Developer Guide for Intel® SDK for OpenCL™ Applications 2017
ID
773042
Date
10/22/2018
Public
A newer version of this document is available. Customers should click here to go to the newest version.
Legal Information
Getting Help and Support
Introducing the Intel® SDK for OpenCL™ Applications
What's New in This Release
Which Version of the Intel® SDK for OpenCL™ Applications Should I Use?
Intel® Code Builder for OpenCL™ API Plug-in for Microsoft Visual Studio*
Intel® Code Builder for OpenCL™ API Plug-in for Eclipse*
Debugging OpenCL™ Kernels on GPU
Intel® SDK for OpenCL™ Applications Standalone Version
OpenCL™ 2.1 Development Environment
Intel® FPGA Emulation Platform for OpenCL™ Getting Started Guide
Troubleshooting Intel® SDK for OpenCL™ Applications Issues
Configuring Microsoft Visual Studio* IDE
Converting an Existing Project into an OpenCL™ Project
OpenCL™ New Project Wizard
Building an OpenCL™ Project
Using OpenCL™ Build Properties
Selecting a Target OpenCL™ Device
Generating and Viewing Assembly Code
Generating and Viewing LLVM Code
Generating Intermediate Program Binaries with Intel® Code Builder for OpenCL™ API Plug-in
Configuring OpenCL™ Build Options
Host-Side Analysis Optimization Tips
While you run the host-side performance analysis, the Code Analyzer identifies inefficient use of the OpenCL API. When the analysis is done, a TIPS screen appears, showing all the detected issues, each issue also has a short description.
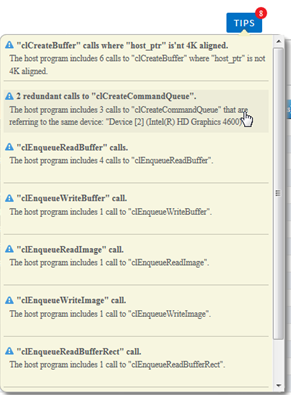
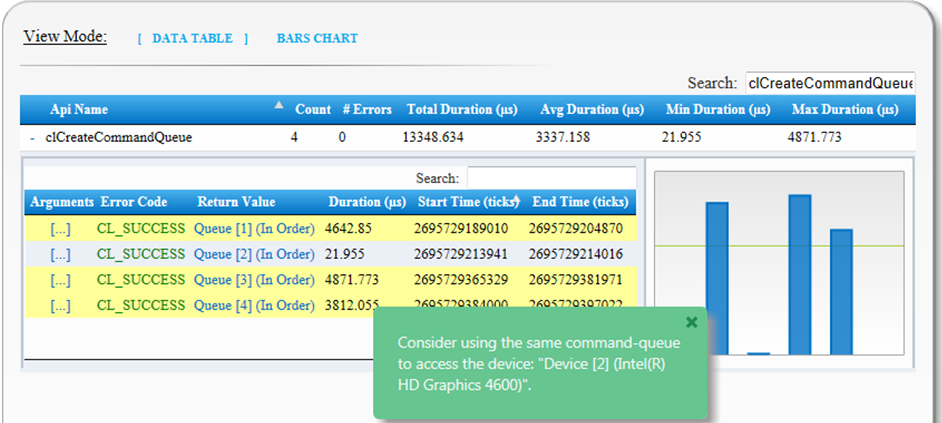
Click a specific tip to open a related report and highlight the data within the report which is relevant to this tip. In addition a popup window appears, with a recommendation how to fix the reported issue:
The following table summarizes the recommendations that are reported from the Tips.
| int Title | Description | Recommendation |
|---|---|---|
| Inefficient clCreateBuffer | The host program includes a call to clCreateBuffer, where flags includes CL_MEM_COPY_HOST_PTR. | There are two ways to ensure zero-copy path on memory objects mapping. For best results, allocate memory with CL_MEM_ALLOC_HOST_PTR, this method ensures that the memory is efficiently mirrored on the host. Another way is to allocate properly aligned and sized memory yourself and share the pointer with the OpenCL framework by using the CL_MEM_USE_HOST_PTR flag. |
| clCreateBuffer call where host_ptr is not 4K aligned. | The host program includes a call to clCreateBuffer where host_ptr is not 4K aligned. | For best results, align memory address to host memory page (4K bytes) |
| clCreateBuffer call where size is not a multiple of 64 bytes | The host program includes call to clCreateBuffer where size is not a multiple of 64 bytes. | For best results, make sure that the amount of memory you allocate and the size of the corresponding OpenCL buffer is a multiple of the cache line sizes (64 bytes). |
| Redundant calls to clBuildProgram | The host program includes several calls to clBuildProgram with the same arguments. | When possible, call clGetProgramInfo to retrieve binaries generated from calls to clCreateProgramWithSource and clBuildProgram. |
| Redundant calls to clCompileProgram | The host program includes several calls to clCompileProgram with the same arguments. | When possible, call clGetProgramInfo to retrieve previously compiled binaries. |
| Redundant calls to clCreateContextFromType. | The host program includes calls to clCreateContextFromType with the same arguments. | Consider using the same OpenCL context instead of recreating it. |
| Redundant calls to clCreateContext. | The host program includes calls to clCreateContext with the same arguments. | Consider using the same OpenCL context instead of recreating it. |
| Redundant calls to clCreateCommandQueue | The host program includes several calls to clCreateCommandQueue that refer to the same device | Consider using the same command-queue to access the device. |
| Redundant calls to clCreateCommandQueueWithProperties | The host program includes several calls to clCreateCommandQueueWithProperties that refer to the same device. | Consider using the same command-queue to access the device. |
| clEnqueueReadBuffer call | The host program includes several calls to clEnqueueReadBuffer | When possible, use clEnqueueMapBuffer and clEnqueueUnmapMemObject instead of calls to clEnqueueReadBuffer or clEnqueueWriteBuffer. |
| clEnqueueWriteBuffer call | The host program includes several calls to clEnqueueWriteBuffer | When possible, use clEnqueueMapBuffer and clEnqueueUnmapMemObject instead of calls to clEnqueueReadBuffer or clEnqueueWriteBuffer. |
| clEnqueueReadImage call | The host program includes several calls to clEnqueueReadImage | When possible, use clEnqueueMapImage and clEnqueueUnmapMemObject instead of calls to clEnqueueReadImage or clEnqueueWriteImage. |
| clEnqueueWriteImage call | The host program includes several calls to clEnqueueWriteImage | When possible, use clEnqueueMapImage and clEnqueueUnmapMemObject instead of calls to clEnqueueReadImage or clEnqueueWriteImage. |
| clEnqueueReadBufferRect call | The host program includes several calls to clEnqueueReadBufferRect | When possible, use clEnqueueMapBuffer and clEnqueueUnmapMemObject instead of calls to clEnqueueReadBufferRect or clEnqueueWriteBufferRect. |
| clEnqueueWriteBufferRect call | The host program includes several calls to clEnqueueWriteBufferRect | When possible, use clEnqueueMapBuffer and clEnqueueUnmapMemObject instead of calls to clEnqueueReadBufferRect or clEnqueueWriteBufferRect. |
| The work-group dimensions are defined as "column" work-group | The host program includes a call to clEnqueueNDRange where the work-group dimensions are defined as "column" work-group. | When reading from memory, best to reorganize the work-group to read in lines instead of columns. |
| Performance Information | Kernel register pressure is too high, spill fills will be generated. Additional surface needs to be allocated. | Consider simplifying your kernel. |
| Performance Information | Kernel private memory usage is too high and exhaust register space. Additional surface needs to be allocated. | Consider reducing the amount of private memory used, avoid using private memory arrays. |
| Performance Information | Local workgroup sizes selected for this workload may not be optimal | consider using a different local workgroup size, |
| Performance Information | Not aligned surface detected. Driver needs to disable L3 caching. | |
| Performance Information | Kernel submission requires coherency with CPU, this may impact performance. | |
| Performance Information | Null local workgroup size detected, Following sizes will be used for execution |