Intel® High Level Synthesis Compiler Pro Edition: Best Practices Guide
ID
683152
Date
1/23/2025
Public
1. Discontinuation of the Intel® HLS Compiler
2. Intel® HLS Compiler Pro Edition Best Practices Guide
3. Best Practices for Coding and Compiling Your Component
4. FPGA Concepts
5. Interface Best Practices
6. Loop Best Practices
7. fMAX Bottleneck Best Practices
8. Memory Architecture Best Practices
9. System of Tasks Best Practices
10. Datatype Best Practices
11. Advanced Troubleshooting
A. Intel® HLS Compiler Pro Edition Best Practices Guide Archives
B. Document Revision History for Intel® HLS Compiler Pro Edition Best Practices Guide
6.1. Reuse Hardware By Calling It In a Loop
6.2. Parallelize Loops
6.3. Construct Well-Formed Loops
6.4. Minimize Loop-Carried Dependencies
6.5. Avoid Complex Loop-Exit Conditions
6.6. Convert Nested Loops into a Single Loop
6.7. Place if-Statements in the Lowest Possible Scope in a Loop Nest
6.8. Declare Variables in the Deepest Scope Possible
6.9. Raise Loop II to Increase fMAX
6.10. Control Loop Interleaving
5.1.3. Avalon® Memory Mapped Agent Memories
Depending on your component, you can sometimes optimize the memory structure of your component by placing your component parameters in Avalon® Memory Mapped ( Avalon® MM) agent memories.
Agent memories are owned by the component and expose an MM agent interface for an MM Host to read from and write to.
When you allocate an agent memory, you must define its size. Defining the size puts a limit on how large a value of N that the component can process. In this example, the RAM size is 1024 words. This RAM size means that N can have a maximal size of 1024 words.
The vector addition component example can be coded with an Avalon® MM agent interface as follows:
component void vector_add(
hls_avalon_agent_memory_argument(1024*sizeof(int)) int* a,
hls_avalon_agent_memory_argument(1024*sizeof(int)) int* b,
hls_avalon_agent_memory_argument(1024*sizeof(int)) int* c,
int N) {
#pragma unroll 8
for (int i = 0; i < N; ++i) {
c[i] = a[i] + b[i];
}
}
The following diagram shows the Function View in the System Viewer that is generated when you compile this example.
Figure 26. System Viewer Function View of vector_add Component with Avalon® MM Agent Interface
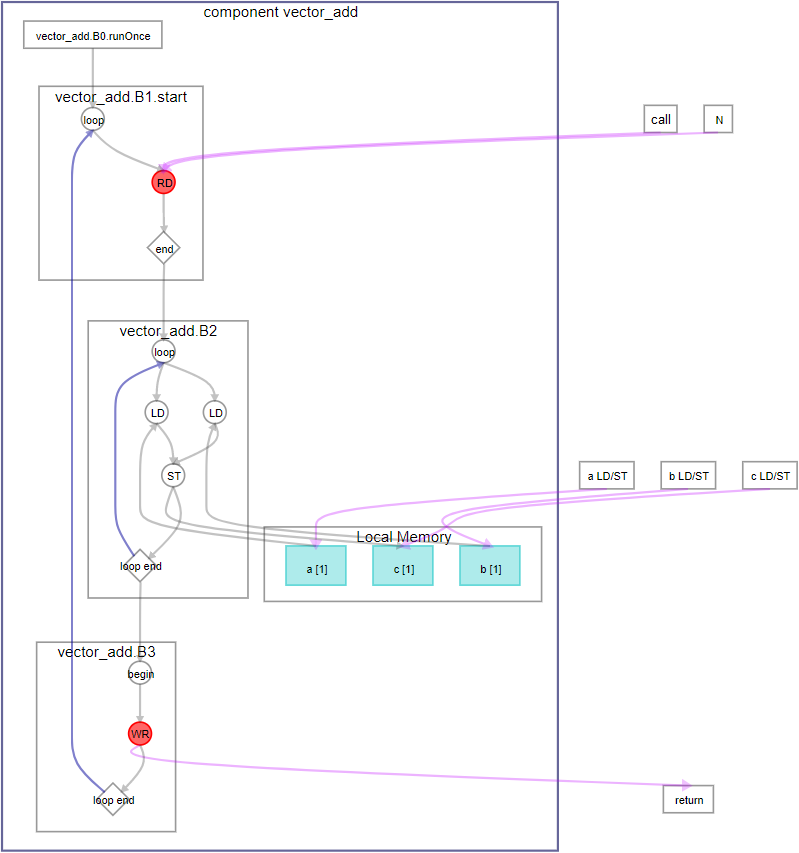
Compiling this component with an Quartus® Prime compilation flow targeting an Arria® 10 device results in the following QoR metrics:
The QoR metrics show by changing the ownership of the memory from the system to the component, the number of ALMs used by the component are reduced, as is the component latency. The fMAX of the component is increased as well. The number of RAM blocks used by the component is greater because the memory is implemented in the component and not the system. The total system RAM usage (not shown) should not increase because RAM usage shifted from the system to the FPGA RAM blocks.
| QoR Metric | Pointer | Avalon® MM Host | Avalon® MM Agent |
|---|---|---|---|
| ALMs | 15593.5 | 643 | 490.5 |
| DSPs | 0 | 0 | 0 |
| RAMs | 30 | 0 | 48 |
| fMAX (MHz)2 | 298.6 | 472.37 | 498.26 |
| Latency (cycles) | 24071 | 142 | 139 |
| Initiation Interval (II) (cycles) | ~508 | 1 | 1 |
| 1The compilation flow used to calculate the QoR metrics used Quartus® Prime Pro Edition Version 17.1. |
| 2The fMAX measurement was calculated from a single seed. |