In my last post, An Introduction to Accelerator and Parallel Programming, we talked about the basics of parallel programming, including some simple ways you can take a program and run it on multiple CPUs or an accelerator. Of course, that post only scratched the surface of parallel and accelerated programming challenges.
In general, these types of programming use an asynchronous model of execution, meaning that multiple computations will be happening in a system at the same time. The challenge is ensuring that this execution is fast and correct.
In this post, I will talk about making sure programs run correctly using synchronization.
Threads
First, a little detour into the term “thread”, mostly because it will be easier to type thread versus a part of your program that is executing simultaneously with another part of your program and doing so over and over on a piece of hardware.
In the context of your parallel program, you write your code, and then this code may be run on multiple processors at the same time. Each piece of simultaneously running code is a thread. This may sound complex, but fortunately, most programming paradigms allow us to focus on what to parallelize and how we want it parallelized without having to focus on the nitty-gritty details of using threads.
Synchronization
Synchronization constructs enforce an ordering of execution for our threads. As we allow threads to run, there are a variety of things we need to consider to make sure our program behaves the way we expect, including:
- Are multiple threads trying to access a shared resource at the same time?
- Do multiple threads need to complete their work before moving to the next part of the program?
- Are there issues that will cause our program to hang such that all threads are waiting for each other for some reason?
Why Does Synchronization Matter?
Let’s take a simple example.
Imagine we want to do something simple like count the number of people in a stadium and we have three people doing the counting. A simple algorithm would be:
- split the stadium into sections
- assign each section to one of the three people counting
- have each person count the people in their assigned sections
- sum the value from each of the three people into one total for the entire stadium
This seems straightforward, but there is a catch: To sum the values in step 4, each person has to read what the current total is, add to that value, and then write the updated total on the paper for everyone else to see. So in reality, it is actually three actions that must happen (read, add, write) to update the total.
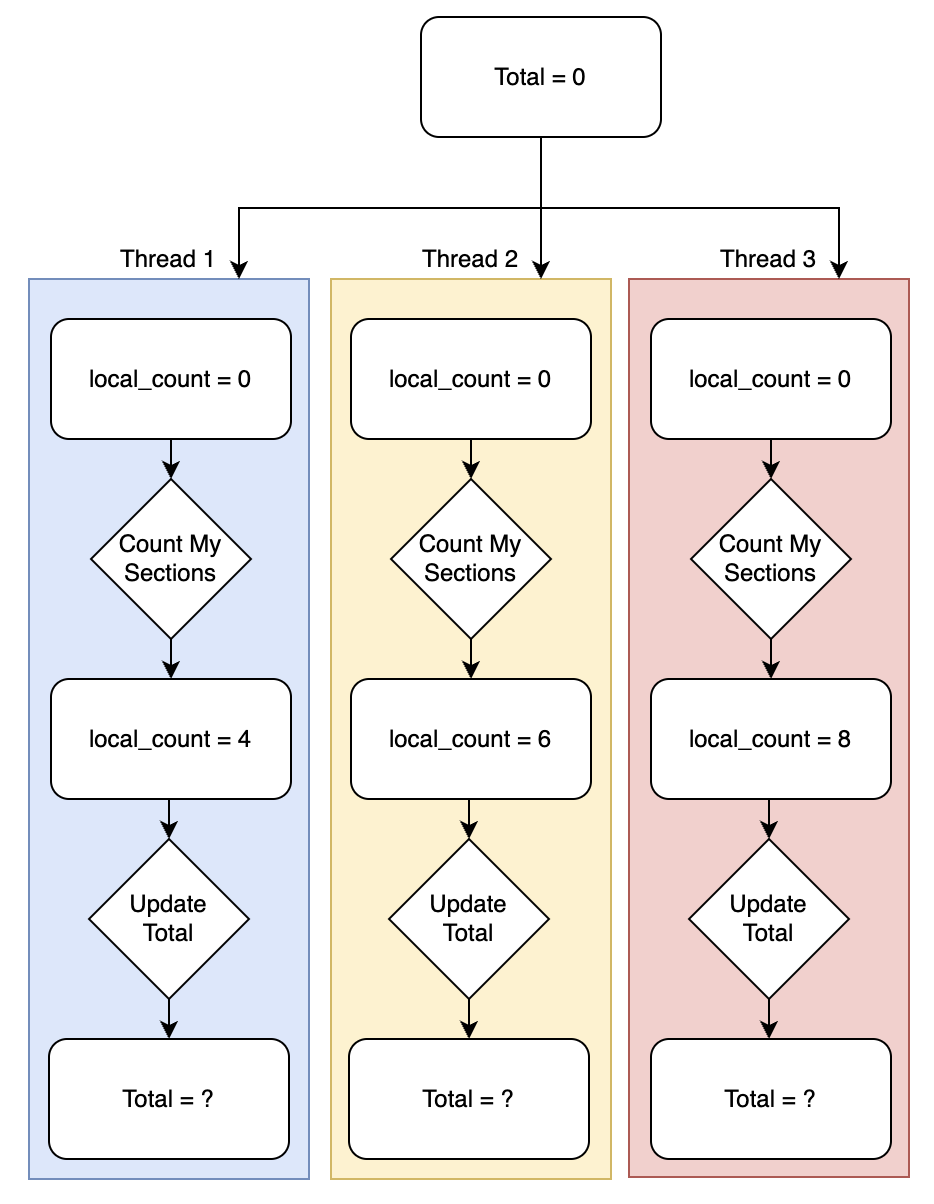
Figure 1. Synchronization Example
Per Figure 1, the correct answer to this problem is 18. Each thread has a variable, local_count that is created and used only in that thread, which means counting the sections is independent of other threads. However, when threads go to update the shared total value, there is a potential issue.
Let us suppose Thread 1 and Thread 2 simultaneously attempt to update Total. It is possible they both read a value of 0 for the total and then add their local_count to it, meaning they think the updated value for Total should be 0+4=4 or 0+6=6, respectively. When they go to update Total, the output could be 4 or 6.
In either case, the outcome after both threads update the total should actually be 10. This is what we call a data race and why synchronization is important to correctness. We actually need to ensure that the update to the shared variable is done one at a time. Here’s a simple example of what this might look like using OpenMP:
#include <iostream>
#include <thread>
#include <chrono>
int main()
{
int total = 0;
auto start = std::chrono::steady_clock::now();
#pragma omp parallel sections
{
#pragma omp section
{
int local_count = 0;
std::this_thread::sleep_for(std::chrono::milliseconds{500});
local_count = 4;
#pragma omp critical
total += local_count;
}
#pragma omp section
{
int local_count = 0;
std::this_thread::sleep_for(std::chrono::milliseconds{500});
local_count = 6;
#pragma omp critical
total += local_count;
}
#pragma omp section
{
int local_count = 0;
std::this_thread::sleep_for(std::chrono::milliseconds{500});
local_count = 8;
#pragma omp critical
total += local_count;
}
}
auto end = std::chrono::steady_clock::now();
std::cout << "Total=" << total << std::endl
<< "Elapsed time in milliseconds: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()
<< " ms" << std::endl;
return 0;
}
count_sections_omp.cpp
There are three distinct OpenMP compiler directives at work in this example.
omp parallel sections— tells the compiler to run each section within the following block of code in parallel (aka each section on its thread). The sections pragma also waits until each individual section in the block is completed.omp section— tells the compiler the following block of code is a complete section that can be run on a thread.omp critical— tells the compiler to allow only one thread to execute the following block of code, which is just the one-line addition to the total.
To compile the code, I used the Intel® oneAPI DPC++/C++ Compiler, which supports OpenMP, using the following commands:
> icx count_sections_omp.cpp -o serial.exe
> icx -fopenmp count_sections_omp.cpp -o parallel.exe
The first command compiles without OpenMP enabled, while the second command tells the compiler to use the OpenMP pragmas. My test system in this case is my HP Envy 16" laptop powered by an Intel® Core™ i7–12700H processor with 32GB of RAM. Running the two executables looks like this:
>serial.exe
Total=18
Elapsed time in milliseconds: 1570 ms
>parallel.exe
Total=18
Elapsed time in milliseconds: 520 ms
You can see the difference in runtime between the parallelized code and the code running on only one CPU.
Just for fun, I removed the #pragma omp critical directives from my code and ran it a few times. After a few tries, I got this output:
>parallel.exe
Total=14
Elapsed time in milliseconds: 520 ms
In this case, you can see that the value from the first section (with a value of 4) was somehow missed, since each thread did not add to the total in a serialized fashion.
Resource sharing synchronization
There are quite a few synchronization constructs that protect access to resources, and I will not be able to give code examples for all of them. So to allow you to dive in a little more, I’ll list a few and what they are generally used for:
- critical section — allows only one thread to run code protected by the critical section at once.
- lock/mutex — protects a code section by asking each thread to explicitly request access via a lock before running some code. This is different from a critical section as there are cases where multiple threads may access a shared resource simultaneously (e.g., a reader/writer paradigm to be discussed below).
- semaphores — given a predefined number
N; this allows onlyNusers to run their code simultaneously.
Note that synchronization, if used inappropriately, can result in incorrect results and issues where threads fail to make progress or hang.
The Reader/Writer Paradigm
One of the parallel programming paradigms often used is that of the reader/writer. This synchronization is used when there are two types of users accessing some shared values in memory:
- reader — needs to know the shared value
- writer — needs to update a shared value
If you think about it, multiple readers can look at a value simultaneously, as they will always see the same value as the rest of the readers. However, when a writer needs to update the value, it must prevent others from reading or writing the value. This ensures that the value is always consistent across all readers and writers in the program.
To make this more concrete, let’s look at an example of what this looks like in SYCL and how the usage of the reader/writer affects the behavior and performance of your program.
Reader/Writer SYCL Example
Let’s look at how SYCL uses reader/writer synchronization to control access to an array.
#include <CL/sycl.hpp>
#define WORK_ITERS 580000000
#pragma clang optimize off
void doWork()
{
float x = 1.0f;
for (auto i = 0; i < WORK_ITERS; ++i) {
x = x + 2;
}
}
void Read(sycl::queue &q, int index, sycl::buffer<float> &buf) {
// Submit a command group to the queue by a lambda function that contains the
// data access permission and device computation (kernel).
q.submit([&](sycl::handler &h) {
// The accessor is used to store (with read permission) the data.
auto acc = buf.get_access<sycl::access::mode::read>(h);
// Use parallel_for to run in parallel on device. This
// executes the kernel.
// 1st parameter is the number of work items.
// 2nd parameter is the kernel, a lambda that specifies what to do per
// work item. The parameter of the lambda is the work item id.
h.single_task<class MyRead>([=](){ doWork(); });
});
}
void Write(sycl::queue &q, int index, int value, sycl::buffer<float> &buf) {
// Submit a command group to the queue by a lambda function that contains the
// data access permission and device computation (kernel).
q.submit([&](sycl::handler &h) {
// The accessor is used to store (with write permission) the data.
auto acc = buf.get_access<sycl::access::mode::write>(h);
// Use parallel_for to run in parallel on device. This
// executes the kernel.
// 1st parameter is the number of work items.
// 2nd parameter is the kernel, a lambda that specifies what to do per
// work item. The parameter of the lambda is the work item id.
h.single_task<class MyWrite>([=](){ acc[index] = value; doWork(); });
});
}
rw.hpp
You can see the read and write functions are basically the same. Some key things to understand:
- line 18 —
Read()creates asycl::access::mode::readaccessor - line 34 —
Write()creates asycl::access::mode::writeaccessor - lines 16 and 32 — submit to the queue of the compute device of choice. This is asynchronous, so the code returns before the task is completed
- lines 25 and 41 — put a single task into the queue to be executed
Also, to make the test more understandable, I set the doWork() function to run for about one second on my particular machine by turning the WORK_ITERS variable. If you test this yourself, you may want to try adjusting that to make the test faster or slower.
Now that we have our core read and write functions, let’s look at how the read versus write access mode affects a program:
#include <CL/sycl.hpp>
#include <iostream>
#include <chrono>
#include "rw.hpp"
class MyRead;
class MyWrite;
#define NUM_ACCOUNTS 8
int main()
{
std::vector<float> accounts(NUM_ACCOUNTS);
auto buf = sycl::buffer<float>(accounts.data(), sycl::range<1>{NUM_ACCOUNTS});
// The default device selector will select the most performant device.
sycl::default_selector d_selector;
sycl::queue q(d_selector);
// Print out the device information used for the kernel code.
std::cout << "Running on device: "
<< q.get_device().get_info<sycl::info::device::name>() << "\n";
auto start = std::chrono::steady_clock::now();
// Read the value of all accounts
for (auto i = 0; i < NUM_ACCOUNTS; ++i)
{
Read(q, i, buf);
}
// Do a write
for (auto i = 0; i < NUM_ACCOUNTS; ++i)
{
Write(q, i, i*10, buf);
}
// Read the value of all accounts
for (auto i = 0; i < NUM_ACCOUNTS; ++i)
{
Read(q, i, buf);
}
q.wait();
auto end = std::chrono::steady_clock::now();
// validate output which should be account value == index
bool isCorrect = true;
for (auto i = 0; i < NUM_ACCOUNTS; ++i)
{
if (accounts[i] != i*10)
isCorrect = false;
}
if (isCorrect)
std::cout << "Pass" << std::endl;
else
std::cout << "Fail" << std::endl;
std::cout << "Elapsed time in milliseconds: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()
<< " ms" << std::endl;
return 0;
}
read_write_sycl.cpp
For this program, the lines of interest are 25-41, and each loop iterates NUM_ACCOUNTS (8) times. Considering how reader/writer synchronization works, the time to run this should be:
- lines 25–28: perform 8 reads of our buffer (1 second, happen in parallel)
- lines 31–34: perform 8 writes of our buffer (8 seconds, runs in order)
- lines 37–40: perform 8 writes of our buffer (1 second, happen in parallel)
Note that line 41 causes the program to wait for all the asynchronous operations in the queue to complete before proceeding.
Once again, I used the Intel DPC++ Compiler to compile my code and run it:
>icx -fsycl read_write_sycl.cpp
>read_write_sycl.exe
Running on device: 12th Gen Intel(R) Core(TM) i7-12700H
Pass
Elapsed time in milliseconds: 11105 ms
Our elapsed runtime is close to our expected value of 10 seconds.
Reader/Writer versus Critical Section
To understand the value of the reader/writer, imagine if instead of the reader/writer construct, we used a locking mechanism where both a read and write are treated as needing exclusive access.
To simulate this, I updated line 18 in my Read() as follows to use a write lock (single access at a time):
auto acc = buf.get_access<sycl::access::mode::read>(h);
auto acc = buf.get_access<sycl::access::mode::write>(h);
Recompiling my code and re-running it, I get the following output:
>read_write_sycl.exe
Running on device: 12th Gen Intel(R) Core(TM) i7–12700H
Pass
Elapsed time in milliseconds: 24035 ms
Comparing how the code should run versus the reader/writer code, the breakdown is as follows:
- lines 25–28: perform 8 reads of our buffer (8 seconds, runs in order)
- lines 31–34: perform 8 writes of our buffer (8 seconds, runs in order)
- lines 37–40: perform 8 writes of our buffer (8 seconds, runs in order)
This would suggest a reader/writer is always better, but that of course is not true. A reader/writer lock is a more complicated synchronization construct that has more runtime overhead to implement, so keep that in mind as you choose what synchronization to use.
Conclusion
Accelerator and parallel programming can give us faster applications and programs when used correctly. But as with most things in life, benefits do not always come for free. In this case, as we look to run our programs on ever faster and more diverse compute hardware, we must also learn and understand APIs that help us face the challenges accelerator and parallel computing present.
This post just scratches the surface of synchronization and the pitfalls of accelerator programming. Next time I’ll talk about why having a basic understanding of your target accelerator architecture may matter to you as you program for performance.
Want to Connect?
If you want to see what random tech news I’m reading, you can follow me on Twitter. Also, check out Code Together, an Intel podcast for developers that I host where we talk tech.
See Related Content
Technical Articles & Blogs
- Efficient Heterogeneous Parallel Programming using OpenMP
- Heterogeneous Processing Requires Data Parallelization
- More Productive and Performant C++ Programming with oneDPL
On-Demand Webinars
- Reduce Cross-platform Programming Efforts with oneDPL
- Migrate Your Existing CUDA Code to Data Parallel C++
- Tips to Improve Heterogeneous Application Performance
Get the Software
Get started with this core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures.