Article at a Glance
- oneAPI is an open, unified programming model designed to simplify development and deployment of data-centric workloads across central processing units (CPUs), graphics processing units (GPUs), field-programmable gate arrays (FPGAs), and other accelerators.
- In a heterogeneous compute environment, developers need to understand the capabilities and limitations of each compute architecture to effectively match the appropriate workload to each compute device.
This article:
- Compares the architectural differences between CPUs, GPUs, and FPGAs
- Shows how SYCL* constructs are mapped to each architecture
- Examines library support differences
- Discusses characteristics of applications best suited for each architecture
Compute Architecture Comparison of CPUs, GPUs, and FPGAs
CPU Architecture
Among the compute architectures discussed here, CPUs, with over a half-century of history, are the most well-known and ubiquitous. CPU architecture is sometimes referred to as scalar architecture because it is designed to process serial instructions efficiently. CPUs, through many techniques available, are optimized to increase instruction-level parallelism (ILP) so that serial programs can be executed as fast possible.
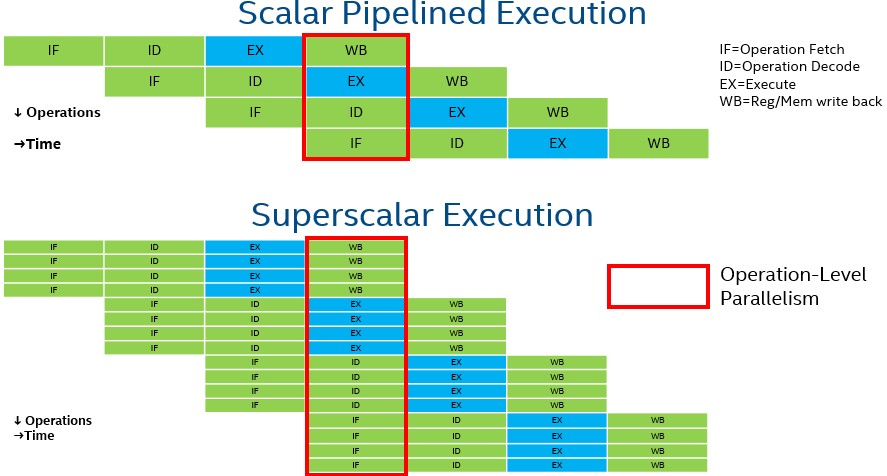
A scalar pipelined CPU core can execute instructions, divided into stages, at the rate of up to one instruction per clock cycle (IPC) when there are no dependencies.
To boost performance, modern CPU cores are multi-thread, superscalar processors with sophisticated mechanisms that are used to find instruction-level parallelism and execute multiple out-of-order instructions per clock cycle. They fetch many instructions at once, find the dependency-graph of those instructions, utilize sophisticated branch-prediction mechanisms, and execute those instructions in parallel (typically at 10x the performance of scalar processors in terms of IPC).
The diagram below shows the simplified execution of a scalar-pipelined CPU and a superscalar CPU.
Advantages
There are many advantages to using a CPU for compute compared to offloading to a coprocessor, such as a GPU or an FPGA.
Why?
Because data does not need to be offloaded. Latency is reduced with minimal data transfer overhead.
Since high-frequency CPUs are tuned to optimize scalar execution and most software algorithms are serial in nature, high performance can easily be achieved on modern CPUs.
For parts of the algorithm that can be vector-parallelized, modern CPUs support single instruction, multiple-data (SIMD) instructions like the Intel® Advanced Vector Extensions 512 and Intel® Advanced Matrix Extensions. As a result, CPUs are suited to a wide variety of workloads. Even for massively parallel workloads, CPUs can outperform accelerators for algorithms with high branch divergence or high instruction-level parallelism, especially where the data size to compute ratio is high.
CPU advantages:
- Out-of-order superscalar execution
- Sophisticated control to extract tremendous instruction level-parallelism
- Accurate branch prediction
- Automatic parallelism on sequential code
- Large number of supported instructions
- Lower latency when compared to offload acceleration
- Sequential code execution results in ease-of-development
GPU Architecture
GPUs are processors made of massively parallel, smaller, and more specialized cores than those generally found in high-performance CPUs. GPU architecture:
- Is optimized for aggregate throughput across all cores, deemphasizing individual thread latency and performance.
- Efficiently processes vector data (an array of numbers) and is often referred to as vector architecture.
- Dedicates more silicon space to compute and less to cache and control.
As a result, GPU hardware explores less instruction-level parallelism and relies on software-given parallelism to achieve performance and efficiency.
GPUs are in-order processors and do not support sophisticated branch prediction. Instead, they have a plethora of arithmetic logic units (ALUs) and deep pipelines. Performance is achieved through multithreaded execution of large and independent data, which amortizes the cost of simpler control and smaller caches.
Finally, GPUs employ a single instruction, multiple threads (SIMT) execution model where multithreading and SIMD are leveraged together. In the SIMT model, multiple threads (work-items or a sequence of SIMD lane operations) are processed in lockstep in the same SIMD instruction stream. Multiple SIMD instruction streams are mapped to a single execution unit (EU) or vector engine where the GPU can context-switch among those SIMD instruction streams when one stream is stalled.
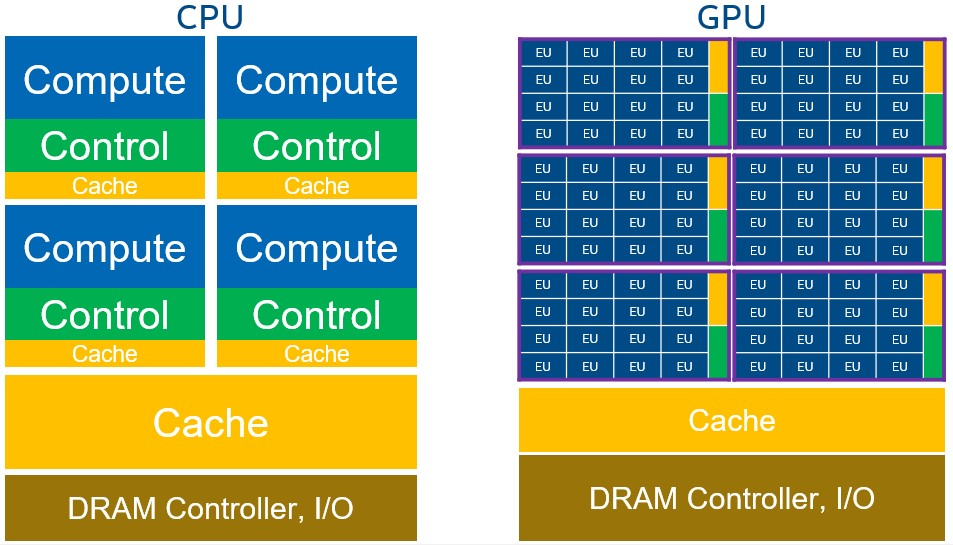
The above diagram shows the difference between the CPU and GPU.
EUs or vector engines are the basic unit of processing on a GPU. Each EU can process multiple SIMD instruction streams. In the same silicon space, GPUs have more compute logic than CPUs. GPUs are organized hierarchically. Multiple EUs or vector engines combine to form a compute unit with shared local memory and synchronization mechanisms (aka Xe-core, sub-slice or streaming multiprocessor, outlined in purple). The compute units combine to form the GPU.
GPU Advantages:
- Massively parallel, up to thousands of small and efficient SIMD cores/EUs
- Efficient execution of data-parallel code
- High dynamic random-access memory (DRAM) bandwidth
FPGA Architecture
Unlike CPUs and GPUs, which are software-programmable fixed architectures, FPGAs are reconfigurable, and their compute engines are defined by the user. When writing software targeting an FPGA, compiled instructions become hardware components that are laid out on the FPGA fabric in space, and those components can all execute in parallel. Because of this, FPGA architecture is sometimes referred to as a spatial architecture.
An FPGA is a massive array of small processing units consisting of up to millions of programmable 1-bit Adaptive Logic Modules (each can function like a one-bit ALU), up to tens of thousands of configurable memory blocks, and tens of thousands of math engines, known as digital signal processing (DSP) blocks, that support variable precision floating-point and fixed-point operations. All these resources are connected by a mesh of programmable wires that can be activated on an as-needed basis.
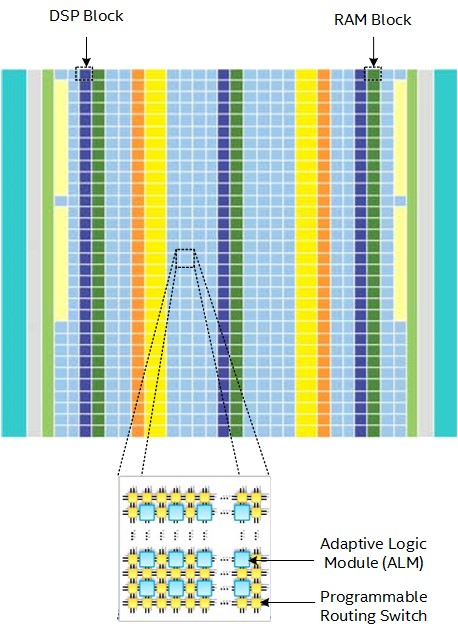
When software is “executed” on the FPGA, it is not executing in the same sense that compiled and assembled instructions execute on CPUs and GPUs. Instead, data flows through customized deep pipelines on the FPGA that match the operations expressed in the software. Because the dataflow pipeline hardware matches the software, control overhead is eliminated, which results in improved performance and efficiency.
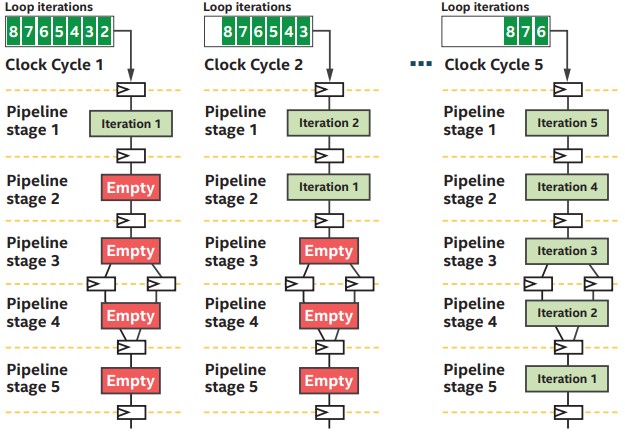
With CPUs and GPUs, instruction stages are pipelined, and new instructions start executing every clock cycle. With FPGAs, operations are pipelined so new instruction streams operating on different data start executing every clock cycle.

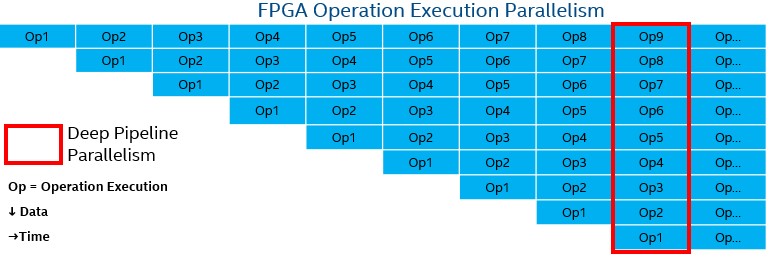
While pipeline parallelism is the primary form of parallelism for FPGAs, it can be combined with other types of parallelism. For example, data parallelism (SIMD), task parallelism (multiple pipelines), and superscalar execution (multiple independent instructions executing in parallel) can be utilized with pipeline parallelism to achieve maximum performance.
FPGA Advantages:
- Efficiency: Data processing pipeline tuned exactly to the needs of software. No need for control units, instruction fetch units, register writeback, and other execution overhead.
- Custom Instructions: Instructions not natively supported by CPUs/GPUs can be easily implemented and efficiently executed on FPGAs (e.g., bit manipulations).
- Data Dependencies across Parallel Work can be resolved without stalls to the pipeline.
- Flexibility: FPGAs can be reconfigured to accommodate different functions and data types, including non-standard data types.
- Custom On-Chip Memory Topology Tuned to Algorithm: Large-bandwidth, on-chip memory built to accommodate access pattern, thereby minimizing or eliminating stalls.
- Rich I/O: FPGA core can interact directly with various network, memory, and custom interfaces and protocols resulting in low and deterministic latency solutions.
Mapping of oneAPI and SYCL* to CPUs, GPUs, and FPGAs
Now that the basics of each architecture have been described, this section examines how oneAPI and SYCL execution map to the execution units of CPUs, GPUs, and FPGAs.
To learn more about SYCL, see the references at the end of this article.
| NDRange Kernel | Singel Task Kernel |
|---|---|
|
|
Above are two types of SYCL kernels: NDRange and single task. This section examines how these two kernels and their parallelism are executed on the different architectures.
On the left, the NDRange kernel lambda is launched with parallel_for in a data-parallel fashion across N work-items (threads) and partitioned into N/256 work-groups sized at 256 work-items each. NDRange kernels are inherently data parallel.
On the right, only a single thread is launched to execute the lambda expression, but inside the kernel there is a loop iterating through the data elements. With single_task, parallelism is derived across loop iterations.
CPU Execution
CPUs rely on several types of parallelism to achieve performance. SIMD data parallelism, instruction-level parallelism, and thread-level parallelism with multiple threads executing on different logical cores can all be leveraged. These types of parallelisms can be achieved with SYCL in the following ways:
- SIMD data parallelism:
- Each work-item (of the same work-group) can map to a CPU SIMD lane. Work-items (sub-group) execute together in a SIMD fashion.
- Vector data types can be used to explicitly specify SIMD operations.
- A compiler can perform loop vectorization to generate SIMD code. One loop iteration maps to a CPU SIMD lane. Multiple loop iterations execute together in SIMD fashion.
- CPU core and hyper-thread parallelism:
- Different work-groups can execute on different logical cores in parallel.
- A machine with 16 cores and 32 hyper-threads can execute 32 work-groups in parallel.
- Different work-groups can execute on different logical cores in parallel.
- Traditional instruction-level parallelism:
- Achieved through sophisticated CPU control, like traditional sequential software execution.
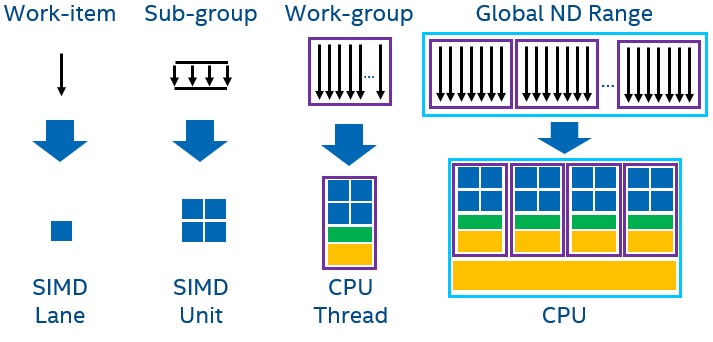
GPU Execution
GPUs rely on large data-parallel workloads to achieve performance. As a result, single-task kernels are rarely utilized, and NDRange kernels are needed to fully populate the GPU’s deep execution pipeline.
When executing the kernel on the GPU, every work-item is mapped to a SIMD lane. A sub-group is formed from work-items that execute in SIMD fashion, and sub-groups are mapped to the GPU EU or vector engine. Work-groups, which include work-items that can synchronize and share local data, are assigned for execution on compute units (aka. streaming multiprocessors, sub-slice, or Xe-core). Finally, the entire global NDRange of work-items maps to the entire GPU.
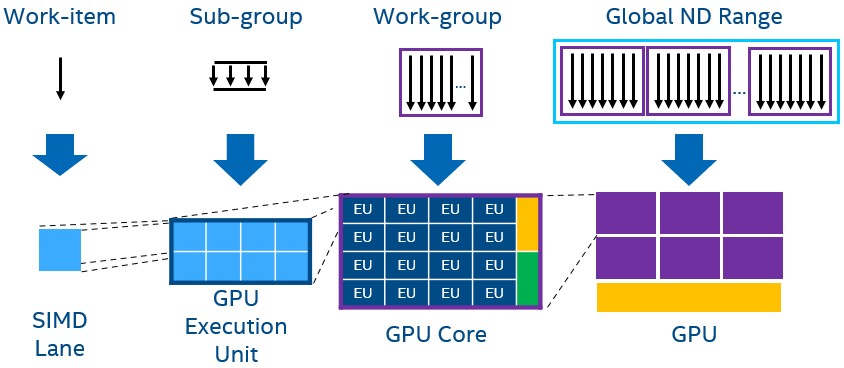
FPGA Execution
When kernels are compiled for the FPGA, the operations in the kernel are laid out spatially. Dependent kernel operations are deeply pipelined while independent operations are executed in parallel. An important benefit of pipelined implementation is that dependencies across neighboring work-items can be resolved simply by routing data from one pipeline stage back to an earlier stage without stalling the pipeline. The key to performance is to keep the deep pipeline fully occupied. Although performance can be extracted on the FPGA with either NDRange kernels or single task kernels, kernels that perform favorably on the FPGA are often expressed as single task kernels.
With single-task kernels, the FPGA attempts to pipeline loop execution. Every clock cycle, successive iterations of the loop enter the first stage of the pipeline. Dependencies across loop iterations expressed in the software can be resolved in the hardware by routing the output of one stage to the input of an earlier dependent stage.
With NDRange kernel execution, on each clock cycle a different work-item enters the first stage of the custom compute pipeline.
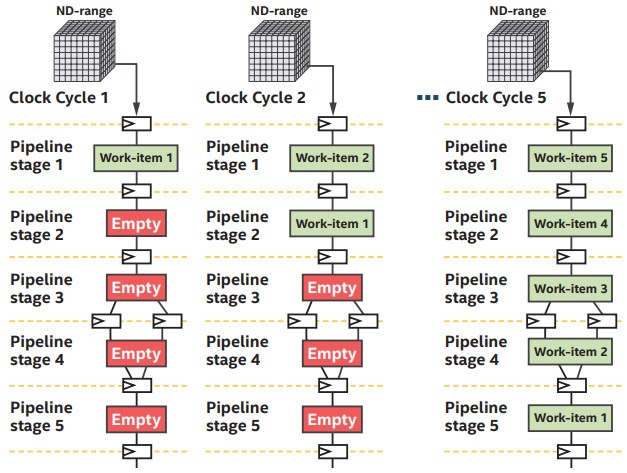
Unlike other architectures, with custom FPGA pipeline compute units developers have the additional option to tradeoff FPGA resources for throughput by increasing the SIMD width of the pipeline to process more work-items in parallel. For example, loop iterations can be unrolled to achieve data parallelism.
Library Support
One of the fastest ways to write performant software on CPUs, GPUs, and FPGAs is to leverage functionality provided by the oneAPI libraries. oneAPI provides libraries for different compute and data-intensive domains including deep learning, scientific computing, video analytics and media processing. Library support can help determine which device is best suited for an algorithm. Generally, CPUs have the most extensive library support, followed closely by GPUs, while FPGAs require the most manual implementation. If a library function is supported by multiple architectures, then properties of execution such as the amount of data to be processed or data locality (device on which the data to be processed resides) determine the optimal device to use.
This section explores the various oneAPI libraries and their device support. Library support is constantly evolving. Check the latest library documentation for the most up-to-date information.
oneAPI DPC++ Library (oneDPL) (CPU, GPU, and FPGA)
oneDPL can increase productivity for SYCL and DPC++ developers of parallel applications targeting multiple devices. It provides parallel C++ Standard Template Library (STL) functionality as well as access to additional parallel algorithms, iterators, ranged-based APIs, random number generators, tested standard C++ APIs, and others. oneDPL supports CPUs, GPUs, and FPGAs.
oneAPI Math Kernel Library (oneMKL) (CPU and GPU)
oneMKL improves performance with math routines that solve large computational problems. It provides BLAS and LAPACK linear algebra routines, fast Fourier transforms, vectorized math functions, random number generation functions, and other functionality. Currently, oneMKL supports CPUs and GPUs, but additional accelerator support may be added in the future.
oneAPI Threading Building Blocks (oneTBB) (CPU)
oneTBB is a C++ template library providing features to specify logical parallelism in algorithms for CPUs beyond those available in SYCL. The library can be used in combination with SYCL to split code execution between CPU and GPU.
oneAPI Data Analytics Library (oneDAL) (CPU and partial GPU support)
oneDAL helps speed up big data analysis by providing highly optimized algorithmic building blocks for all stages of data analytics (preprocessing, transformation, analysis, modeling, validation, and decision making) in batch, online, and distributed processing modes of computation. Although classically intended for CPUs, oneDAL provides SYCL API extensions that enable GPU usage for some of the algorithms.
oneAPI Deep Neural Network Library (oneDNN) (CPU, GPU)
oneDNN includes building blocks for deep learning applications and frameworks. Blocks include convolutions, pooling, LSTM, LRN, ReLU, and many more. This library is supported for both CPUs and GPUs.
oneAPI Collective Communications Library (oneCCL) (CPU, GPU)
oneCCL supports optimized primitives for communication patterns that occur in deep learning applications. It enables developers and researchers to train newer and deeper models faster.
oneAPI Video Processing Library (oneVPL) (CPU)
oneVPL is a programming interface for video decoding, encoding, and processing to build media pipelines. Currently, the library supports deployment on CPUs, GPUs, and other accelerators.
Summary of Current oneAPI Library Support
| oneDPL | oneMKL | oneTBB | oneDAL | oneDNN | oneCCL | oneVPL | |
|---|---|---|---|---|---|---|---|
| CPU | Y | Y | Y | Y | Y | Y | Y |
| GPU | Y | Y | Partial | Y | Y | Y | |
| FPGA | Y |
Identify Code Regions for GPU Offload
In a heterogeneous computing environment, identifying parts of an algorithm suitable for offload acceleration can be difficult. Even knowing the characteristics of an algorithm, predicting performance on an accelerator before partitioning and optimizing for the accelerator is challenging. The Intel® oneAPI Base Toolkit includes the Intel® Advisor Offload Advisor to help with exactly that.
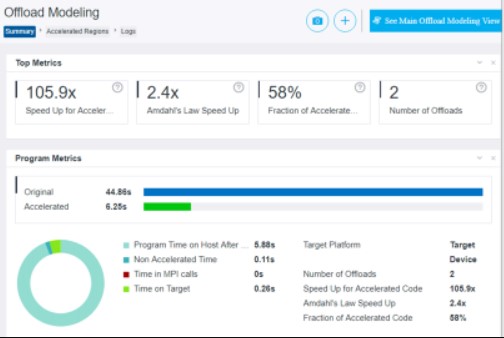
Intel Advisor is a design and analysis tool for achieving high application performance through efficient threading, vectorization, memory use, and offloading. It supports C, C++, SYCL, Fortran, OpenMP™, and Python. ItsOffload Advisor feature is designed to help us understand which section of code would benefit from GPU offloading. Before refactoring code for execution on the GPU, the Offload Advisor can:
- Identify offload opportunities.
- Quantify potential performance speedup from GPU offloading.
- Estimate data-transfer costs and provide guidance on data-transfer optimization.
- Locate bottlenecks and estimate potential performance.
CPUs are inherently different from GPUs, and porting CPU code to optimal GPU code can require significant work. The Offload Advisor is an invaluable productivity tool when determining suitable algorithms for GPU offloading before performing any porting work.
Example Applications
This section examines some example applications for each of the architectures. Predicting which algorithm is suitable for which accelerator architecture depends on application characteristics and system bottlenecks.
GPU Workload Example
GPUs are massively data-parallel accelerators. When the dataset is large enough to mask the offload data-transfer overhead, dependencies across the data can be mostly avoided, and the data flow is mostly non-divergent, GPUs are the accelerator of choice.
Workloads that fully utilize GPU advantages often exhibit the following characteristics:
- Naturally data parallel where the same operations are applied across data
- Problem size is large so that the large number of GPU processing elements are utilized
- Hides main computer memory to GPU memory data transfer time
- Little or no dependency across the data being processed
- Output of processing one data point does not depend on the output of another data point
- Mostly non-divergent control flow (minimal branching and loop divergence)
- Recursive functions often need to be rewritten
- Matches data-types supported by the GPU
- Processing strings, for example, can be slow
- Ordered data access
- GPUs are optimized for continuous reads and writes
- Algorithm that access data in a random order often needs to be rewritten
Image processing, for example, is ideally suited for GPUs. There are typically large numbers of pixels to process. At each pixel, the same basic operations are applied and output pixels do not depend on each other.
Another popular workload for GPUs is deep learning applications. Below is the equation to calculate one output feature map of a convolution layer in a convolutional neural network (CNN) used in computer vision applications.
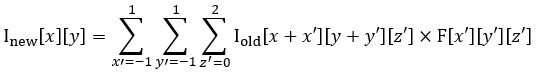
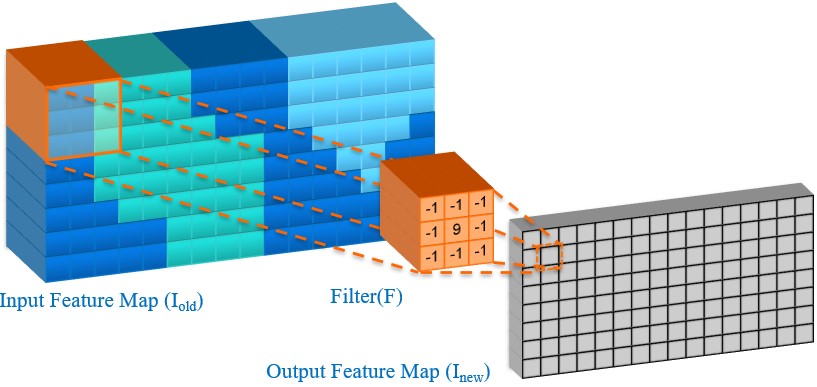
To calculate the output feature map, a 3D filter is convolved across the width and height of the multi-channel input feature map, computing the sliding dot product. Hundreds of feature maps may be calculated in a single CNN layer and hundreds of layers may need to be calculated in a forward pass of a CNN.
The GPUs can efficiently process CNNs because the dot products of a single layer are independent, the calculations do not involve branches, there is large amount of compute in each layer, and the amount of computation scales faster than the amount of input and output data that needs to be transferred.
Other typical application of GPUs can be found in AI, data analysis, climate modeling, genetics, and physics.
FPGA Workload Example
The efficient, custom, deep pipeline of FPGA architecture is suitable for algorithms that are easily expressed in serial code and may have dependencies across data elements. These types of algorithms do not execute well on GPU’s data parallel architecture.
One example is Gzip compression. Gzip can be handled with three kernels. First is the LZ77 data compression kernel, which searches and eliminates duplicate patterns in a file. The second kernel performs Huffman coding, which encodes the output of LZ77 to generate the result. Thirdly, a CRC32 error-detecting kernel operates on the input independent of the other two kernels.
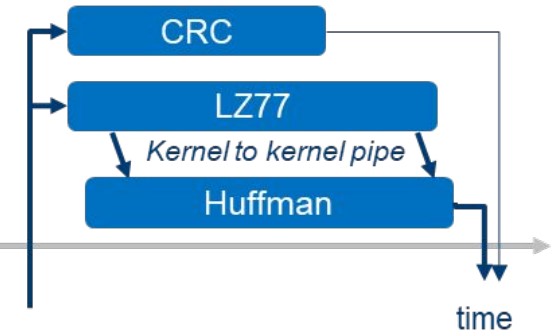
This algorithm is suitable for execution on the FPGA for several reasons:
- FPGAs allow the three kernels to execute simultaneously, as each has its own dedicated custom compute pipeline.
- For LZ77, the sequential search for duplicates cannot be easily parallelized with a NDRange kernel due to dependencies (e.g., search results of the second half of the file depends on the first). It can be implemented with a single-task kernel iterating symbol-by-symbol on the entire file, where dependencies are resolved using custom routing between iterations.
- FPGA custom on-chip memory architecture allows large amounts of dictionary lookups to occur simultaneously without stall.
- Huffman codes are not byte-aligned; the encoding requires bit manipulations that are efficiently implemented on the FPGA.
- FPGAs allow individual data to be piped between simultaneously executing kernels. This allows LZ77 and Huffman encoding kernels to execute at the same time.
You can find more information about this implementation and the code sample at the article, Accelerating Compression on Intel® FPGAs.
Many other workloads are suitable for the FPGA for similar reasons. Image lossless compression, genomics sequencing, database analytics acceleration, machine learning, and financial computing are all good candidates for FPGA acceleration.
CPU and Heterogeneous Workload
CPUs are the most widely used generic processors in computing. Every application that leverages GPUs or FPGAs for compute acceleration still requires a CPU to handle task orchestration. CPUs are the default choice when an algorithm cannot efficiently leverage the capabilities of GPUs and FPGAs. While not as compute-dense as GPUs, and not as compute-efficient as FPGAs, CPUs can still have superior performance in compute applications when vector, memory, and thread optimizations are applied. This is especially true if the requirements for offloading are not met.
In a heterogeneous environment, even if the main computation is done on an accelerator, the CPU can improve performance on other code portions. With oneAPI, a single application can leverage cross-architecture performance and take advantage of the benefits of CPUs, GPUs, and FPGAs.
Summary
Today’s compute systems are heterogeneous and include CPUs, GPUs, FPGAs, and other accelerators. The different architectures exhibit varied characteristics that can be matched to specific workloads for the best performance. Having multiple types of compute architectures leads to different programming and optimization needs. oneAPI and SYCL provide a programming model, whether through direct programming or libraries, that can be utilized to develop software tailored to each of the architectures.
In a nutshell:
- GPU architecture is the most compute dense. If a kernel is data parallel, simple, and requires lots of computation, it will likely run best on the GPU.
- FPGAs architecture is the most compute efficient. While FPGAs and the generated custom compute pipelines can be used to accelerate almost any kernel, the spatial nature of the FPGA implementation means available FPGA resources can be a limit.
- CPU architecture is the most flexible with the broadest library support. Modern CPUs support many types of parallelism and can be used effectively to complement other accelerators.
If you would like to experience each of the compute architectures discussed in this article, try oneAPI and SYCL in a heterogeneous environment including modern CPUs, GPUs, and FPGAs with the Intel® DevCloud. There, you’ll be able to develop, test, and run your workloads for free on a cluster of the latest Intel® hardware and software.
References
Data Parallel C++: Mastering DPC++ for Programming of Heterogeneous Systems using C++ and SYCL
oneAPI Specification and Documentation on oneapi.com
Intel® oneAPI Programming Guide
Intel® oneAPI DPC++ FPGA Optimization Guide
Optimize Your GPU Application with Intel® oneAPI Base Toolkit
Intel® DevCloud
See Related Content
Tech Articles & Blogs
- What is oneAPI: Demystifying oneAPI for Developers
- oneAPI – The Cross-Architecture, Multi-Vendor Path to Accelerated...
- The Case for SYCL: ISO C++ Is Not Enough for Heterogeneous Compute
- CUDA, SYCL, Codeplay, and oneAPI: A Functional Test Walkthrough
- Expanding language and accelerator support in oneAPI
On-Demand Webinars
- Compare CPU, GPU, and FPGA Benefits on Heterogeneous Workloads
- Intel's oneAPI Initiative: an In-Depth Tech Talk
- Accelerate Video Processing on More CPUs, GPUs, and Accelerators
- Find CPU & GPU Performance Headroom using Roofline Analysis
- From Slow to Go: Optimize FPGA Development & Performance
- Streamline FPGA Development with oneAPI Shared Libraries
Get the Software
Intel® oneAPI Base Toolkit
Get started with this core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures.