Intel® Optimizations for TensorFlow* with the Intel® oneAPI Deep Neural Network Library (oneDNN) has been available in the official TensorFlow release since version 2.5. By default, the oneDNN optimizations are turned off. You can enable the oneDNN optimizations by setting the environment variable TF_ENABLE_ONEDNN_OPS to 1. When enabled and configured properly, these oneDNN optimizations can provide a 3X performance improvement over using the stock TensorFlow*.
Performance Benefits of Official TensorFlow* 2.8 with oneDNN Optimizations on AWS C6i Instance Types
We benchmarked several popular TensorFlow models from Model Zoo for Intel® Architecture on inference, comparing results using official TensorFlow 2.8 (Stock TF 2.8), both with and without oneDNN optimizations, on AWS C6i instance types powered by 3rd generation Intel® Xeon® Scalable processor.
Inference was benchmarked using AWS c6i.2xlarge instance type for latency measurement and using AWS c6i.12xlarge instance type for throughput measurements.s
Throughput improvement with oneDNN optimizations on AWS c6i.12xlarge
We benchmarked different models on AWS c6i.12xlarge instance type with 24 physical CPU cores and 96 GB memory on a single socket.
Table 1 and Figure 1 show the related performance improvement for inference across a range of models for different use cases. For offline throughput measurement (using large batches), performance improvements are up to 3X, and performance boost varies among models. Most of image recognition models achieve a ~2X performance boost, and language modeling model has a ~1.5X performance boost.
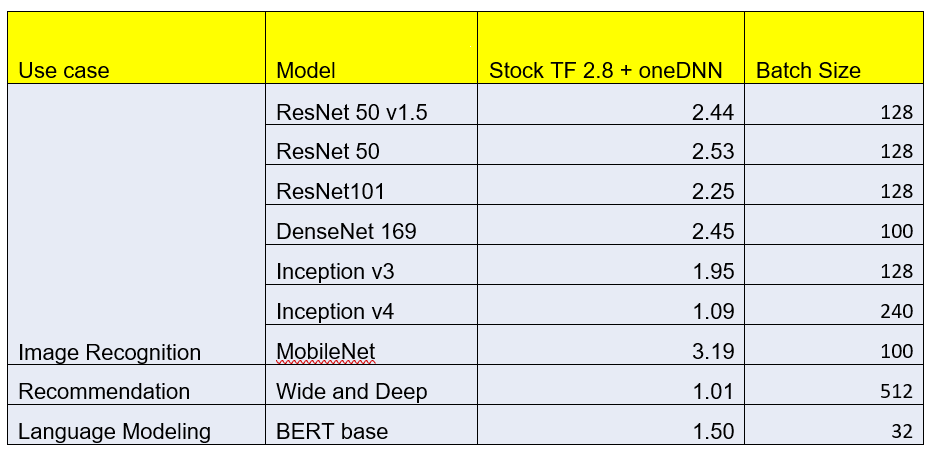
Table 1. Inference throughput improvements

Figure 1. Inference throughput improvements
Latency improvement with oneDNN optimizations on AWS c6i.2xlarge
We benchmarked different models on AWS c6i.2xlarge instance type with 4 physical CPU cores and 8 GB memory on a single socket.
For real-time inference (batch size =1), the oneDNN-enabled TensorFlow* was faster, taking between 47% and 81% of the time of the unoptimized version.

Table 2. Inference latency improvements

Figure 2. Inference latency improvements
Throughput improvement for int8 models with oneDNN optimizations on AWS c6i.12xlarge
oneDNN also enabled the int8 low precision data type to improve compute-intensive inference performance on the AWS c5 and c6i instance types powered by 2nd and 3rd generation Intel® Xeon® Scalable processors.
Figure 3 shows the related performance improvement for inference with low precision data types across a range of models. For offline throughput measurement (using large batches), performance improvements are up to 3.5X with int8 data type compared to fp32 data type.
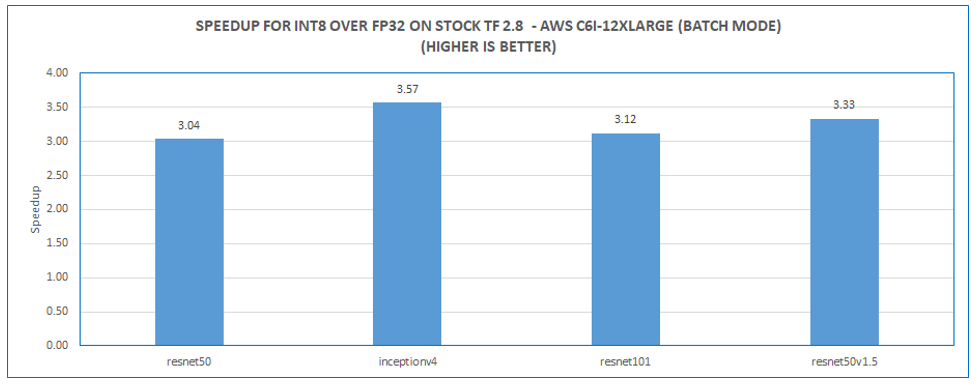
Figure 3. Int8 Inference throughput improvements
Performance Analysis for Official TensorFlow* 2.8 with oneDNN Optimizations
Throughput improvement analysis among different AWS c6i instance types
To understand throughput scaling with large batch size when we increase the number of vCPUs and the available memory capacity, we benchmarked three different c6i instance types as shown in Table 3.

Table 3. Comparison among AWS instance types
For large batch size, Image recognition models such as resnet50 show good strong scaling efficiency and ~5X speedup when the number of vCPUs is increased from 8 to 48.
The recommendation model “wide and deep” doesn’t show a strong scaling efficiency even when the batch size is 512.
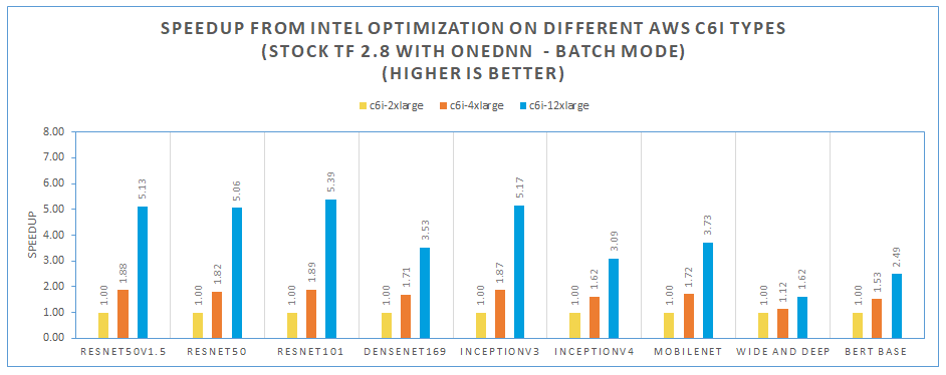
Figure 4. Inference throughput improvements among different AWS C6i types
To further analyze the impact of different vCPU numbers for throughput, we used a oneDNN feature called ITT tagging, to analyze performance on deep learning operations level and itt-python for inference iteration tagging by using Intel® VTune™ Profiler.
Figure 5 shows the profiling result of resnet50v1.5 inference from Intel® Model Zoo on AWS c6i.2xlarge.
Resnet50v1.5 model from Intel® Model Zoo only uses physical CPU cores, so it spawns 4 threads for 4 physical CPU cores on AWS c6i.2xlarge instance type.
One inference iteration from Resnet50v1.5 model is identified in Figure 5. There are 53 convolution oneDNN ops, 2 inner product oneDNN ops and 1 pooling_v2 oneDNN ops dispatched to the second thread in this inference iteration.
The inference iteration is tagged as “infer sess” task type and is marked as a blue line along the timeline.
The “infer sess” task took 1.526 second, and inference computation are dispatched to 4 threads at the same time. The oneDNN tasks in each thread took 1.493 second on average, and each convolution task took 0.028 second on average.
We observed the thread utilization among oneDNN ops in one inference iteration is around 97%, which is high.
For the timeline diagram in Figure 5, each convolution ops is marked as a brown line, and an inference iteration is marked as a blue line. There is an inner product ops marked as a green line after the first convolution ops. Two inner product ops are marked as yellow lines at the end of the inference iteration.
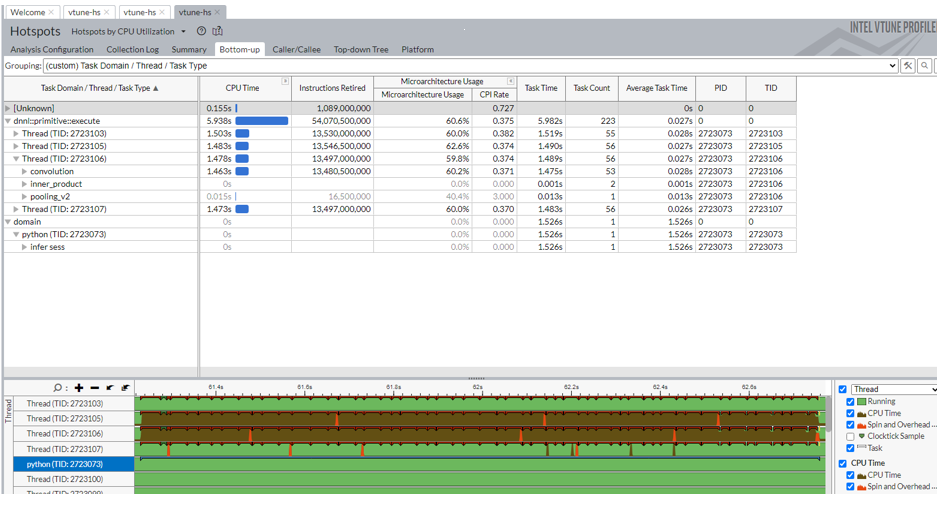
Figure 5. Throughput analysis on AWS c6i.2xlarge by using VTune™
Figure 6 shows the profiling result of resnet50v1.5 inference from Intel® Model Zoo on AWS c6i.12xlarge.
Resnet50v1.5 model from Intel® Model Zoo only uses physical CPU cores, so it spawns 24 threads for 24 physical CPU cores on AWS c6i.12xlarge instance type.
The thread utilization among oneDNN ops in one inference iteration on AWS c6i.12xlarge is around 94.7%, which is still high. Only a 2.3% drop on thread utilization was observed when we increased the number of threads from 4 to 24 for throughput measurement with a large batch size
Each convolution task took 0.006 second on average, and it got around a 4.6X speedup from 4 threads to 24 threads.
Moreover, VTune™ also highlighted the spin and overhead times in red. There are indeed few spins and overheads noted in Figure 6.
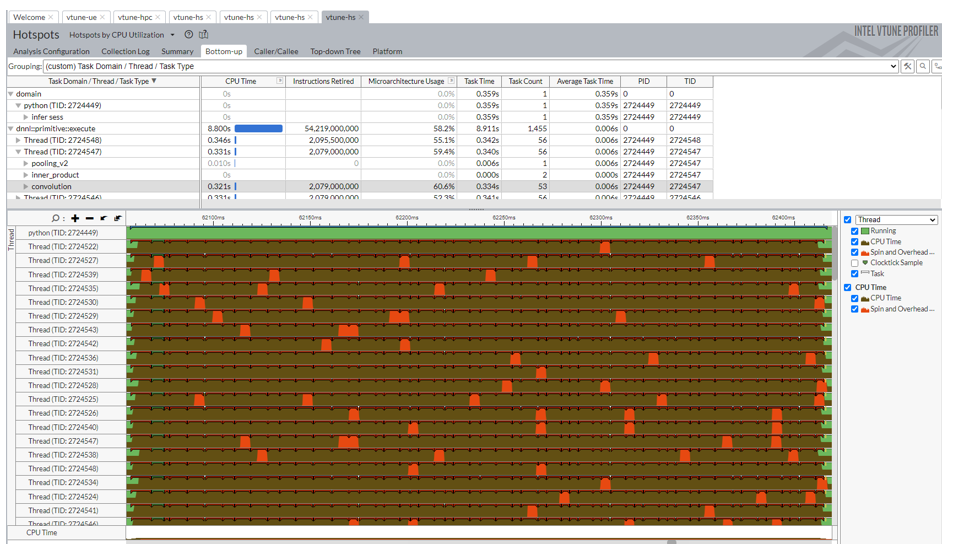
Figure 6. Throughput analysis on AWS c6i.12xlarge by using VTune™
In summary, instance type such as c6i.12xlarge with a higher number of vCPUs should be able to achieve better throughput for large batch size.
Inference latency improvement analysis among different AWS c6i instance types
To understand relative latency reduction with batch size 1 when we increase the number of vCPUs and available memory capacity, we benchmarked among the different c6i instance types listed in Table 3
With batch size equals to 1, Image recognition models such as resnet50, show poor latency reduction scaling efficiency and only a maximum 45% time reduction when the number of vCPUs is increased from 8 to 48.
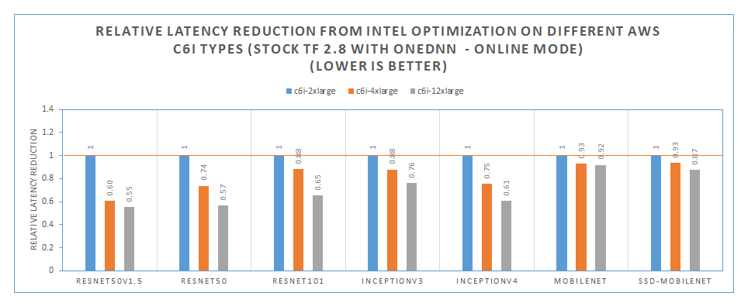
Figure 7. Inference latency improvements among different AWS C6i types
The “infer sess” task took 14.3 ms, with inference computations dispatched to 4 threads at the same time. The oneDNN tasks in each thread took 12.56 ms on average, and each convolution task took 0.231 ms on average.
Therefore, the thread utilization among oneDNN ops in one inference iteration is around 87%, which is 10% lower than the large batch size case.

Figure 8. Latency analysis on AWS c6i.2xlarge by using VTune™
Resnet50v1.5 model from Intel® Model Zoo only uses physical CPU cores, so it spawns 24 threads for 24 physical CPU cores on AWS c6i.12xlarge instance type.
The thread utilization among oneDNN ops in one inference iteration on AWS c6i.12xlarge is around 57%, which is low. A 30% drop on thread utilization was observed when we increased the number of threads from 4 to 24 for latency measurement with batch size 1.
Each convolution task took 0.07 ms on average, getting around a 3.3X speedup from 4 threads to 24 threads, which is also lower than the large batch size case.
VTune™ also highlights the spin and overhead times in red. There are many spins and overheads shown in Figure 9 and oneDNN tasks are sparsely distributed, if we compare it to Figure 6.

Figure 9. Latency analysis on AWS c6i.12xlarge by using VTune™
In summary, instance type such as c6i.2xlarge with a smaller number of vCPUs should be able to achieve reasonable latency with better cost-effectiveness for batch size 1.
Throughput improvement analysis among TensorFlow* operations
To further understand throughput improvement with oneDNN optimization, we look into TensorFlow* operations level for performance analysis by using Intel® Model Zoo perf analysis notebooks.
By enabling TensorFlow* Timeline via Intel® Model Zoo perf analysis notebooks, the hotspots of TensorFlow* operations among models are identified as Table 4.
All hot spots in Table 4 took at least 8% of total execution time, and some hot spots might take >95% of total execution time.
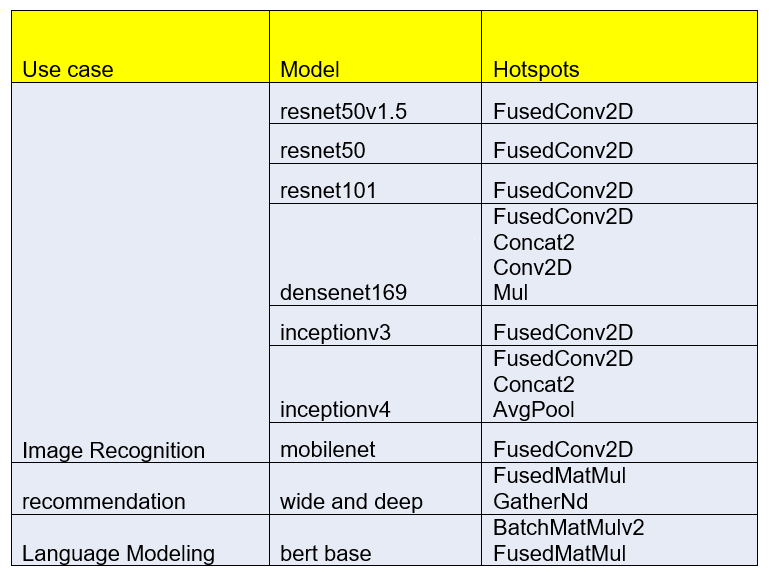
Table 4. Top Hotspots for TensorFlow operations among models
The speedups for different TensorFlow* operations with oneDNN optimizations among different models are shown in Figure 10.
FusedConv2D, which is the hotspot among many image recognition models, achieves a ~1.3X-2.4X speedup by enabling oneDNN optimizations.
MaxPool and AvgPool, which are hotspots of inceptionV4, show a ~2.7X-4.7X speedup.
FusedMatMul, which is the hotspot of recommendation and language modeling models, has a slight performance degradation. Overall performance for those models should improve by improving FusedMatMul performance.
This is a known issue for TensorFlow* v2.8, and a fix should be in future release.
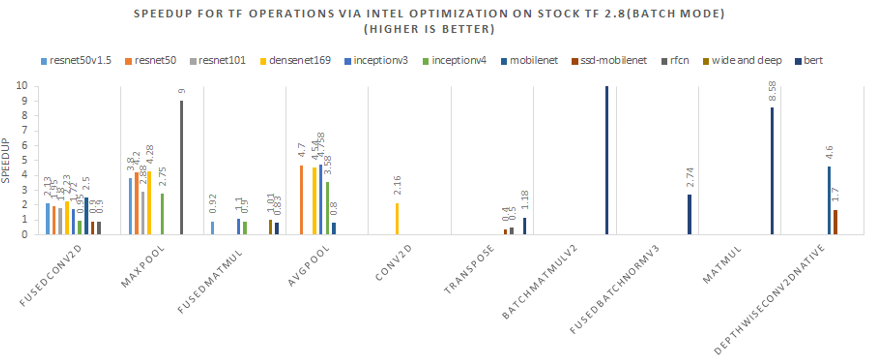
Figure 10. Throughput improvement analysis among TensorFlow* operations
Throughput analysis for int8 models among TensorFlow* and oneDNN operations
The speedups for different TensorFlow* quantized int8 operations compared to fp32 operations among different models are shown in Figure 11.
FusedConv2D, ConcatV2, AvgPool, and MaxPool TensorFlow operations have implementations for int8 quantization via oneDNN. All operations achieve a 3.3X or greater speedup among different models, as shown in Figure 11.

Figure 11. Throughput improvement analysis for int8 models among TensorFlow* operations
Those TensorFlow* operations will invoke oneDNN operations such as convolution and pooling_v2. The oneDNN operations related to those quantized TensorFlow operations also achieve a 3.5X or greater speedup, shown in Figure 12.
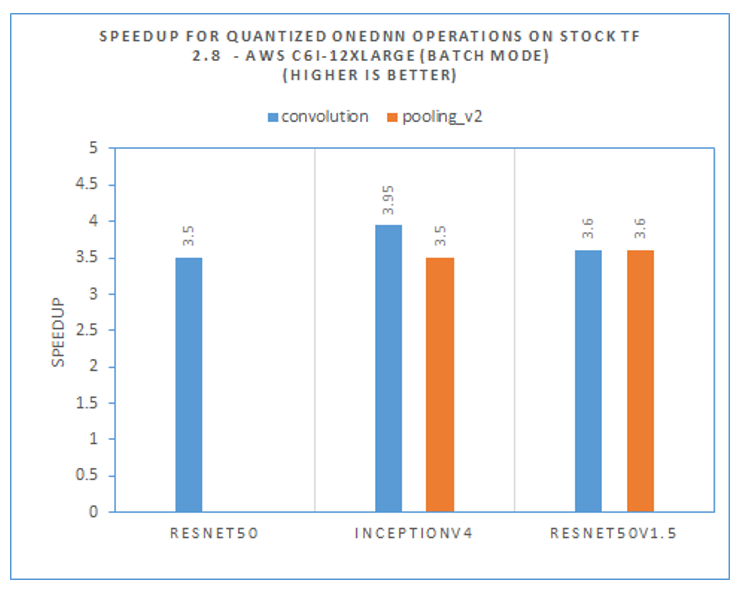
Figure 12. Throughput improvement analysis for int8 models among oneDNN operations
In summary, users could expect a~3X speedup on TensorFlow quantized operations among these popular image recognition models. The overall model speedup depends on the percentage of computation time on those quantized operations.
Benchmarking system configurations

Intel® AI Analytics Toolkit
Accelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python* libraries.
Additional Resources
- Use Intel Deep Learning Optimizations in TensorFlow
- Speed up Databricks Runtime for ML with Intel-optimized Libraries
- Accelerate AI Deep Learning with oneDNN
- ArrayFire Interoperability with oneAPI, Libraries, and OpenCL Code
- Accelerate AI Inferencing from Development to Deployment
- Accelerate & Benchmark AI Workloads on Intel® Platforms
- Google and Intel Optimize TensorFlow for Deep Learning Performance