Intel® High Level Synthesis Compiler Pro Edition: Best Practices Guide
A newer version of this document is available. Customers should click here to go to the newest version.
5.2.1. Pipeline Loops

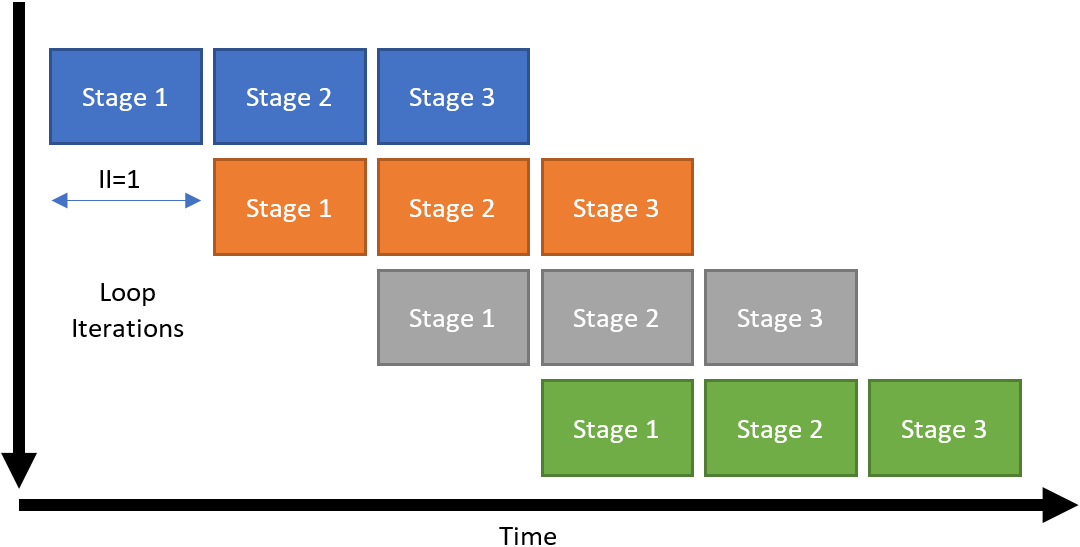
This loop is pipelined with a loop initiation interval (II) of 1. An II of 1 means that there is a delay of 1 clock cycle between starting each successive loop iteration.
The Intel® HLS Compiler Pro Edition attempts to pipeline loops by default, and loop pipelining is not subject to the same constant iteration count constraint that loop unrolling is.
Not all loops can be pipelined as well as the loop shown in Pipelined loop with three stages and four iterations, particularly loops where each iteration depends on a value computed in a previous iteration.
For example, consider if Stage 1 of the loop depended on a value computed during Stage 3 of the previous loop iteration. In that case, the second (orange) iteration could not start executing until the first (blue) iteration had reached Stage 3. This type of dependency is called a loop-carried dependency.
In this example, the loop would be pipelined with II=3. Because the II is the same as the latency of a loop iteration, the loop would not actually be pipelined at all. You can estimate the overall latency of a loop with the following equation:
where is the number of cycles the loop takes to execute and is the number of cycles a single loop iteration takes to execute.
The Intel® HLS Compiler Pro Edition supports pipelining nested loops without unrolling inner loops. When calculating the latency of nested loops, apply this formula recursively. This recursion means that having II>1 is more problematic for inner loops than for outer loops. Therefore, algorithms that do most of their work on an inner loop with II=1 still perform well, even if their outer loops have II>1.