A newer version of this document is available. Customers should click here to go to the newest version.
Examine Not-Vectorized and Under-Vectorized Loops
Accuracy Level
Low
Enabled Analyses
Survey
Result Interpretation
After running the Vectorization and Code Insights perspective with Low accuracy, you get a basic vectorization report, which shows not-vectorized and under-vectorized loops, and other performance issues.
In the Survey report:
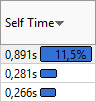
Sort by the Self-Time and/or Total-Time column to find top time-consuming loops.
Check whether your target loop or function is vector or scalar. Intel Advisor helps you to differentiate vector and scalar using the following icons:
 - vectorized function
- vectorized function  - vectorized loop
- vectorized loop  - scalar function
- scalar function  - scalar loop
- scalar loop
Use filters to hide the code sides that you do not want to tweak now:
 and
and 
Decide what loops or functions to investigate:
If loop/function is scalar
If loop/function is vectorized
If Loop/Function is Scalar
If the target loop/function is scalar ( or ), you need to understand why the compiler did not vectorize the loop/function.
Several reasons are possible:
See OpenMP* Pragmas Summary in the Intel® oneAPI DPC++/C++ Compiler Developer Guide and Reference for more information about the directives mentioned below.
| Possible Reason | To Confirm | To Do |
|---|---|---|
Assumed dependency |
Refer to Why No Vectorization? column. Search for Vector dependence prevents vectorization issue. |
Run the Dependencies analysis.
|
Function call in the loop |
Refer to Why No Vectorization? column. Search for issues:
|
For issue: Function call present, do one of the following:
For issues Indirect function call present or Serialized user function call present, refer to guidelines in the Recommendations tab. |
Compiler-assumed inefficient vectorization |
Refer to Why No Vectorization? column. Search for the Loop vectorization possible but seems inefficient issue. |
Try forcing vectorization with the omp simd directive. If forcing vectorization doesn't provide tangible results, consider experimenting with other directives. To better understand performance implications and potential speed-up, consider running additional analyses:
|
Other |
Refer to
|
Study the Compiler Diagnostic Details and Advisor Recommendations to resolve the issues. |
If Loop/Function is Vectorized
If the target loop is vectorized ( or ), ensure vector efficiency is above 90%.
If efficiency is below 90%, consider the following:
| Possible Reason | To Confirm | To Do |
|---|---|---|
ISA |
Refer to Vectorized Loops/Vector ISA column to check the ISA version used in the application. |
Change the target ISA by specifying corresponding compiler flags. |
Inefficient peel/remainder |
Refer to Vector Issues column. Search for the Inefficient Peel/Reminder issue. Or check if the time spent in peel/reminder is significant. |
Resolve the issues:
|
Possible inefficient memory access |
Refer to Vector Issues column. Search for the Possible Inefficient Memory Access issue. Refer to Instruction Set Analysis/Traits column. Search for the following traits:
|
Run the Memory Access Patterns analysis. |
Type conversions present |
Refer to Instruction Set Analysis/Traits column. Search for the Type Conversions metric. |
Remove redundant type conversions from float to double that might lead to smaller vector length and reduced vectorization efficiency. |
Unaligned vector access in loop |
Refer to Advanced/Vectorization Details column. Search for the Unaligned access in vector loop metric. |
Align data. |
Register pressure |
Refer to Vector Issues column. Search for the Vector register spilling possible issue. |
Resolve the issue by doing one of the following:
|
Potential underutilization of FMA instructions |
Refer to Vector Issues column. Search for the Potential underutilization of FMA instructions issue. |
Resolve the issue by doing one of the following:
|
Other |
Refer to Vector Issues column. |
Follow the Intel Advisor recommendations to resolve the issues. |