Developer Guide
FPGA Optimization Guide for Intel® oneAPI Toolkits
ID
767853
Date
7/13/2023
Public
A newer version of this document is available. Customers should click here to go to the newest version.
FPGA Optimization Guide for Intel® oneAPI Toolkits
Introduction To FPGA Design Concepts
Analyze Your Design
Optimize Your Design
FPGA Optimization Flags, Attributes, Pragmas, and Extensions
Quick Reference
Additional Information
Document Revision History for the FPGA Optimization Guide for Intel® oneAPI Toolkits
Refactor the Loop-Carried Data Dependency
Relax Loop-Carried Dependency
Transfer Loop-Carried Dependency to Local Memory
Minimize the Memory Dependencies for Loop Pipelining
Unroll Loops
Fuse Loops to Reduce Overhead and Improve Performance
Optimize Loops With Loop Speculation
Remove Loop Bottlenecks
Shannonization to Improve FMAX/II
Optimize Inner Loop Throughput
Improve Loop Performance by Caching On-Chip Memory
Global Memory Bandwidth Use Calculation
Manual Partition of Global Memory
Partitioning Buffers Across Different Memory Types (Heterogeneous Memory)
Partitioning Buffers Across Memory Channels of the Same Memory Type
Ignoring Dependencies Between Accessor Arguments
Contiguous Memory Accesses
Static Memory Coalescing
Specify Schedule FMAX Target for Kernels (-Xsclock=<clock target>)
Create a 2xclock Interface (-Xsuse-2xclock)
Disable Burst-Interleaving of Global Memory (-Xsno-interleaving=<global_memory_name>)
Force Ring Interconnect for Global Memory (-Xsglobal-ring)
Force a Single Store Ring to Reduce Area (-Xsforce-single-store-ring)
Force Fewer Read Data Reorder Units to Reduce Area (-Xsnum-reorder)
Disable Hardware Kernel Invocation Queue (-Xsno-hardware-kernel-invocation-queue)
Modify the Handshaking Protocol Between Clusters (-Xshyper-optimized-handshaking)
Disable Automatic Fusion of Loops (-Xsdisable-auto-loop-fusion)
Fuse Adjacent Loops With Unequal Trip Counts (-Xsenable-unequal-tc-fusion)
Pipeline Loops in Non-task Kernels (-Xsauto-pipeline)
Control Semantics of Floating-Point Operations (-fp-model=<value>)
Modify the Rounding Mode of Floating-point Operations (-Xsrounding=<rounding_type>)
Global Control of Exit FIFO Latency of Stall-free Clusters (-Xssfc-exit-fifo-type=<value>)
Enable the Read-Only Cache for Read-Only Accessors (-Xsread-only-cache-size=<N>)
Control Hardware Implementation of the Supported Data Types and Math Operations (-Xsdsp-mode=<option>)
Generate Register Map Wrapper (-Xsregister-map-wrapper-type)
Digital Signal Processing (DSP) Block
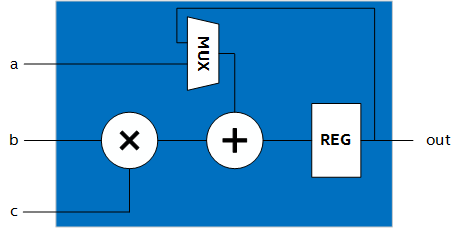
A digital signal processing (DSP) block implements specific arithmetic operations (addition and multiplication) that reduce the need to build equivalent logic from general-purpose ALMs. Some FPGAs support floating-point arithmetic in DSP blocks in addition to integer/fixed-point arithmetic. For more information, refer to Digital Signal Processing.
The following figure illustrates a simplified three-input DSP block consisting of a multiplier (×) and an adder (+):
DSP Block
Parent topic: FPGA Architecture Overview