Set a Single Environment Variable to Get Up to 3x Performance Boost
Mahmoud Abuzaina, deep learning software engineer, Intel
Ramesh AG, principal engineer, Intel
Jason Chow, marketing manager, Intel
Xiaoming Cui, deep learning software engineer, Intel
Rama Ketineni, deep learning software engineer, Intel
Guozhong Zhuang, deep learning software engineer, Intel
@IntelDevTools
Get the Latest on All Things CODE
Sign Up

TensorFlow* is a widely used deep-learning framework. Intel has been collaborating with Google to optimize TensorFlow performance on platforms based on Intel® Xeon® processors, and using Intel oneAPI Deep Neural Network (oneDNN). oneDNN is an open-source, cross-platform performance library for deep-learning applications. TensorFlow optimizations are enabled via oneDNN to accelerate key performance-intensive operations such as convolution, matrix multiplication, and batch normalization.
We are happy to announce that the oneDNN optimizations are now available in the official TensorFlow release, enabling developers to seamlessly benefit from the Intel optimizations. Additional TensorFlow-based applications, including TensorFlow* Extended, TensorFlow* Hub, and TensorFlow* Serving will also include the oneDNN optimizations.
Enable oneDNN Optimizations in TensorFlow 2.5
- Install the latest TensorFlow pip package: pip install tensorflow
- By default, the oneDNN optimizations are turned off. To enable them, set the environment variable. TF_ENABLE_ONEDNN_OPTS. On Linux systems, for example: export TF_ENABLE_ONEDNN_OPTS=1
- Run your TensorFlow application.
Performance Benefits of TensorFlow 2.5 with oneDNN Optimizations
We benchmarked several popular TensorFlow models on deep learning inference and training, comparing results with oneDNN optimizations enabled on a 2nd Generation Intel® Xeon® Scalable processor.
Inference was benchmarked using four cores on a single socket for latency measurements with all 28 cores for throughput tests. Figures 1 and 2 show the relative performance improvement for inference across a range of the models. For offline throughput measurements (using large batches), performance improvements of up to 3x are possible (Figure 1). For real-time server inference (batch size = 1), the oneDNN-enabled TensorFlow took 29 percent to 77 percent of the time of the unoptimized version for 10 out of 11 models (Figure 2).
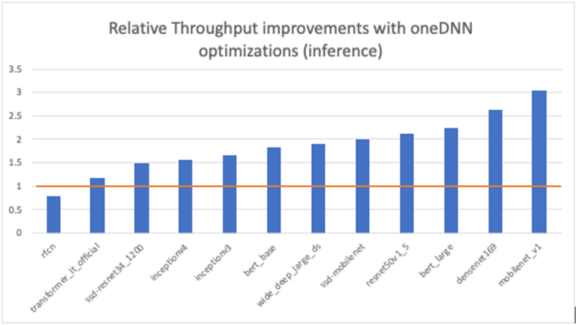
Figure 1. Inference throughput improvements
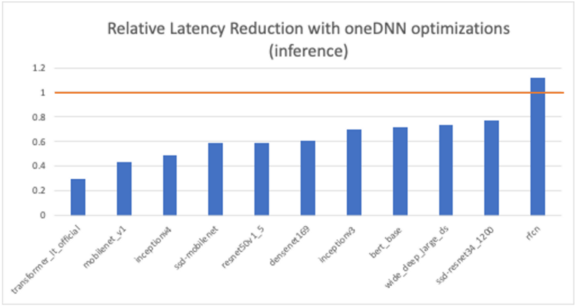
Figure 2. Inference latency improvements
For training, we observed up to 2.4x performance gains across several popular models (Figure 3). We also observed gains with previous TensorFlow 1.x graph models and the newer TensorFlow 2.x eager execution-based models.
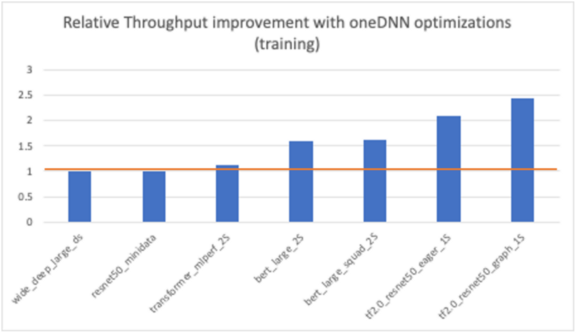
Figure 3. Training performance improvements.
You can reproduce these benchmarks by getting the same models from Model Zoo for Intel® Architecture.
git clone https://github.com/IntelAI/models.git
The README.md files contain instructions to perform model training and inference. For example, the instructions for the inceptionv3 model are available in models/benchmarks/image_recognition/tensorflow/inceptionv3/README.md.
Based on the benchmarking and results, we encourage data scientists and developers to download the latest official TensorFlow release and enable the oneDNN optimizations to get immediate performance improvements on Intel® Xeon® processor-based platforms.
Low Precision Data Type
oneDNN also enables the int8 and bfloat16 data types to improve compute-intensive training and inference performance on the latest 2nd and 3rd Generation Intel Xeon Scalable processors. These optimizations can improve model execution time by up to 4x for int8 and 2x for bfloat16. The official TensorFlow 2.5 release currently does not support the int8 data type, but this limitation will be addressed in a later version. In the meantime, to use the int8 data type, you can download the Intel® Optimization for TensorFlow*.
TensorFlow Resources and Support
Get TensorFlow 2.5 from:
Technical Support:
Benchmarking System Configuration
Two-socket Intel® Xeon® Platinum 8280L Processor, 28 cores, HT On, Turbo On, total memory 256 GB
System BIOS: SE5C620.86B.02.01.0012.070720200218
Compiler and libraries: gcc 7.5.0, oneDNN v2.2.0
Datatype: FP32
Data collection date: May 9, 2021
______
You May Also Like
| Intel® Optimization for TensorFlow*: Tips and Tricks for AI and HPC Convergence |
| Intel® oneAPI Deep Neural Network Library (oneDNN) |