explored by the DPC++ compiler project.
In this section, we’ll briefly describe two new features supported in the DPC++ compiler project as SYCL 2020 vendor extensions.
Group-local Memory at Kernel Scope
SYCL 1.2.1 supports group-local memory via local accessors, which must be declared outside of a kernel and captured as a kernel argument. For programmers coming from languages like OpenCL or CUDA, this can feel unnatural, and so we have designed an extension that allows group-local memory to be declared inside of a kernel function. This change makes kernels more self-contained and can inform compiler optimizations (when the amount of local memory is known at compile-time).
FPGA-specific Extensions
We’ve enabled Intel® FPGAs in the DPC++ compiler project. We think our extensions, or something close to them, can prove portable to FPGAs from all vendors as well. FPGAs fill an important segment of the accelerator spectrum, and we hope our pioneering work will inform future SYCL standards with our experiences along with other extension projects from other vendors.
We added FPGA selectors that make it easy to specifically acquire an FPGA hardware or FPGA emulation device. The latter enables fast prototyping, a critical consideration for software developers when targeting FPGAs. FPGA LSU controls give us tuning controls for FPGA load/store operations — we can explicitly request that the implementation of a global memory access is configured in a certain way. We added placement controls for data with external memory banks (e.g., DDR channel) for tuning FPGA designs via FPGA memory channel. Key tuning controls for FPGA high performance pipelining are enabled with FPGA register.
Summary
Heterogeneity is here to stay. There is an increasing diversity of hardware options available, with many specializing in the pursuit of higher performance and performance-per-watt. This is a trend that will only increase the need for open, multivendor, and multiarchitecture programming models like SYCL.
We highlighted five new features in SYCL 2020 that help to fulfill its mission to enable portability and performance portability. With SYCL 2020, C++ programmers can fully use the potential of heterogeneous computing.
We invite you to sycl.tech to learn more. There you will find numerous online tutorials, a link for our SYCL book (available as a free PDF), and a link to the latest SYCL specification.
Winning the NeurIPS BillionScale Approximate Nearest Neighbor Search Challenge
Read
Accelerating the 2D Fourier Correlation Algorithm with ArrayFire and oneAPI
Read
The Maxloc Reduction in oneAPI
Read
More Productive and Performant C++ Programming with oneDPL
Read
Optimizing Artificial Intelligence Applications
Read
Optimizing End-to-End Artificial Intelligence Pipelines
Read