[This article originally appeared on anyscale.com and is reprinted with permission.]
Ray is a framework with simple and universal APIs for building innovative AI applications. BigDL is an open-source framework for building scalable end-to-end AI on distributed big data. It leverages Ray and its native libraries to support advanced AI use-cases such as AutoML and Automated Time Series Analysis. We will introduce some of the core components in BigDL and showcase how it takes advantage of Ray to build out the underlying infrastructure (i.e., RayOnSpark, AutoML, etc.), and how these will help users build AI applications using Project Chronos.
RayOnSpark: Seamlessly Run Ray Applications on Top of Apache Spark
Ray is an open-source distributed framework for easily running emerging AI applications such as deep reinforcement learning and automated machine learning (ML). BigDL seamlessly integrates Ray into big data preprocessing pipelines through RayOnSpark and it has already been used to build several advanced end-to-end AI applications for specific areas such as AutoML and Chronos. RayOnSpark runs Ray programs on top of Apache Spark™ on big data clusters (e.g., an Apache Hadoop™* or Kubernetes* cluster) and as a result, objects like in-memory DataFrames can be directly streamed into Ray applications for advanced AI applications. With RayOnSpark, users can directly try various emerging AI applications on their existing big data clusters in a production environment. It also allows Ray applications to seamlessly integrate into Big Data processing pipelines and directly run on in-memory DataFrames.
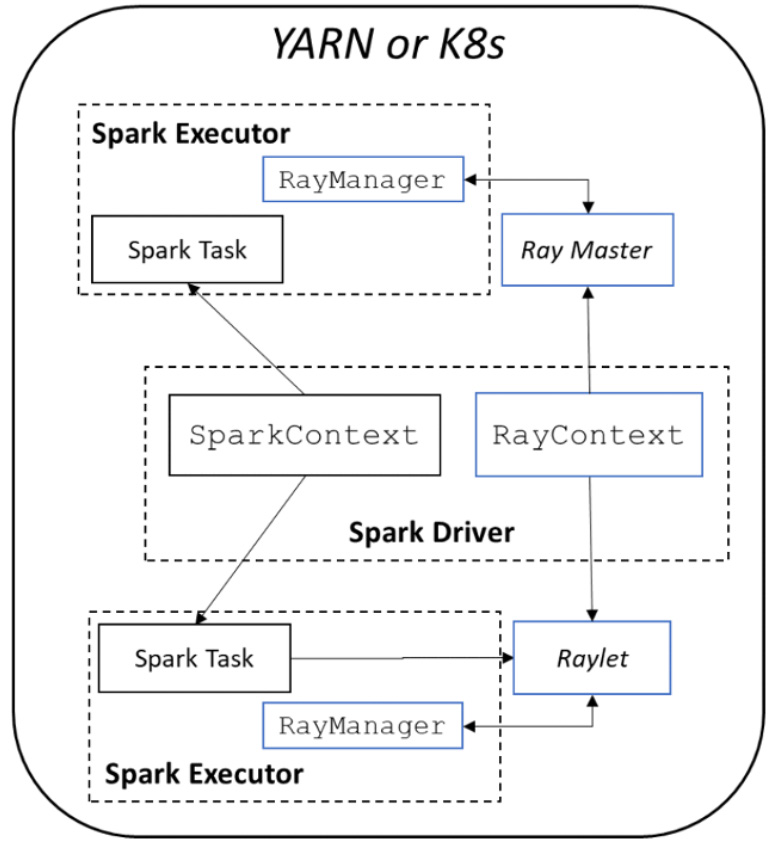
Figure 1. RayOnSpark architecture
Figure 1 illustrates the architecture of RayOnSpark. In the Spark implementation, a Spark program runs on the driver node and creates a SparkSession with a SparkContext object responsible for launching multiple Spark executors on a cluster to run Spark jobs. In RayOnSpark, the Spark driver program additionally creates a RayContext object, which will automatically launch Ray processes alongside each Spark executor across the same cluster. RayContext will also create a RayManager inside each Spark executor to manage Ray processes (e.g., automatically shutting down the processes when the program exits). Figure 2 demonstrates how users can directly write Ray code inside standard Spark applications after initializing RayOnSpark:
import ray
from bigdl.orca import init_orca_context
from bigdl.orca.ray import RayContext
# Initialize SparkContext on the underlying cluster (e.g. the Hadoop/Yarn cluster)
sc = init_orca_context(cluster_mode="yarn", cores=..., memory=..., num_nodess...)
# Initialize RayContext and launch Ray under the same cluster.
ray_ctx RayContext(sc, object_store_memory=...,...)
ray_ctx.init()
@ray.remote
class Counter(object)
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
return self.n
# The Ray actors are created across the big data cluster
counters = [Counter.remote() for i in range(5)]
ray.get([c.increment.remote() for c in counters])
ray_ctx.stop()
sc.stop()
Figure 2. Sample code of RayOnSpark
AutoML (orca.automl): Tune AI Applications Effortlessly Using Ray Tune
Hyperparameter optimization (HPO) is important for achieving accuracy, performance, etc. of a ML or deep learning (DL) model. However, manual HPO can be a time-consuming process that may not optimize thoroughly enough. On the other hand, HPO in a distributed environment can be difficult to implement. BigDL introduces an AutoML capability (via orca.automl) built on top of Ray Tune to make life easier for data scientists.
What Is orca.automl?
In many cases, data scientists would prefer to prototype, debug, and tune AI applications on their laptops, and if the same code can be moved intact to a cluster, it will greatly improve the end-to-end productivity. BigDL’s Orca project helps users to seamlessly scale their code from a laptop to a cluster. Furthermore, BigDL’s orca.automl leverages RayOnSpark and Ray Tune, and provides a distributed, hyperparameter tuning API called AutoEstimator. As Ray Tune is framework agnostic, AutoEstimator is suitable for both PyTorch and TensorFlow models. Users can tune models in a consistent manner on their laptops, local servers, Kubernetes clusters, Hadoop/YARN clusters, etc.
With these features, orca.automl in BigDL can be used to automatically explore the search space (including models, hyperparameters, etc.) for many AI applications. As an example, we have implemented AutoXGBoost (XGBoost with HPO) using BigDL’s orca.automl to automatically fit and optimize XGBoost models. Compared to a similar solution on an Nvidia A100, training with AutoXGBoost is ~1.7x faster, and the final model is more accurate. See Scalable AutoXGBoost Using Analytics Zoo AutoML for more details. You may also refer to the orca.automl User Guide for design information and the AutoXGBoost Quick Start or Auto Tuning for arbitrary models for hands-on practice.
Chronos: Build Automated Time Series Analysis Using AutoTS on Ray
We have also developed a framework for Automatics Time Series Analysis, known as Project Chronos.orca.automl is leveraged to tune hyperparameters during the automatic analysis.
Why Do We Need Chronos?
Time series (TS) analysis is now widely used in many real-world applications (such as network quality analysis in telecommunications, log analysis for data center operations, predictive maintenance for highvalue equipment, etc.) and getting more and more important. Accurate forecasting and detection have become the most sought-after tasks and prove to be huge challenges for traditional approaches. DL methods often perceive time series forecasting and detection as a sequence modeling problem and have recently been applied to these problems with much success.
On the other hand, building the ML applications for time series forecasting/detection can be a laborious and knowledge-intensive process. Hyperparameter setting, preprocessing, and feature engineering may all become bottlenecks for a dedicated DL model. To provide an efficient, powerful, and easy-to-use time series analysis toolkit, we launched Project Chronos, a framework for building large-scale time series analysis applications. This can be used to apply AutoML and distributed training because it is built on top of Ray Tune, Ray Train, and RayOnSpark.
Chronos Architecture
Chronos features several (10+) built-in DL and ML models for time series forecasting, detection, and simulation as well as many (70+) data processing and feature engineering utilities. Users can call standalone algorithms and models (forecasters, detectors, simulators) themselves to acquire the highest flexibility or use our highly integrated and scalable and automated workflow for time series (AutoTS). The inferencing process has also been optimized in a number of ways, including integrating ONNX runtimec.
Figure 3 illustrates Chronos's architecture on the top of BigDL and Ray. This section focuses on the AutoTS component. The AutoTS framework uses Ray Tune as a hyperparameter search engine (running on top of RayOnSpark). For automatic data processing, the search engine selects the best lookback value for a prediction task. For automatic feature engineering, the search engine selects the best subset from a set of features that are automatically generated by various feature generation tools (e.g., tsfresh). For automatic modeling, the search engine searches for hyperparameters such as hidden dim, learning rate, etc.
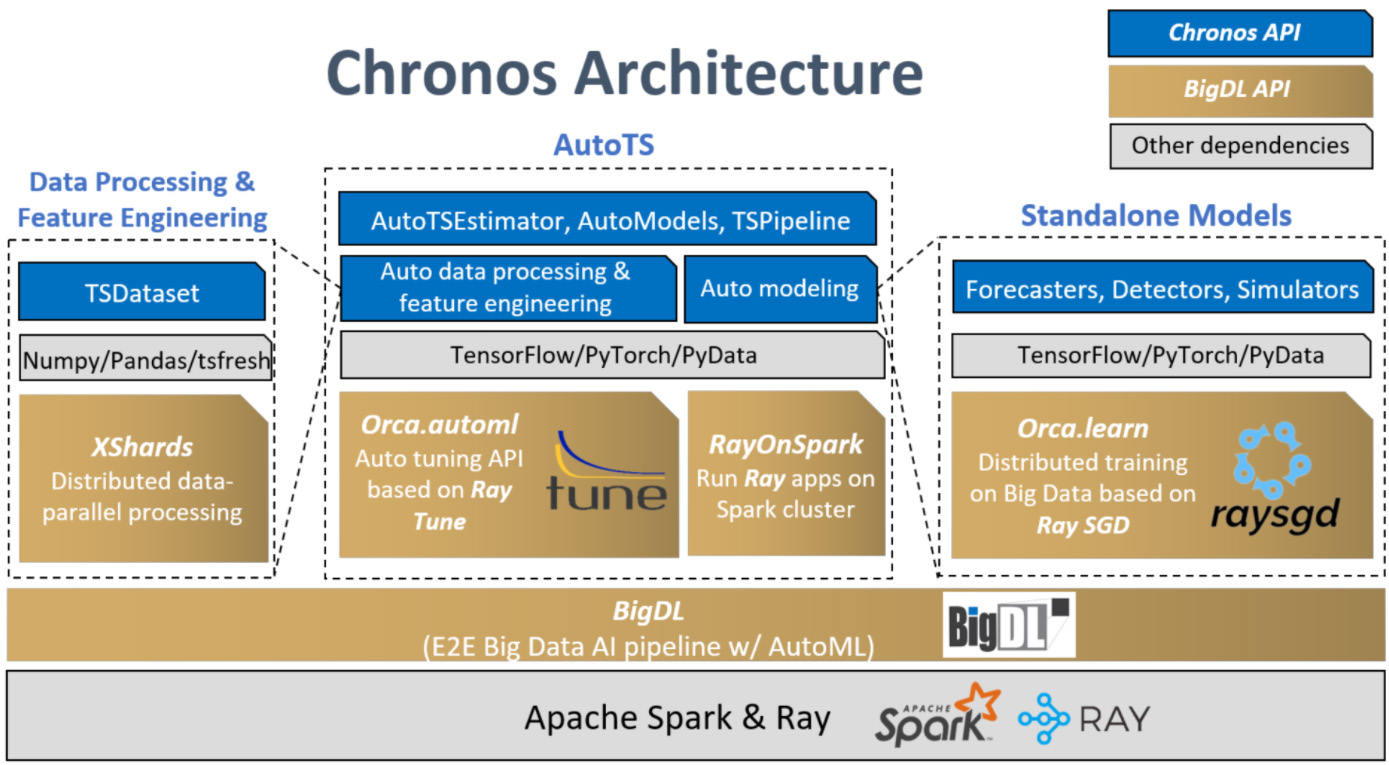
Figure 3. Project Chronos architecture
Chronos Hands-On Example for the AutoTS Workflow
The following code illustrates the training and inferencing process of a time series forecasting pipeline using Chronos's friendly and highly integrated AutoTS workflow:
import pandas as pd
from sklearn.preprocessing import Standardscaler
from bigdl.chronos.data import TSDataset
# data initialization and split
df = pd.read_csv("table.csv")
tsdata_train, tsdata_val, tsdata_test = TSDataset.from_pandas(df,
dt_col="StartTime",
target_col="AvgRate",
with_split=True,
val_ratio=0.1)
# data processing and feature engineering
standard_scaler = Standardscaler()
for tsdata in [tsdata_train, tsdata_val, tsdata_test]:
tsdata.gen_dt_feature()\
.impute(mode="last")\
.scale(standard_scaler, fit=(tsdata is tsdata_train))
This particular workflow utilizes the simple and straightforward API on the TSDataset to do some typical time series processing (e.g., imputing, scaling, etc.) and feature generation.
Then, users can initialize AutoTSEstimator by stating the model (built-in model name/model create function for 3rd party model), lookback, and horizon. The AutoTSEstimator runs the search procedure on top of Ray Tune; each run generates several trials (each with a different combination of hyperparameters and subset of features) at a time and distributes the trials in the Ray cluster. After all trials complete, the best set of hyperparameters, optimized model, and data processing procedure are retrieved according to the target metrics, which are used to compose the resulting TSPipeline.
from bigdl.chronos.autots import AutoTSEstimator
import bigdl.orca.automl.hp as hp
# create a AutoTSEstimator
auto_estimator = AutoTSEstimator(model='tcn',
past_seq_len=hp.randint(50,100),
future_seq_len=1)
# fit on the AutoTSEstimator with HPO, auto feature, past_seq_len selector
ts_pipeline auto_estimator.fit(data=tsdata_train,
validation_data=tsdata_val)
The TSPipeline can be used for prediction, evaluation, and incremental fitting.
# predict/evaluate with TSPipeline
y_pred = ts_pipeline.predict(tsdata_test)
test_mse = ts_pipeline.evaluate(tsdata_test, metrics = ['mse'])
For detailed information, Chronos user guide is a great place to start.
5G Network Time Series Analysis Using Chronos AutoTS
Chronos has been adopted widely in many areas, such as telecommunication and AI operation. Capgemini Engineering leverages the Chronos AutoML workflow and inferencing optimization in their 5G Medium Access Controller (MAC) to realize cognitive capabilities as part of Intelligent to RAN Controller nodes. In their tasks, Chronos is used to forecast UE’s mobility to assist the MAC scheduler in efficient link adaptation on two-key KPIs. With Chronos AutoTS, Capgemini engineers changed their model to our built-in TCN model and enlarged the lookback value, which successfully increased the AI accuracy by 55%. Please refer to the white paper for more details.
Conclusion
In this article, we showed how BigDL leverages Ray and its libraries to build scalable AI applications for big data (using RayOnSpark), improve end-to-end AI development productivity (using AutoML on top of RayTune), and build domain-specific AI use-cases such as Automatic Time Series Analysis with project Chronos. BigDL also adopts Ray in other aspects, for example Ray Train is being used in the BigDL Orca project to seamlessly scale-out single-node Python notebooks across large clusters. We are also exploring other use-cases such as recommendation systems, reinforcement learning, etc. which will leverage the AutoML capabilities built on top of Ray.