In some cases, offloading computations to an accelerator like a GPU means that the host CPU sits idle until the offloaded computations are finished. However, using the CPU and GPU resources simultaneously can improve the performance of an application. In OpenMP® programs that take advantage of heterogenous parallelism, the master clause can be used to exploit simultaneous CPU and GPU execution. In this article, we will show you how to do CPU+GPU asynchronous calculation using OpenMP.
The SPEC ACCEL 514.pomriq MRI reconstruction benchmark is written in C and parallelized using OpenMP. It can offload some calculations to accelerators for heterogenous parallel execution. In this article, we divide the computation between the host CPU and a discrete Intel® GPU such that both processors are kept busy. We’ll also use Intel VTune™ Profiler to measure CPU and GPU utilization and analyze performance.
We’ll look at five stages of heterogeneous parallel development and performance tuning:
- Looking for appropriate code regions to parallelize
- Parallelizing these regions so that both the CPU and GPU are kept busy
- Finding the optimal work distribution coefficient
- Launching the heterogeneous parallel application with this distribution coefficient
- Measuring the performance improvement.
Initially, the parallel region only runs on the GPU while the CPU sits idle (Figure 1). As you can see, only the “OMP Primary Thread” is executing on the CPU while the GPU is fully occupied (GPU Execution Units→EU Array→Active) with the ComputeQ offloaded kernel.
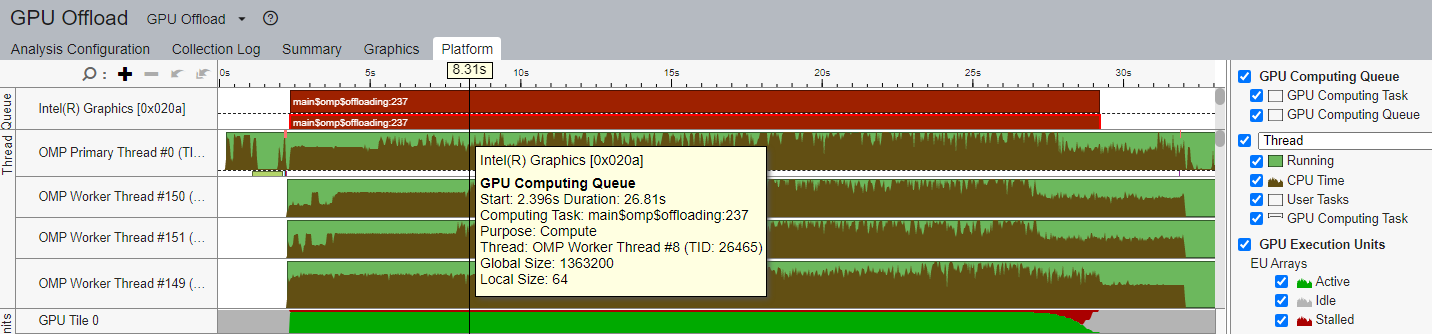
Figure 1. Profile of the initial code using Intel VTune Profiler
After examining the code, we decided to duplicate each array and each executed region so that the first copy is executed on the GPU and the second is executed on the CPU. The master thread uses the OpenMP target directive to offload work to the GPU. This is shown schematically in Figure 2. The nowait directives avoid unnecessary synchronization between the threads running on the CPU and GPU. They also improve load balance among the threads.
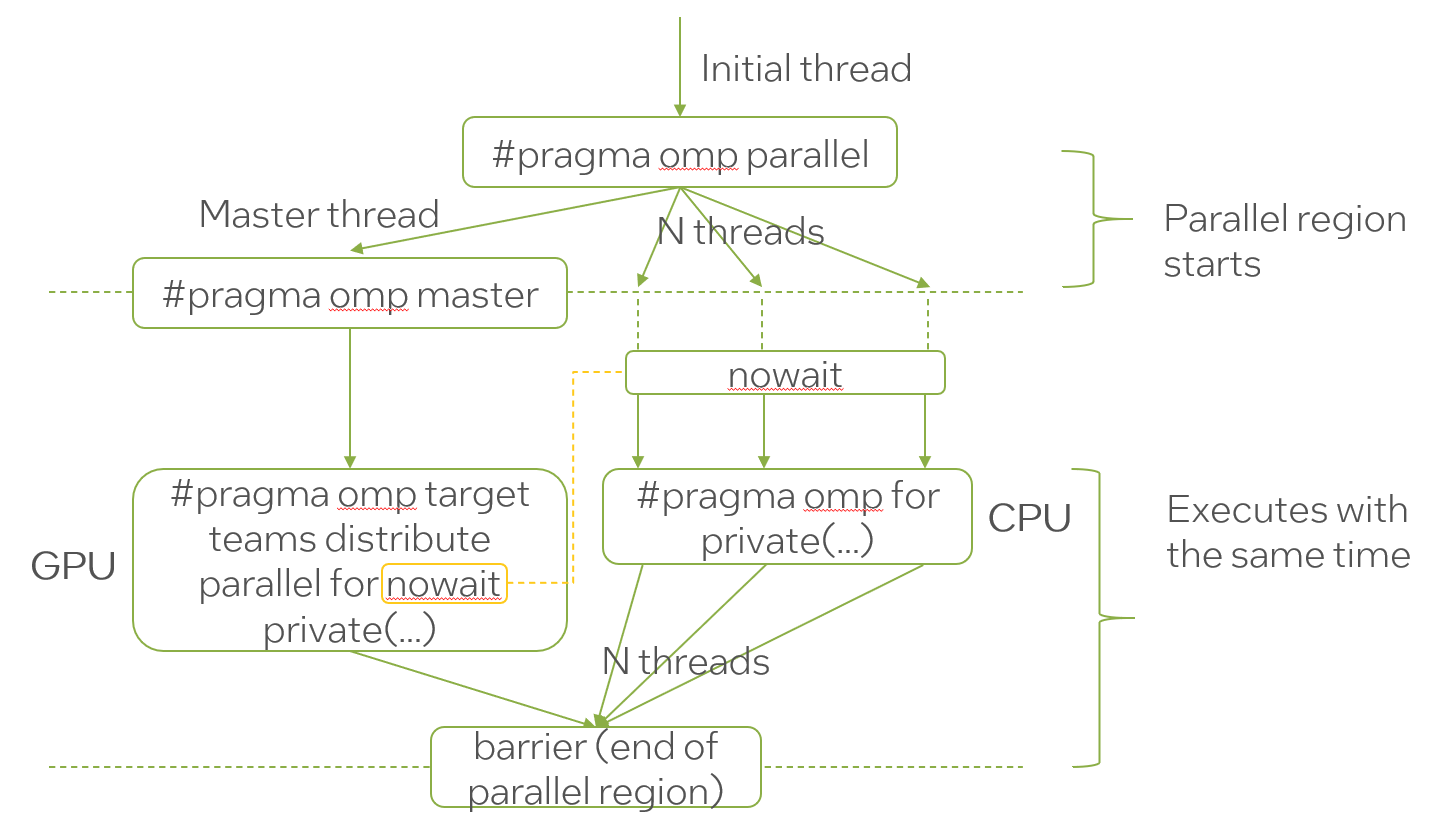
Figure 2. OpenMP parallelization scheme to keep the CPU and GPU busy
Balancing the work distribution between the CPU and GPU is regulated by the part variable that is read from STDIN (Figure 3). This variable is the percentage of the workload that will be offloaded to the GPU multiplied by numX. The remaining work will be done on the CPU. An example of the OpenMP heterogeneous parallel implementation is shown in Figure 4.
float part;
char *end;
part = strtof(argv[2], &end);
int TILE_SIZE = numX*part;
Qrc = (float*) memalign(alignment, numX, * sizeof (float));
Qrg = (float*) memalign(alignment, TILE_SIZE, * sizeof (float));
Figure 3. The coefficient of distribution work between the CPU and GPU
#pragma omp parallel
{
#pragma omp master
#pragma omp target teams distribute parallel for nowait private (expАrg, cosArg, sinArg)
for (indexX = 0; indexX < TILE_SIZE; indexX++) {
float QrSum = 0.0;
float QiSum = 0.0;
#pragma omp simd private (expАrg, cosArg, sinArg) reduction(+: Orsum, QiSum)
for (indexK = 0; indexk_< numK; indexK++) {
expАrg = PIX2 * (GkVals[indexk].kx * xg[indexX] + GkVals[index]. Ky * yg[indexX] + GkVals[index].kz * zg[indexX]);
cosArg = cosf(expArg);
sinArg = sinf(expArg);
float phi = GkVals[indexk]. PhiMag;
Q-Sum += phi * cosArg; Qisum += phi * sinArg;
}
Qrg[indexX] += QrSum;
Qig[indexX] += QiSum;
}
#pragma omp for private(expАrg, cosArg, sinArg)
for (indexX = TILE_SIZE; indexX < numk; indexX++) {
float Qrsum = 0.0;
float QiSum = 0.0;
#pragma omp simd private (expАrg, cosArg, sinArg) reduction(+: Orsum, QiSum)
for (indexK = 0; indexk < numk; indexK++) {
expАrg = PIX2 * (ckVals[indexk].kx * xc[indexX] + CkVals[index]. Ky * yc[indexX] + CkVals[indexK] .kz * zc[indexX]);
cosArg = cosf(expArg);
sinArg = sinf(expArg);
float phi = CkVals[indexk].PhiMag;
Qrsum += phi * cosArg;
Qisum += phi * sinArg;
}
Qrc[indexX] += QrSum;
Qic[indexX] += QiSum;
}
}
Figure 4. Example code illustrating the OpenMP implementation that simultaneously utilizes the CPU and GPU
The Intel® oneAPI DPC++/C++ Compiler was used with following command-line options:
‑O3 ‑Ofast ‑xCORE‑AVX512 ‑mprefer‑vector‑width=512 ‑ffast‑math
‑qopt‑multiple‑gather‑scatter‑by‑shuffles ‑fimf‑precision=low
‑fiopenmp ‑fopenmp‑targets=spir64="‑fp‑model=precise"
Table 1 shows the performance for different CPU to GPU work ratios (i.e., the part variable described above). For our system and workload, an offload ratio of 0.65 gives the best load balance between the CPU and GPU, and hence the best utilization of processor resources. The profile from Intel VTune Profiler shows that work is more evenly distributed between the CPU and GPU, and that both processors are being effectively utilized (Figure 5). While “OMP Primary Thread” submits the offloaded kernel (main: 237) for execution on the GPU, other “OMP Worker Threads” are active on the CPU.
| Offload part | Total time, s | GPU time, s |
|---|---|---|
| 0.00 | 61.2 | 0.0 |
| 0.20 | 51.6 | 8.6 |
| 0.40 | 41.0 | 16.8 |
| 0.60 | 31.5 | 24.7 |
| 0.65 | 28.9 | 26.7 |
| 0.80 | 34.8 | 32.6 |
| 1.00 | 43.4 | 40.7 |
Table 1. Hotspot times corresponding to different amounts of offloaded work (i.e., the part variable)
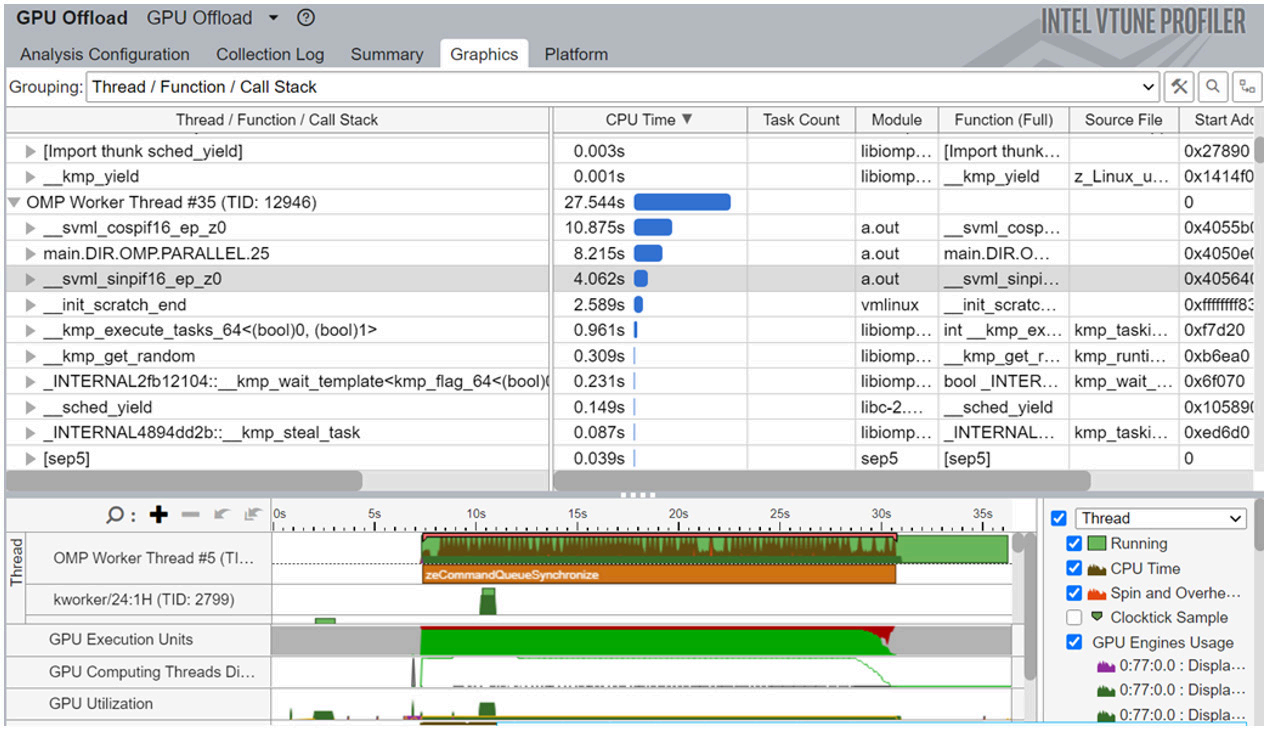
Figure 5. Profile of code with 65% GPU offload
Figure 6 shows the run times for different values of part. Keep in mind that a part of zero means that no work is offloaded to the GPU. A part of one means that all work is offloaded. It’s clear that a balanced distribution of work across the CPU and GPU gives better performance than either extreme.
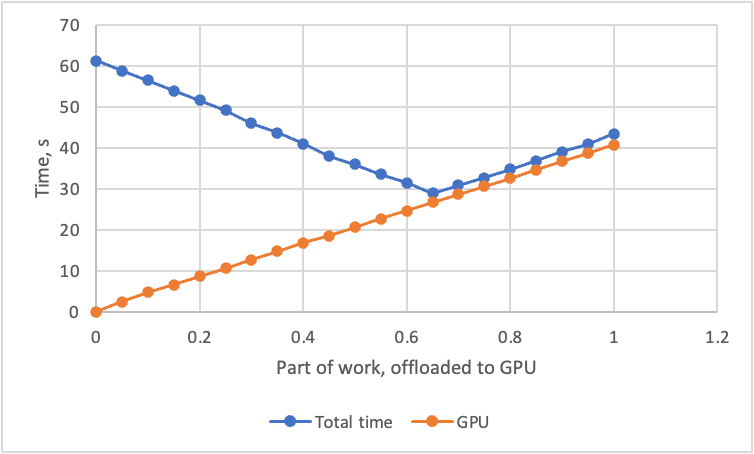
FIgure 6. Comparing training and prediction performance (all times in seconds)
OpenMP provides true asynchronous, heterogeneous execution on CPU+GPU systems. It’s clear from our timing results and VTune profiles that keeping the CPU and GPU busy in the OpenMP parallel region gives the best performance. We encourage you to try this approach.