Developer Reference for Intel® oneAPI Math Kernel Library for Fortran
A newer version of this document is available. Customers should click here to go to the newest version.
?getrf_batch_strided
Computes the LU factorization of a group of general m-by-n matrices that are stored at a constant stride from each other in a contiguous block of memory.
Syntax
call sgetrf_batch_strided(m, n, A, lda, stride_a, ipiv, stride_ipiv, batch_size, info)
call dgetrf_batch_strided(m, n, A, lda, stride_a, ipiv, stride_ipiv, batch_size, info)
call cgetrf_batch_strided(m, n, A, lda, stride_a, ipiv, stride_ipiv, batch_size, info)
call zgetrf_batch_strided(m, n, A, lda, stride_a, ipiv, stride_ipiv, batch_size, info)
Include Files
mkl.fi
Description
The ?getrf_batch_strided routines are similar to the ?getrf counterparts, but instead compute the LU factorization for a group of general m-by-n matrices.
All matrices have the same parameters (matrix size, leading dimension) and are stored at constant stride_a from each other in a contiguous block of memory. Their respective pivot arrays associated with each of the LU-factored Ai matrices are stored at constant stride_ipiv from each other. The operation is defined as
for i = 0 … batch_size-1 Ai is a matrix at offset i * stride_a from A ipivi is an array at offset i * stride_ipiv from ipiv Ai := Pi * Li* Ui end for
where Pi is a permutation matrix, Li is lower triangular with unit diagonal elements (lower trapezoidal if m> n) and Ui is upper triangular (upper trapezoidal if m< n). The routine uses partial pivoting, with row interchanges.
Input Parameters
- m
-
INTEGER. The number of rows in the A matrices: m ≥ 0.
- n
-
INTEGER. The number of columns in the A matrices: n ≥ 0.
- A
-
REAL for sgetrf_batch_strided
DOUBLE PRECISION for dgetrf_batch_strided
COMPLEX for cgetrf_batch_strided
DOUBLE COMPLEX for zgetrf_batch_strided
The A array of size at least stride_a * batch_size holding the Ai matrices.
- lda
-
INTEGER. Specifies the leading dimension of the Ai matrices; lda ≥ max(1,m).
- stride_a
-
INTEGER.
Stride between two consecutive Ai matrices; stride_a ≥ lda * n.
- stride_ipiv
-
INTEGER.
Stride between two consecutive pivot arrays; stride_ipiv ≥ min(m, n).
- batch_size
-
INTEGER.
Number of Ai matrices to be factorized. Must be at least 0.
Output Parameters
- A
-
Array holding the LU-factored Ai matrices. Each matrix is overwritten by their respective Li and Ui factors. The unit diagonal elements of L are not stored.
- ipiv
-
INTEGER
Array of size at least stride_ipiv * batch_size holding the pivot array associated with each of the LU-factored Ai matrices. The pivot array ipivi contains the pivot indices associated with matrix Ai; for 1 ≤ j ≤ min(m,n), row j was interchanged with row ipivi(j).
- info
-
INTEGER.
Array of size at least batch_size, which reports the factorization status for each matrix.
If info(i) = 0, the execution is successful for Ai.
If info(i) = -j, the j-th parameter had an illegal value for Ai.
If info(i) = j, the j-th diagonal element of Ui is 0. The factorization has been completed, but Ui is exactly singular. Division by 0 will occur if you use the factor Ui for solving a system of linear equations.
After calling this routine with m=n, you can call the following:
to solve systems of linear equations of the form 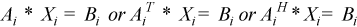 with the group of LU-factored matrices.
with the group of LU-factored matrices.
Related Information
See ?getrf_batch, which computes the LU factorization for a group of general m-by-n matrices that are allocated at a constant stride from each other in the same contiguous block of memory.