Introduction
Modern CPU and GPU cores use single instruction, multiple data (SIMD) execution units to achieve higher performance and power efficiency. The underlying SIMD hardware is exposed via instructions such as SSE, AVX, AVX2, AVX-512, and those in the Intel® Xe Architecture Gen12 ISA. While using these directly is an option, their low-level nature severely limits portability and proves unattractive for most projects.
To provide a more portable and easier to use interface for programmers, three avenues are explored in this article: auto-vectorization, programmer-guided SIMD vectorization through language constructs or programmer hints, and a SIMD data-parallel library approach. We provide an overview of these methods and show SIMD vectorization evolution in the LLVM and GCC compilers through code examples. We also examine a couple of vectorization techniques in the LLVM and GCC compilers to achieve optimal performance on Intel® Xeon® processors and Intel Xe Architecture GPUs.
Enhancing LLVM and GCC
Our goal is to enhance vectorization of both the LLVM and GCC compilers, so contributing to open source has been a key design consideration. The VPlan vectorizer, and the related VectorABI, have been designed so they are applicable for integration into both LLVM and GCC [13] optimizers.
The framework for the VPlan vectorizer may be integrated into the LLVM trunk. Our VectorABI [12] is published and is being utilized by the LLVM and GCC communities for function vectorization. The VPlan vectorizer has started to surpass the results previously provided by the proprietary Intel compilers for Intel Xeon processors.
Utilizing SIMD
Modern CPUs support SIMD execution. SIMD is a hardware feature for a wavefront parallel execution of a single instruction over multiple data elements. It is useful for operating on multiple pieces of data at once given that their control flow is similar (minimal vector divergence) and the operation is not memorybound. Unfortunately, writing a program that directly uses the SIMD ISA is not straightforward and has limited portability. We will discuss three approaches to improve this situation for programmers: autovectorization, programmer-guided SIMD vectorization through hints or language constructs, and using the C++ SIMD data-parallel library.
Auto-Vectorization
Automatically performing data- and control-dependency analysis and converting a scalar program to a corresponding vector form based on a built-in cost model is called auto-vectorization [4][5]. While the simplicity of this approach is attractive to programmers for its productivity and portability, autovectorization does not always produce optimal code because of compile-time unknowns like loop bounds and memory access patterns.
Programmer-Guided SIMD Vectorization
OpenMP (version 4.0 and later) includes SIMD constructs to support vector-level parallelism [7]. These constructs provide a standardized set of vector constructs so programmers no longer need to use nonportable, vendor-specific intrinsics or directives [6]. In addition, these constructs provide additional hints about the code structure to the compiler and allow for better vectorization that blends well with parallelization [5].
C++ SIMD Data-Parallel Library
There is an ISO C++ proposal for a data-parallel library [3]. Its intent is to support acceleration through data-parallel execution resources such as SIMD registers and instructions or execution units driven by a common instruction decoder. If such execution resources are unavailable, the interfaces support a transparent fallback to sequential execution. A SIMD memcpy example using the C++ SIMD data-parallel
library is shown in Figure 1. This example can be compiled to generate LLVM Vector IR and binary for coreavx512.
namespace stdsimd = std::experimental;
void simd_memcpy(
stdsimd::native_simd<float> x,
stdsimd::native_simd<float> y,
void *p)
{
auto cmp = x < y;
memcpy(p, &cmp, cmp.size()*4);
}
define void @_Z11simd_memcpy_Pv(<16 x float> %x.coerce,
<16 x float> %y.coerce, i8*
nocapture %p)
{
entry:
%0 = fcmp fast olt <16 x float> %x.coerce, %y.coerce
%cmp.sroa.0.sroa.0.0.p.sroa_cast = bitcast i8* %p to <16 x i1>*
store <16 x i1> %0, <16 x i1>* %cmp.sroa.0.sroa.0.0.p.sroa_cast
ret void
}
Figure 1. An example of the C++ SIMD data-parallel library
The SIMD vectorization is critical to delivering optimal performance of compute-intensive workloads on modern CPUs and GPUs regardless of which vectorization method is used to produce SIMD code. In the next sections, we present recent LLVM SIMD vectorization advances for CPUs and GPUs with more code examples.
LLVM VPlan Vectorization
VPlan Vectorizer
Intel LLVM Compiler introduces a newly designed loop vectorizer aimed at matching or exceeding the capability and performance of the vectorizer in Intel Classic Compiler. The new vectorizer is often referred to as VPlan Vectorizer after the name of its major internal data structure, VPlan (vectorization plan), to distinguish it from the LLVM community Loop Vectorizer (a.k.a. LV). LORE and RAJAPerf experiments show that Intel LLVM Compiler can generate equivalent or better performing code than Intel Classic Compiler for a variety of computational kernels extracted from HPC applications [9]. At the time of writing, Intel LLVM Compiler enables VPlan Vectorizer for auto-vectorization at -O2 or higher optimization plus the -x (/Qx for Windows) target flag. Without the -x flag, the community Loop Vectorizer will be used. VPlan Vectorizer is enabled at -O0 or higher for OpenMP SIMD when Intel’s OpenMP implementation is enabled with the -qopenmp (/Qopenmp for Windows) flag. At the time of writing, many of frequently used OpenMP 4.5 SIMD features are functional and performant. We continue our efforts to support the latest OpenMP 5.2 SIMD features.
Figure 2 shows how a simple outer loop (left column) is vectorized by Intel Classic Compiler (icc, center column) and Intel LLVM Compiler (icx, right column). Overall ASM code generated by Intel Classic Compiler looks more concise and easier to follow, but Intel LLVM Compiler generates noticeably better ASM code for the inner while-loop (basic block .LBB0_7 for icx versus ..B1.7 for icc) due to its better handling of the inner loop execution condition in the %k1 mask register.
void foo(int N, float *a,
float *b, float *c){
#pragma omp simd
for (int i=0;i<N;i++){
float x = a[i];
float y = b[i];
while(x>y){
x = x*x;
}
c[i] = x;
}
}
icc -O2 -qopenmp-simd -xCOREAVX512 -c -S -unroll0
..B1.5:
vmovups (%rsi,%r8,4), %ymm1
vmovups (%rdx,%r8,4), %ymm0
vcmpps $14, %ymm0, %ymm1, %k1
kortestw %k1, %k1
je ..B1.9
..B1.6:
kmovw %k1, %k0
..B1.7:
kandw %k0, %k1, %k2
vmulps %ymm1, %ymm1, %ymm1{%k2}
vcmpps $14, %ymm0, %ymm1, %k3
kandw %k3, %k2, %k4
kandw %k0, %k4, %k0
jne ..B1.7
..B1.9:
addl $8, %r9d
vmovups %ymm1, (%rcx,%r8,4)
addq $8, %r8
cmpl %eax, %r9d
jb ..B1.5
icx -O2 -qopenmp-simd -xCOREAVX512 -c -S -unroll0
jmp .LBB0_4
.LBB0_5:
vxorps %xmm2, %xmm2, %xmm2
.LBB0_8:
vcmpltps %ymm0, %ymm1, %k1
vmovaps %ymm2, %ymm0 {%k1}
vmovups %ymm0, (%rcx,%rax,4)
addq $8, %rax
cmpq %rdi, %rax
jae .LBB0_9
.LBB0_4:
vmovups (%rsi,%rax,4), %ymm0
vmovups (%rdx,%rax,4), %ymm1
vcmpltps %ymm0, %ymm1, %k0
kortestb %k0, %k0
je .LBB0_5
# %bb.6:
vmovaps %ymm0, %ymm3
kmovq %k0, %k1
.LBB0_7:
vmulps %ymm3, %ymm3, %ymm3
vmovaps %ymm3, %ymm2 {%k1}
vcmpltps %ymm3, %ymm1, %k1 {%k1}
ktestb %k0, %k1
jne .LBB0_7
jmp .LBB0_8
Figure 2. Outer loop vectorization using VPlan Vectorizer
Kernel and Function Vectorization
Intel LLVM Compiler implements DPC++/OpenCL kernel vectorization and OpenMP function vectorization through VPlan vectorizer [5][10]. This is accomplished by converting a function vectorization problem into a loop vectorization problem. Customers can expect that most of the optimizations implemented for vectorizing loops are also available to vectorizing kernels/functions.
Figure 3 is an equivalent vectorization expressed in OpenMP declare SIMD directive form [7]. An 8-way non-mask vectorized AVX-512 vector variant function (_ZGVcN8luuu_bar) is shown. Even though the basic block layout is different, and the outer loop control flow is naturally absent because the compiler knows it is vectorizing for “8-instances” of the function bar, the rest of the ASM code is strikingly similar to icx-generated ASM code in the loop vectorization example (Figure 2) because it is vectorized by the same VPlan Vectorizer by letting the compiler inject an 8-iteration loop around the function body.
#pragma omp declare simd \
linear(i) uniform(a,b,c)
void bar(int i, float *a, float *b, float *c){
float x = a[i];
float y = b[i];
while(x>y){
x = x*x;
}
c[i] = x;
}
icx -O2 -qopenmp-simd -xCORE-AVX512 -c -S -unroll0
_ZGVcN8luuu_bar:
movslq %edi, %rax
vmovups (%rsi,%rax,4), %ymm0
vmovups (%rdx,%rax,4), %ymm1
vcmpltps %ymm0, %ymm1, %k1
kortestb %k1, %k1
je .LBB3_1
# %bb.2:
vcmpltps %ymm0, %ymm1, %k0
vmovaps %ymm0, %ymm3
.LBB3_3:
vmulps %ymm3, %ymm3, %ymm3
vmovaps %ymm3, %ymm2 {%k1}
vcmpltps %ymm3, %ymm1, %k1 {%k1}
ktestb %k0, %k1
jne .LBB3_3
jmp .LBB3_4
.LBB3_1:
vxorps %xmm2, %xmm2, %xmm2
.LBB3_4:
vcmpltps %ymm0, %ymm1, %k1
vmovaps %ymm2, %ymm0 {%k1}
vmovups %ymm0, (%rcx,%rax,4)
vzeroupper
retq
Figure 3. Function vectorization example using VPlan Vectorizer
New ISA Support
One of the benefits of implementing a vectorizer on the LLVM compiler framework is first-class support of vector data types. When AVX-512-FP16 [11] was introduced, the vectorizer was able to take advantages of it as soon as the ASM/OBJ code generation support was added, giving vectorizer developers a pleasant surprise. Figure 4 is a simple FP16 vectorization example.
void foo(int N, __fp16 *a, __fp16 *b, __fp16 *c)
{
#pragma omp simd
for (int i=0;i<N;i++)
{
c[i] = a[i]+b[i];
}
}
icx -qopenmp-simd -O2 -xsapphirerapids -c -S -unroll0
.LBB0_3:
vmovups (%rdx,%rax,2), %ymm0
vaddph (%rsi,%rax,2), %ymm0, %ymm0
vmovups %ymm0, (%rcx,%rax,2)
addq $16, %rax
cmpq %rdi, %rax
jb .LBB0_3
Figure 4. FP16 vectorization example (I) using VPlan Vectorizer
Note that not all optimizers work well out-of-the-box for the newly introduced instruction set. Figure 5 is the same example from Figure 2 but using the FP16 data type. The innermost loop with the vmulph instruction is currently not as nicely optimized as in Figures 2 and 3. In the upcoming releases, we’ll continue uncovering and improving these issues.
void foo(int N, __fp16 *a, __fp16 *b, __fp16 *c)
{
#pragma omp simd
for (int i=0;i<N;i++)
{
__fp16 x = a[i];
__fp16 y = b[i];
while(x>y)
{
x = x*x;
}
c[i] = x;
}
}
icx -qopenmp-simd -O2 -xsapphirerapids -c -S -unroll0
jmp .LBB0_4
.LBB0_5:
vpxor %xmm2, %xmm2, %xmm2
.LBB0_12:
vcmpltph %ymm0, %ymm1, %k1
vmovdqu16 %ymm2, %ymm0 {%k1}
vmovdqu %ymm0, (%rcx,%rax,2)
addq $16, %rax
cmpq %rdi, %rax
jae .LBB0_13
.LBB0_4:
vmovups (%rsi,%rax,2), %ymm0
vmovups (%rdx,%rax,2), %ymm1
vcmpltph %ymm0, %ymm1, %k0
kortestw %k0, %k0
je .LBB0_5
# %bb.6:
vmovaps %ymm0, %ymm3
kmovq %k0, %k1
jmp .LBB0_7
.LBB0_11:
vmovdqu16 %ymm3, %ymm2 {%k1}
kandw %k1, %k2, %k1
ktestw %k0, %k1
je .LBB0_12
.LBB0_7:
ktestw %k1, %k0
vmulph %ymm3, %ymm3, %ymm4
vxorps %xmm3, %xmm3, %xmm3
je .LBB0_9
# %bb.8:
vmovaps %ymm4, %ymm3
.LBB0_9:
kxorw %k0, %k0, %k2
je .LBB0_11
# %bb.10:
vcmpltph %ymm4, %ymm1, %k2
jmp .LBB0_11
Figure 5. FP16 vectorization example (II) using VPlan Vectorizer
Enhancing Auto-Vectorization in GCC12
In this section, we describe several auto-vectorization enhancements developed recently for AVX-512/AVX-512-VNNI support in GCC12 compiler based on GCC vectorization framework previously done for Intel Xeon Phi processors.
- GCC12 auto-vectorization is enabled by default at -O2 using a “cheap” cost model, which permits loop vectorization if the trip count of a scalar vectorizable loop is a multiple of the hardware vector length, and with no observable code size increasing. For example, Figure 6 shows an example of GCC -O2 autovectorization using SSE4.2. Meanwhile, the default cost model for loop vectorization at -O3 employs a "dynamic" model with more checkpoints to determine whether the vectorized code path will achieve performance gains.
void ArrayAdd(int* __restrict a, int* b)
{
for (int i = 0; i != 32; i++)
a[i] += b[i];
}
ArrayAdd:
xorl %eax, %eax
.L2:
movdqu (%rdi,%rax), %xmm0
movdqu (%rsi,%rax), %xmm1
paddd %xmm1, %xmm0
movups %xmm0, (%rdi,%rax)
addq $16, %rax
cmpq $128, %rax
jne .L2
ret
Figure 6. GCC (-O2) auto-vectorization example
- GCC vectorization for the _Float16 type is enabled to generate corresponding AVX512FP16 instructions. In addition to those SIMD instructions that are similar to their float/double variants, the vectorizer also supports vectorization for the complex _Float16 type. Figure 7 shows an example that performs a conjugate complex multiply and accumulate operations on three arrays, and the vectorizable loop can be optimized to generate an vfcmaddcph instruction.
#include<complex.h>
void fmaconj (_Complex _Float16 a[restrict 16],
_Complex _Float16 b[restrict 16],
_Complex _Float16 c[restrict 16])
{
for (int i = 0; i < 16; i++)
c[i] += a[i] * ~b[i];
}
fmaconj:
vmovdqu16 (%rdx), %zmm1
vmovdqu16 (%rsi), %zmm0
vfcmaddcph (%rdi), %zmm1, %zmm0
vmovdqu16 %zmm0, (%rdx)
vzeroupper
ret
Figure 7. GCC auto-vectorization of using the AVX512FP16 vfcmaddcph instruction
- GCC auto-vectorization is enhanced to perform idiom recognition such as the dot-plus idiom, which triggers the AVX/AVX512VNNI instruction generation. Figure 8 shows that the compiler generates the vpdpbusd instruction plus a summation reduction.
int usdot_prod_qi (unsigned char * restrict a,
char *restrict b, int c, int n)
{
for (int i = 0; i < 32; i++)
{
c += ((int) a[i] * (int) b[i]);
}
return c;
}
usdot_prod_qi:
vmovdqu (%rdi), %ymm0
vpxor %xmm1, %xmm1, %xmm1
vpdpbusd (%rsi), %ymm0, %ymm1
vextracti128 $0x1, %ymm1, %xmm0
vpaddd %xmm1, %xmm0, %xmm0
vpsrldq $8, %xmm0, %xmm1
vpaddd %xmm1, %xmm0, %xmm0
vpsrldq $4, %xmm0, %xmm1
vpaddd %xmm1, %xmm0, %xmm0
vmovd %xmm0, %eax
addl %edx, %eax
vzeroupper
ret
Figure 8. AV512VNNI idiom recognition in GCC auto-vectorization
In addition to three aforementioned enhancements in GCC auto-vectorization, we have improved GCC to utilize vpopcnt[b,w,d,q] instructions when the redundant zero extension and truncation is recognized by the vectorizer as well. These improvements significantly extend GCC auto-vectorization capability for Intel Xeon Scalable processors.
SIMD Vectorization for Intel GPUs
Design Rationale
Intel GPUs, using Intel Xe Architecture, are designed to support both OpenCL SIMT (Single Thread Multiple Data) and SIMD. In this section, we describe how to enable our LLVM VPlan vectorizer for converting OpenMP SIMD loops to SIMD code by leveraging underlying SIMD ISA in Xe GPUs. The rationale behind the design and implementation is two-fold:
- Provide a relative smooth transition to migrate existing C++ and Fortran OpenMP CPU applications that uses SIMD constructs to Xe GPUs utilizing OpenMP offloading and SIMD.
- Exploit SIMD loop vectorization flexibility with different explicit SIMD schemes in the OpenMP offloading region to fully leverage Xe GPU SIMD ISA.
The oneAPI C++/Fortran OpenMP compiler SIMD vectorization for Intel GPUs is designed to exploit the underlying hardware features, allowing fine-grained register management, SIMD size control, and crosslane data sharing.
High-Level SIMD Vectorization Framework
Figure 9 outlines the SIMD vectorization framework implemented in the device compilation path for Intel GPUs, which fully leverages the LLVM VPlan Vectorizer we built for CPUs [4][5] in oneAPI compilers. The VPlan Vectorizer (box 4) takes LLVM scalar IR from the language Front-End (box 1) and middle end optimizations (boxes 2 and 3) performing LLVM Vector IR generation in conjunction with a lowering transformation to GPU target intrinsics defined for Xe GPU operations (5). Then, passing GPU-ready LLVM Vector IR to the GPU Vector Back-End compiler (boxes 6 and 7) [8] using SPIR-V as an interface IR.
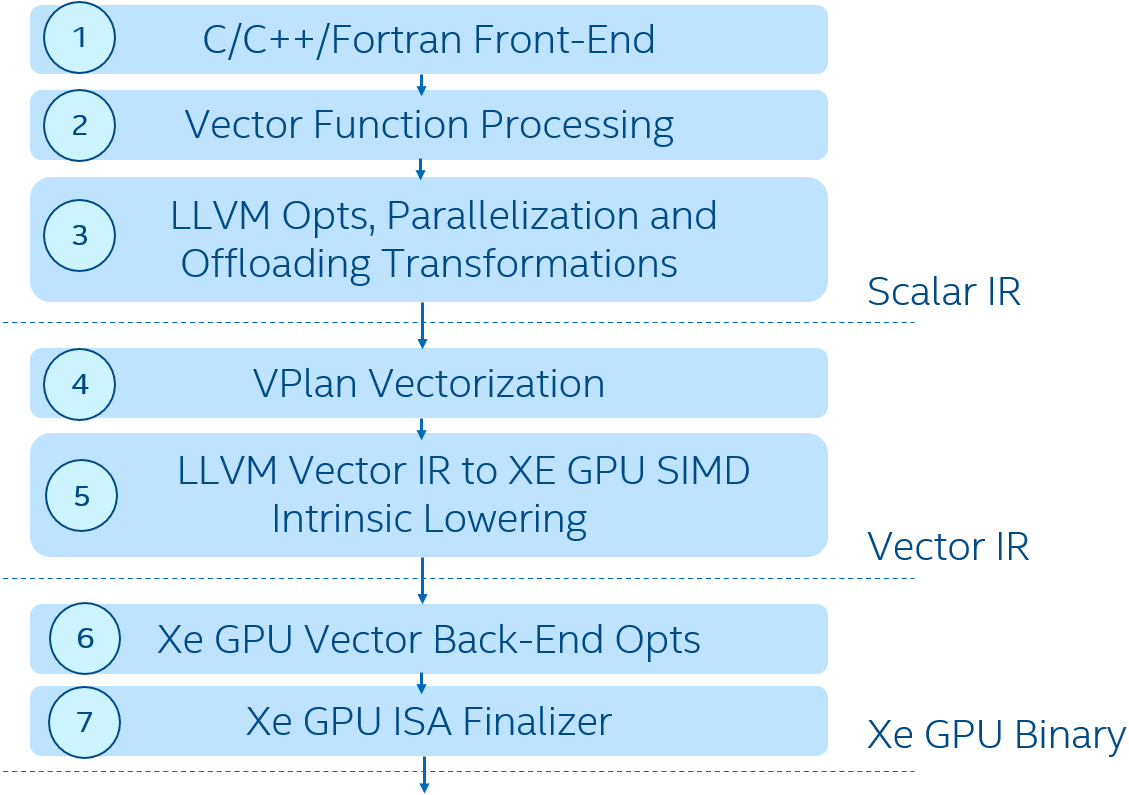
Figure 9. SIMD vectorization framework for device compilation
There is a sequence of explicit SIMD-specific optimizations and transformations (box 6) developed around those GPU-specific intrinsics. Note that programmers are provided with controls on loop vectorization and vector length selection through OpenMP programming APIs while the compiler Vector Back-End (boxes 6 and 7) strives to achieve a tradeoff among various compiler optimizations based on programmer annotations. In addition, OpenMP explicit SIMD kernels generated by the compiler middle end are fully compatible with the Intel GPU OpenCL runtime [1] and oneAPI Level Zero [2] and can be launched directly as if they are written in OpenCL.
Intel Xe Architecture GPU SIMD Code Generation Example
Figure 10 shows an OpenMP offload example. In the target region, there are two SIMD loops: one operates on single-precision multiply-and-add (FMA) with simdlen(8) and the other operates on double-precision multiply-and-add with the simdlen(8) clause. So, the compiler can perform 512-bit SIMD vectorization for both loops.
Float a[N][M]; double b[N][M];
... ...
#pragma omp target teams distribute parallel for map(tofrom:a[0:N][0:M]) map(tofrom:b[0:N][0:M])
for (int k = 0; k < N; ++k) {
float x = k * 1.0f;
double y = k * 1.0;
#pragma omp simd simdlen(16)
for (int j = 0; j < M; ++j) {
a[k][j] = a[k][j] + x*a[k][j];
}
#pragma omp simd simdlen(8)
for (int j = 0; j < M; ++j) {
b[k][j] = b[k][j] + y*b[k][j];
}
}
... ...
Figure 10. An example with different SIMD width in OpenMP target region
For SIMD loop vectorization, if a loop trip count is known at compile-time, the compiler can decide to unroll the loop. In this program example, the first SIMD loop is vectorized with SIMD16 and unrolled by two, the second SIMD loop is vectorized with SIMD8 and unrolled by four for the given trip count M=32 as shown in Figure 11. A common issue to compilers is that the loop trip count is unknown at compile-time. However, if application programmers can reason about and predict the trip count and provide a hint to the compilers using #pragma loop count, it will enable the compiler to perform the desired loop unrolling for compute-bound loops (i.e., computation takes more time than memory accesses).
... ...
mad (16|M0) r7.0<1>:f r5.0<1;0>:f 5.0<1;0>:f r1.6<0>:f {Compacted,$8.dst}
(W&f1.0.any16h) send.dc1 (16|M0) null r33 r7 0x80 0x020D43FF {$3}
(W&f1.0.any16h) send.dc1 (16|M0) r9 r34 null 0x0 0x022D0BFF {$9}
mad (16|M0) r11.0<1>:f r9.0<1;0>:f r9.0<1;0>:f r1.6<0>:f {Compacted,$9.dst}
(W&f1.0.any16h) send.dc1 (16|M0) null r35 r11 0x80 0x020D43FF {A@1,$6}
(W&f1.0.any16h) send.dc1 (16|M0) r13 r36 null 0x0 0x022D0BFF {$10}
mad (8|M0) r15.0<1>:df r13.0<1;0>:df r13.0<1;0>:df r4.2<0>:df {$10.dst}
(W&f1.0.any16h) send.dc1 (16|M0) null r37 r15 0x80 0x020D43FF
(W&f1.0.any16h) send.dc1 (16|M0) r17 r38 null 0x0 0x022D0BFF
mad (8|M0) r19.0<1>:df r17.0<1;0>:df r17.0<1;0>:df r4.2<0>:df {$11.dst}
(W&f1.0.any16h) send.dc1 (16|M0) null r39 r19 0x80 0x020D43FF {A@1,$4}
(W&f1.0.any16h) send.dc1 (16|M0) r22 r40 null 0x0 0x022D0BFF {$12}
mad (8|M0) r24.0<1>:df r22.0<1;0>:df r22.0<1;0>:df r4.2<0>:df {$12.dst}
(W&f1.0.any16h) send.dc1 (16|M0) null r41 r24 0x80 0x020D43FF {A@1,$7}
(W&f1.0.any16h) send.dc1 (16|M0) r26 r42 null 0x0 0x022D0BFF {$13}
mad (8|M0) r28.0<1>:df r26.0<1;0>:df r26.0<1;0>:df r4.2<0>:df {$13.dst}
(W&f1.0.any16h) send.dc1 (16|M0) null r43 r28 0x80 0x020D43FF {A@1,$5}
... ...
Figure 11. Intel GPU SIMD code generated with unrolling based on data types
Summary
We presented the recent evolution of SIMD vectorization technology in the LLVM and GCC compilers for underlying Intel CPU and Intel GPU ISAs. Several vectorization features are illustrated for how to expose the underlying hardware capabilities to exploit SIMD parallelism. On Intel GPUs, SIMD vectorization is a complementary to the existing popular SPMD model. As a continuous effort, more performance tuning and optimizations will be added into Intel oneAPI LLVM-based compilers and GCC compilers for Intel CPUs AVX-512 and AVX-512-FP16/VNNI ISA and Intel GPUs Gen12 ISA.
References
- Intel, Intel® Graphics Compute Runtime for oneAPI Level Zero and OpenCL Driver, 2020
- Intel, oneAPI Level Zero Specification, 2020
- C++ Standards Committee, Data-parallel vector library, 2020
- H. Saito, S. Preis, N. Panchenko, and X. Tian. Reducing the Functionality Gap between AutoVectorization and Explicit Vectorization. In Proceedings of the International Workshop on OpenMP
(IWOMP), LNCS9903, pp. 173-186, Springer, 2016 - X. Tian, H. Saito, E. Su, J. Lin, et.al. LLVM Compiler Implementation for Explicit Parallelization and SIMD Vectorization. LLVM-HPC@SC 2017: 4:1-4:11
- X. Tian, R. Geva, B. Valentine. Unleash the Power of AVX-512 through Architecture, Compiler and Code Modernization, ACM Parallel Architecture and Compiler Technology, September 11-15, 2016, Haifa, Israel
- X. Tian, Bronis R. de Supinski: Explicit Vector Programming with OpenMP* 4.0 SIMD Extensions, HPC Today America, Nov 19. 2014
- Guei-Yuan Lueh, Kaiyu Chen, Gang Chen, Joel Fuentes, Wei-Yu Chen, Fangwen Fu, Hong Jiang, Hongzheng Li, and Daniel Rhee, C-for-Metal: High Performance SIMD Programming on Intel GPUs. CGO 2021, 289-300
- “Intel C/C++ compilers complete adoption of LLVM”
- Matt Masten, Evgeniy Tyurin, K. Mitropoulou, Eric N. Garcia, and H. Saito Function/Kernel Vectorization via Loop Vectorizer, 2018 IEEE/ACM 5th Workshop on the LLVM Compiler Infrastructure in HPC (LLVM-HPC)
- Intel AVX-512-FP16 Architecture Specification
- Intel Corporation, Vector Function Application Binary Interface
- GCC patches (look for AVX512/VNNI/FP16 support), see also for more on FP16 patches