Developer Reference for Intel® oneAPI Math Kernel Library for Fortran
A newer version of this document is available. Customers should click here to go to the newest version.
oneMKL PARDISO - Parallel Direct Sparse Solver Interface
This section describes the interface to the shared-memory multiprocessing parallel direct sparse solver known as the Intel® oneAPI Math Kernel Library (oneMKL) PARDISO solver.
The Intel® oneAPI Math Kernel Library (oneMKL) PARDISO package is a high-performance, robust, memory efficient, and easy to use software package for solving large sparse linear systems of equations on shared memory multiprocessors. The solver uses a combination of left- and right-looking Level-3 BLAS supernode techniques [Schenk00-2]. To improve sequential and parallel sparse numerical factorization performance, the algorithms are based on a Level-3 BLAS update and pipelining parallelism is used with a combination of left- and right-looking supernode techniques [Schenk00, Schenk01, Schenk02, Schenk03]. The parallel pivoting methods allow complete supernode pivoting to compromise numerical stability and scalability during the factorization process. For sufficiently large problem sizes, numerical experiments demonstrate that the scalability of the parallel algorithm is nearly independent of the shared-memory multiprocessing architecture.
Product and Performance Information |
|---|
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex. Notice revision #20201201 |
The following table lists the names of the Intel® oneAPI Math Kernel Library (oneMKL) PARDISO routines and describes their general use.
| Routine | Description |
|---|---|
| pardisoinit | Initializes Intel® oneAPI Math Kernel Library (oneMKL) PARDISO with default parameters depending on the matrix type. |
| pardiso | Calculates the solution of a set of sparse linear equations with single or multiple right-hand sides. |
| pardiso_64 | Calculates the solution of a set of sparse linear equations with single or multiple right-hand sides, 64-bit integer version. |
| mkl_pardiso_pivot | Replaces routine which handles Intel® oneAPI Math Kernel Library (oneMKL) PARDISO pivots with user-defined routine. |
| pardiso_getdiag | Returns diagonal elements of initial and factorized matrix. |
| pardiso_export | Places pointers dedicated for sparse representation of requested matrix into MKL PARDISO. |
| pardiso_handle_store | Store internal structures from pardiso to a file. |
| pardiso_handle_restore | Restore pardiso internal structures from a file. |
| pardiso_handle_delete | Delete files with pardiso internal structure data. |
| pardiso_handle_store_64 | Store internal structures from pardiso_64 to a file. |
| pardiso_handle_restore_64 | Restore pardiso_64 internal structures from a file. |
| pardiso_handle_delete_64 | Delete files with pardiso_64 internal structure data. |
The Intel® oneAPI Math Kernel Library (oneMKL) PARDISO solver supports a wide range of real and complex sparse matrix types (seethe figure below).
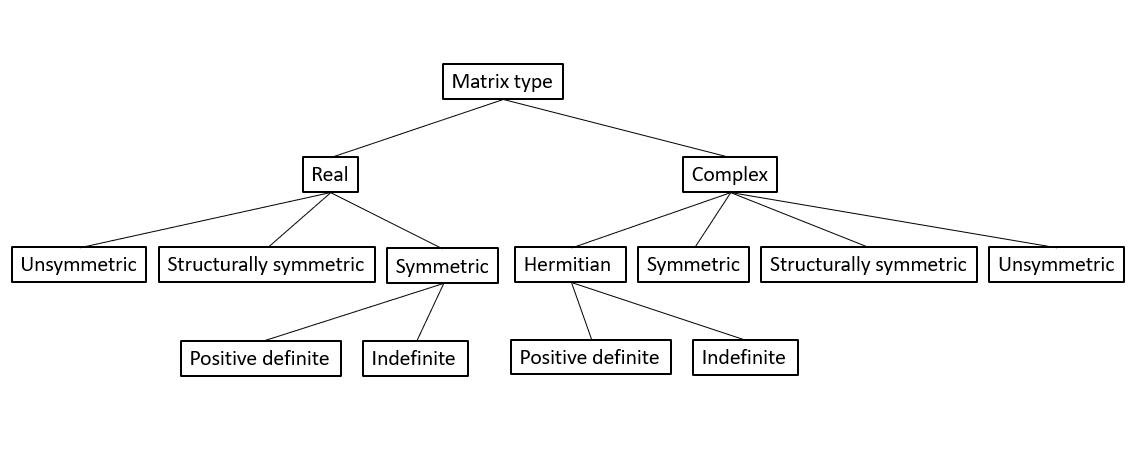
The Intel® oneAPI Math Kernel Library (oneMKL) PARDISO solver performs four tasks:
- analysis and symbolic factorization
- numerical factorization
- forward and backward substitution including iterative refinement
- termination to release all internal solver memory.
To find code examples that use Intel® oneAPI Math Kernel Library (oneMKL) PARDISO routines to solve systems of linear equations, unzip theappropriate Fortran archive file in the examplesfolder of the Intel® oneAPI Math Kernel Library (oneMKL) installation directory. Code examples will be in theexamples/solverf/source folder.
Supported Matrix Types
The analysis steps performed by Intel® oneAPI Math Kernel Library (oneMKL) PARDISO depend on the structure of the input matrixA.
- Symmetric Matrices
-
The solver first computes a symmetric fill-in reducing permutation P based on either the minimum degree algorithm [Liu85] or the nested dissection algorithm from the METIS package [Karypis98] (both included with Intel® oneAPI Math Kernel Library (oneMKL)), followed by the parallel left-right looking numerical Cholesky factorization [Schenk00-2] of PAPT = LLT for symmetric positive-definite matrices, or PAPT = LDLT for symmetric indefinite matrices. The solver uses diagonal pivoting, or 1x1 and 2x2 Bunch-Kaufman pivoting for symmetric indefinite matrices. An approximation of X is found by forward and backward substitution and optional iterative refinement.
Whenever numerically acceptable 1x1 and 2x2 pivots cannot be found within the diagonal supernode block, the coefficient matrix is perturbed. One or two passes of iterative refinement may be required to correct the effect of the perturbations. This restricting notion of pivoting with iterative refinement is effective for highly indefinite symmetric systems. Furthermore, for a large set of matrices from different applications areas, this method is as accurate as a direct factorization method that uses complete sparse pivoting techniques [Schenk04].
Another method of improving the pivoting accuracy is to use symmetric weighted matching algorithms. These algorithms identify large entries in the coefficient matrix A that, if permuted close to the diagonal, permit the factorization process to identify more acceptable pivots and proceed with fewer pivot perturbations. These algorithms are based on maximum weighted matchings and improve the quality of the factor in a complementary way to the alternative of using more complete pivoting techniques.
The inertia is also computed for real symmetric indefinite matrices.
- Structurally Symmetric Matrices
-
The solver first computes a symmetric fill-in reducing permutation P followed by the parallel numerical factorization of PAPT = QLUT. The solver uses partial pivoting in the supernodes and an approximation of X is found by forward and backward substitution and optional iterative refinement.
- Nonsymmetric Matrices
-
The solver first computes a nonsymmetric permutation PMPS and scaling matrices Dr and Dc with the aim of placing large entries on the diagonal to enhance reliability of the numerical factorization process [Duff99]. In the next step the solver computes a fill-in reducing permutation P based on the matrix PMPSA + (PMPSA)T followed by the parallel numerical factorization
QLUR = PPMPSDrADcP
with supernode pivoting matrices Q and R. When the factorization algorithm reaches a point where it cannot factor the supernodes with this pivoting strategy, it uses a pivoting perturbation strategy similar to [Li99]. The magnitude of the potential pivot is tested against a constant threshold of
alpha = eps*||A2||inf,
where eps is the machine precision, A2 = P*PMPS*Dr*A*Dc*P, and ||A2||inf is the infinity norm of A. Any tiny pivots encountered during elimination are set to the sign (lII)*eps*||A2||inf, which trades off some numerical stability for the ability to keep pivots from getting too small. Although many failures could render the factorization well-defined but essentially useless, in practice the diagonal elements are rarely modified for a large class of matrices. The result of this pivoting approach is that the factorization is, in general, not exact and iterative refinement may be needed.
Sparse Data Storage
Intel® oneAPI Math Kernel Library (oneMKL) PARDISO stores sparse data in several formats:
CSR3: The 3-array variation of the compressed sparse row format described in Three Array Variation of CSR Format.
BSR3: The three-array variation of the block compressed sparse row format described in Three Array Variation of BSR Format. Use iparm(37) to specify the block size.
VBSR: Variable BSR format. Intel® oneAPI Math Kernel Library (oneMKL) PARDISO analyzes the matrix provided in CSR3 format and converts it into an internal structure which can improve performance for matrices with a block structure. Useiparm(37) = -t (0 < t≤ 100) to specify use of internal VBSR format and to set the degree of similarity required to combine elements of the matrix. For example, if you set iparm(37) = -80, two rows of the input matrix are combined when their non-zero patterns are 80% or more similar.
NOTE:Intel® oneAPI Math Kernel Library (oneMKL) supports only the VBSR format for real and symmetric positive definite or indefinite matrices (mtype = 2 or mtype = -2).
Intel® oneAPI Math Kernel Library (oneMKL) supports these features for all matrix types as long asiparm(24)=1:
iparm(31) > 0: Partial solution
iparm(36) > 0: Schur complement
iparm(60) > 0: OOC Intel® oneAPI Math Kernel Library (oneMKL) PARDISO
For all storage formats, the Intel® oneAPI Math Kernel Library (oneMKL) PARDISO parameterja is used for the columns array, ia is used for rowIndex, and a is used for values. The algorithms in Intel® oneAPI Math Kernel Library (oneMKL) PARDISO require column indicesja to be in increasing order per row and that the diagonal element in each row be present for any structurally symmetric matrix. For symmetric or nonsymmetric matrices the diagonal elements which are equal to zero are not necessary.
Intel® oneAPI Math Kernel Library (oneMKL) PARDISO column indicesja must be in increasing order per row. You can validate the sparse matrix structure with the matrix checker (iparm(27))
While the presence of zero diagonal elements for symmetric matrices is not required, you should explicitly set zero diagonal elements for symmetric matrices. Otherwise, Intel® oneAPI Math Kernel Library (oneMKL) PARDISO creates internal copies of arraysia, ja, and a full of diagonal elements, which require additional memory and computational time. However, the memory and time required the diagonal elements in internal arrays is usually not significant compared to the memory and the time required to factor and solve the matrix.
Product and Performance Information |
|---|
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex. Notice revision #20201201 |
Storage of Matrices
By default, Intel® oneAPI Math Kernel Library (oneMKL) PARDISO stores data in RAM. This is referred to as In-Core (IC) mode. However, you can specify that Intel® oneAPI Math Kernel Library (oneMKL) PARDISO store matrices on disk by settingiparm(60). This mode is called the Out-of-Core (OOC) mode.
You can set the following parameters for the OOC mode.
| Parameter/Environment Variable Name | Description |
|---|---|
| MKL_PARDISO_OOC_PATH | Directory for storing data created in the OOC mode. |
| MKL_PARDISO_OOC_FILE_NAME | Full file name (incl. path) which will be used for the OOC files |
| MKL_PARDISO_OOC_MAX_CORE_SIZE | Maximum size of RAM (in megabytes) available for Intel® oneAPI Math Kernel Library (oneMKL) PARDISO |
| MKL_PARDISO_OOC_MAX_SWAP_SIZE | Maximum swap size (in megabytes) available for Intel® oneAPI Math Kernel Library (oneMKL) PARDISO |
| MKL_PARDISO_OOC_KEEP_FILE | A flag which determines whether temporary data files will be deleted or stored |
By default, the current working directory is used in the OOC mode as a directory path for storing data. All work arrays will be stored in files named ooc_temp with different extensions. When MKL_PARDISO_OOC_FILE_NAME is not set and MKL_PARDISO_OOC_PATH is set, the names for the created files will contain <path>/mkl_pardiso or <path>\mkl_pardiso depending on the OS. Setting MKL_PARDISO_OOC_FILE_NAME=<filename> will override the path which could have been set in MKL_PARDISO_OOC_PATH. In this case <filename> will be used for naming the OOC files.
By default, MKL_PARDISO_OOC_MAX_CORE_SIZE is 2000 (MB) and MKL_PARDISO_OOC_MAX_SWAP_SIZE is 0.
Do not set the sum of MKL_PARDISO_OOC_MAX_CORE_SIZE and MKL_PARDISO_OOC_MAX_SWAP_SIZE greater than the size of the RAM plus the size of the swap memory. Be sure to allow enough free memory for the operating system and any other processes which need to be running.
By default, all temporary data files will be deleted. For keeping them it is required to set MKL_PARDISO_OOC_KEEP_FILE to 0.
OOC parameters can be set in a configuration file. You can set the path to this file and its name using environmental variables MKL_PARDISO_OOC_CFG_PATH and MKL_PARDISO_OOC_CFG_FILE_NAME.
For setting parameters of OOC mode either environment variables or a configuration file can be used. When the last option is chosen, by default the name of the file is pardiso_ooc.cfg and it should be placed in the working directory. If needed, the user can set the path to the configuration file using environmental variables MKL_PARDISO_OOC_CFG_PATH and MKL_PARDISO_OOC_CFG_FILE_NAME. These variables specify the path and filename as follows:
- Linux* OS and OS X*: <MKL_PARDISO_OOC_CFG_PATH>/ <MKL_PARDISO_OOC_CFG_FILE_NAME>
- Windows* OS: <MKL_PARDISO_OOC_CFG_PATH>\<MKL_PARDISO_OOC_CFG_FILE_NAME>
An example of the configuration file:
MKL_PARDISO_OOC_PATH = <path> MKL_PARDISO_OOC_MAX_CORE_SIZE = N MKL_PARDISO_OOC_MAX_SWAP_SIZE = K MKL_PARDISO_OOC_KEEP_FILE = 0 (or 1)
The maximum length of the path lines in the configuration files is 1000 characters.
Alternatively, the OOC parameters can be set as environment variables via command line.
For Linux* OS and OS X*:
export MKL_PARDISO_OOC_PATH = <path> export MKL_PARDISO_OOC_MAX_CORE_SIZE = N export MKL_PARDISO_OOC_MAX_SWAP_SIZE = K export MKL_PARDISO_OOC_KEEP_FILE = 0 (or 1)
For Windows* OS:
set MKL_PARDISO_OOC_PATH = <path> set MKL_PARDISO_OOC_MAX_CORE_SIZE = N set MKL_PARDISO_OOC_MAX_SWAP_SIZE = K set MKL_PARDISO_OOC_KEEP_FILE = 0 (or 1)
where <path> should follow the OS naming convention.
Direct-Iterative Preconditioning for Nonsymmetric Linear Systems
The solver uses a combination of direct and iterative methods [Sonn89] to accelerate the linear solution process for transient simulation. Most applications of sparse solvers require solutions of systems with gradually changing values of the nonzero coefficient matrix, but with an identical sparsity pattern. In these applications, the analysis phase of the solvers has to be performed only once and the numerical factorizations are the important time-consuming steps during the simulation. Intel® oneAPI Math Kernel Library (oneMKL) PARDISO uses a numerical factorization and applies the factors in a preconditioned Krylov Subspace iteration. If the iteration does not converge, the solver automatically switches back to the numerical factorization. This method can be applied to nonsymmetric matrices in Intel® oneAPI Math Kernel Library (oneMKL) PARDISO. You can select the method using theiparm(4) input parameter. The iparm(20)parameter returns the error status after running Intel® oneAPI Math Kernel Library (oneMKL) PARDISO.
Single and Double Precision Computations
Intel® oneAPI Math Kernel Library (oneMKL) PARDISO solves tasks using single or double precision. Each precision has its benefits and drawbacks. Double precision variables have more digits to store value, so the solver uses more memory for keeping data. But this mode solves matrices with better accuracy, which is especially important for input matrices with large condition numbers.
Single precision variables have fewer digits to store values, so the solver uses less memory than in the double precision mode. Additionally this mode usually takes less time. But as computations are made less precisely, only some systems of equations can be solved accurately enough using single precision.
Separate Forward and Backward Substitution
The solver execution step (see parameterphase = 33 below) can be divided into two or three separate substitutions: forward, backward, and possible diagonal. This separation can be explained by the examples of solving systems with different matrix types.
A real symmetric positive definite matrix A (mtype = 2) is factored by Intel® oneAPI Math Kernel Library (oneMKL) PARDISO asA = L*LT . In this case the solution of the system A*x=b can be found as sequence of substitutions: L*y=b (forward substitution, phase =331) andLT*x=y (backward substitution, phase =333).
A real nonsymmetric matrix A (mtype = 11) is factored by Intel® oneAPI Math Kernel Library (oneMKL) PARDISO asA = L*U . In this case the solution of the system A*x=b can be found by the following sequence: L*y=b (forward substitution, phase =331) andU*x=y (backward substitution, phase =333).
Solving a system with a real symmetric indefinite matrix A (mtype = -2) is slightly different from the cases above. Intel® oneAPI Math Kernel Library (oneMKL) PARDISO factors this matrix asA=LDLT, and the solution of the system A*x=b can be calculated as the following sequence of substitutions: L*y=b (forward substitution, phase =331), D*v=y (diagonal substitution, phase =332), and finally LT*x=v (backward substitution, phase =333). Diagonal substitution makes sense only for symmetric indefinite matrices (mtype = -2, -4, 6). For matrices of other types a solution can be found as described in the first two examples.
The number of refinement steps (iparm(8)) must be set to zero if a solution is calculated with separate substitutions (phase = 331, 332, 333), otherwise Intel® oneAPI Math Kernel Library (oneMKL) PARDISO produces the wrong result.
Different pivoting (iparm(21)) produces different LDLT factorization. Therefore results of forward, diagonal and backward substitutions with diagonal pivoting can differ from results of the same steps with Bunch-Kaufman pivoting. Of course, the final results of sequential execution of forward, diagonal and backward substitution are equal to the results of the full solving step (phase=33) regardless of the pivoting used.
Callback Function for Pivoting Control
In-core Intel® oneAPI Math Kernel Library (oneMKL) PARDISO allows you to control pivoting with a callback routine,mkl_pardiso_pivot. You can then use the pardiso_getdiag routine to access the diagonal elements. Set iparm(56) to 1 in order to use the callback functionality.
Low Rank Update
Use low rank update to accelerate the factorization step in Intel® oneAPI Math Kernel Library (oneMKL) PARDISO when you use multiple matrices with identical structure and similar values. After callingpardiso in the usual manner for factorization (phase = 12, 13, 22, or 23) for some matrix A1, low rank update can be applied to the factorization step (phase = 22 or 23) of some matrix A2 with identical structure.
To use the low rank update feature, set iparm(39) = 1 while also setting iparm(24) = 10. Additionally, supply an array that lists the values in A2 that are different from A1 using the perm parameter as outlined in the pardiso perm parameter description.
Low rank update can only be called for matrices with the exact same pattern of nonzero values. As such, the value of the mtype, ia, ja, and iparm(24) parameters should also be identical. In general, the low rank factorization should be called with the same parameters as the preceding factorization step for the same internal data structure handle (except for array a, iparm(39), and perm).
Low rank update does not currently support Intel TBB threading. In this case, Intel® oneAPI Math Kernel Library (oneMKL) PARDISO defaults to full factorization instead.
Low rank update cannot be used in combination with a user-supplied permutation vector - in other words, you must use the default values of iparm(5) = 0, iparm(31) = 0, and iparm(36) = 0). Additionally, iparm(4), iparm(6), iparm(12), iparm(28), iparm(37), iparm(56), and iparm(60) must all be set to the default value of 0.
- pardiso
Calculates the solution of a set of sparse linear equations with single or multiple right-hand sides. - pardisoinit
Initialize Intel® oneAPI Math Kernel Library (oneMKL) PARDISO with default parameters in accordance with the matrix type. - pardiso_64
Calculates the solution of a set of sparse linear equations with single or multiple right-hand sides, 64-bit integer version. - mkl_pardiso_pivot
Replaces routine which handles Intel® oneAPI Math Kernel Library (oneMKL) PARDISO pivots with user-defined routine. - pardiso_getdiag
Returns diagonal elements of initial and factorized matrix. - pardiso_export
Places pointers dedicated for sparse representation of a requested matrix (values, rows, and columns) into MKL PARDISO - pardiso_handle_store
Store internal structures from pardiso to a file. - pardiso_handle_restore
Restore pardiso internal structures from a file. - pardiso_handle_delete
Delete files with pardiso internal structure data. - pardiso_handle_store_64
Store internal structures from pardiso_64 to a file. - pardiso_handle_restore_64
Restore pardiso_64 internal structures from a file. - pardiso_handle_delete_64
- oneMKL PARDISO Parameters in Tabular Form
- pardiso iparm Parameter
- PARDISO_DATA_TYPE